GCDance: Genre-Controlled 3D Full Body Dance Generation Driven By Music
Generating high-quality full-body dance sequences from music is a challenging task as it requires strict adherence to genre-specific choreography. Moreover, the generated sequences must be both physically realistic and precisely synchronized with the beats
arxiv.org
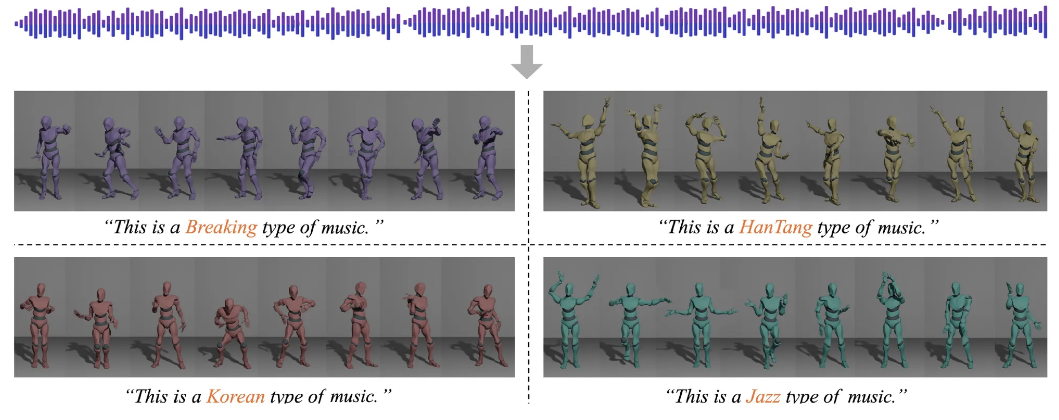
Abstract
고퀄리티의 full-body dance sequence를 음악으로부터 생성하는 것은 어려운 task이다. 그 이유는 이 task가 genre-specific choreography에 엄격한 준수를 요구하기 때문이다. 게다가 생성된 sequence들은 물리학적으로 그럴듯 해야 하고 music의 beat와 rhythm에도 정확하게 synchronize되어야 한다.
이러한 문제점들을 극복하기 위해 GCDance를 제안하게 되었다고 한다.
GCDance, a classifier-free diffusion framework for generating genre-specific dance motions conditioned on both music and textual prompts.
Genre controllability를 달성하기 위해 CLIP [Contrastive Language Image Pretraining]을 사용해서 genre-based text prompt를 매 timestep마다 embedding 하였다고 한다. 이를 통해 GCDance는 같은 music에 대해서 rhythm과 melody 와의 coherence를 유지하면서 다양한 dance style을 생성할 수 있게 되었다고 한다.
본 논문을 들어가기에 앞서, 이전 posting "DiffDance"와 더불어 Wav2CLIP, MotionCLIP 같은 Contrastive Learning based method에 대해 짚고 넘어가는 것이 좋을 것 같다.
[논문] DiffDance: Cascaded Human Motion Diffusion Model for Dance Generation
DiffDance: Cascaded Human Motion Diffusion Model for Dance GenerationWhen hearing music, it is natural for people to dance to its rhythm. Automatic dance generation, however, is a challenging task due to the physical constraints of human motion and rhythmi
phj6724.tistory.com
Contrastive Learning
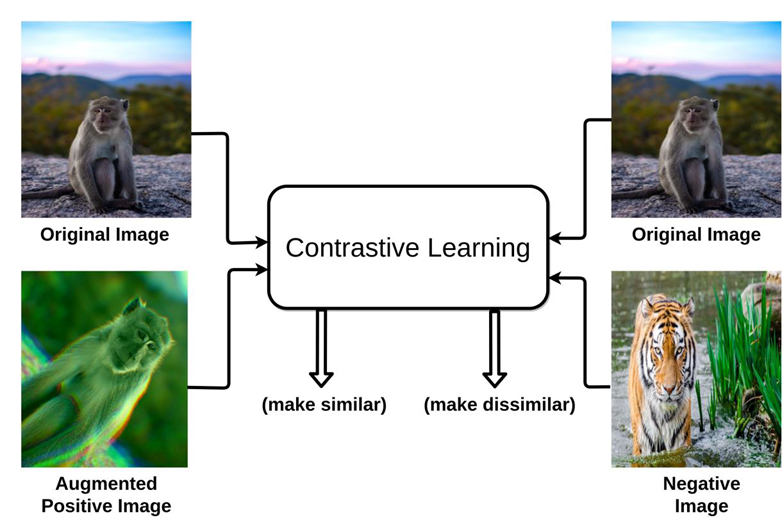
Contrastive Learning은 self-supervised learning에서 특히 널리 사용된다. 이 방식은 데이터 간의 쌍 [pairwise] 관계에 주목하여 모델이 유사한 것은 가깝게, 다른 것은 멀게 임베딩 공간에서 분리하도록 학습을 한다.
즉, 같은 이미지를 약간 다르게 변형한 두 샘플은 feature space에서 가깝게 만들고, 다른 이미지를 변형한 경우는 멀리 떨어지도록 모델이 스스로 구분하도록 학습하는 방식을 contrastive learning이라고 한다.

Augmentation에는 일부를 자르는 crop, 이미지 자체를 회전시키거나 noise를 주는 방법 등이 있다. 이러한 방식으로 augmentation을 진행하게 되면 일부의 이미지 만으로 많은 양의 dataset을 만들 수 있다.
Augmentation을 하게 될 경우 다음의 장점이 있다.
- Self-supervised signal을 생성할 수 있다. [라벨 없이도 학습 가능]
- Overfitting을 방지하고 일반화 성능을 높일 수 있다.
- 하나의 이미지만으로도 다양한 변형을 생성하여 데이터 수를 증폭시킬 수 있다.

여기까지가 간단한 contrastive learning에 대한 설명이고, 이제 DiffDance와 GCDance에서 사용되는 Wav2CLIP과 MotionCLIP에 대해 설명하도록 하겠다.
Wav2CLIP

Wav2CLIP은 별도의 텍스트 레이블 없이 오디오만을 활용하여, CLIP 모델의 멀티모달 임베딩 공간에 오디오 표현을 align시키는 self-supervised 학습 방법이다. 웹에서 수집한 비디오에서 프레임은 CLIP의 이미지 인코더 [frozen]로, 오디오는 학습 가능한 오디오 인코더로 각각 임베딩을 얻고, 이 둘을 contrastive learning을 통해 같은 비디오 내에서는 가까이, 다른 비디오 간에는 멀어지도록 학습한다. 이 방식은 CLIP의 표현력을 오디오 도메인까지 확장시켜, 별도의 텍스트 없이도 오디오-이미지, 오디오-텍스트 간 멀티모달 응용이 가능하게 하는 모델이라고 보면 된다.
MotionCLIP

MotionCLIP은 사람의 3D 모션 데이터를 CLIP의 멀티모달 임베딩 공간과 정렬시키는 self-supervised 학습 방식이다. CLIP의 텍스트 및 이미지 인코더는 frozen 상태로 유지하고, 모션 시퀀스를 MotionCLIP 전용 인코더를 통해 임베딩한 후, 이를 CLIP의 이미지/텍스트 임베딩과 contrastive loss로 정렬시킨다. 이렇게 학습된 모션 임베딩은 "walk", "run", "dance" 같은 텍스트 표현들과 공통 임베딩 공간에서 의미적으로 가까워지며, zero-shot 동작 분류나 텍스트-모션 검색 등 다양한 멀티모달 응용이 가능해지게 된다. 결론적으로 MotionCLIP은 비디오나 텍스트 없이도 모션 데이터를 자연언어와 연결하는 bridge 역할을 수행하는 model이라고 보면 된다.
여기까지가 간단하게 설명한 CLIP based multimodal model에 대한 설명이다. 다시 GCDance 모델로 돌아오면,
Introduction
Dancing은 사람들 간의 감정적인 표현 방식 관점에서 중요한 매개체 중 하나이다. 하지만 Choreography는 보다 전문적인 skill이 요구되기 때문에 professional foundation에 의존한다. Dance composition 과정에서 안무가의 몸의 움직임은 musical beat에 맞춰져야 하고 music의 장르마다 synchronize되어야 한다. 결과적으로 music-driven choreography에 AI를 이용하는 것은 상당한 연구 포텐셜이 존재한다고 주장한다.
최근, deep learning 기법들은 dance generation 분야에 적용이 되어 왔다. 하지만, 이 방식들 대부분은 dance generation을 “matching”이나 “retrieval”의 문제로 여긴다. 예를 들어, 과거의 dance movement를 기반으로 미래의 dance movement를 예측한다던지…그러나 이 방식들은 종종 long-term generation으로 가게 되면 motion freezing 현상이 발생한다. Bailando 같은 모델들은 VQ-VAE를 사용하여 codebook을 생성하고 이를 통해 dance movement를 생성하는데, codebook을 사용하게 되면 codebook 내에 정해져 있는 모션에 의존도가 매우 높아서 다양성과 창의성이 떨어지게 된다는 단점이 존재했다.
최근 들어서는 diffusion model의 영향력이 상당히 높아지면서 dance sequence 생서에도 diffusion이 사용되기 시작했다. 하지만, diffusion based method의 경우 genre 정보를 결합하지 않기 때문에 주어진 music의 일부만을 갖고서는 하나의 dance만 생성이 가능했다. 실제로는 같은 장르 내의 음악은 다양한 스타일의 dance에 대한 영감을 제공한다. 그렇기 때문에 diffusion만을 사용하는 것은 다양성을 제한하게 된다.
그래서 rhythm과 sync가 맞으면서 다양한 dance style을 생성하는 것은 표현력을 강화하고 dance generation의 다양성을 높이기 위한 과제가 되었다. 또한 이 방식들은 24개의 joint만을 갖고 있는 dataset으로 학습을 하기 때문에 미세한 손의 움직임을 고려하지 않아서 realism과 expressiveness가 떨어진다.
Music-driven dance generation은 얼마나 잘 음악의 feature를 뽑아내는지도 중요하다. 대부분의 경우 Mel-Frequency Cepstral Coefficient [MFCC]나 chroma, one-hot beat features 같은 music과 dance movement 간의 내제적 연결고리를 완전히 포착하지 않는 hand-crafted musical feature들에 의존한다.

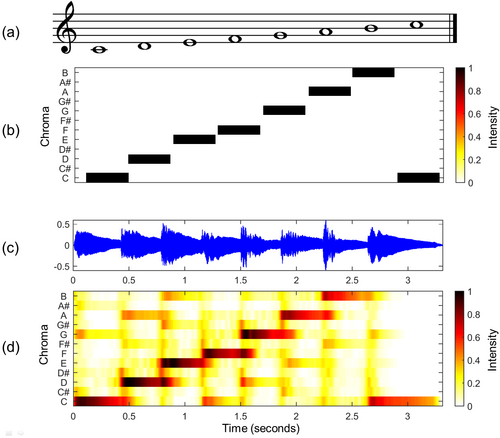
대조적으로, 최근의 music foundation model들은 현대의 machine learning 기법들이 음악을 정교한 방식으로 다루고 더 잘 이해할 수 있는 잠재력을 증명했다. Music foundation model의 잠재력은 완전히 탐구되지는 않았기 때문에 이 모델들이 어떻게 dance generation task의 quality와 expressiveness를 향상시켜줄 지에 대한 조사가 진행되고 있다고 한다.
본 논문에서는 music과 text prompt에 conditioning된 transformer-based diffusion model을 사용한 GCDance를 제안해서 다양한 dance segment들을 생성하는 것에 초점을 두었다. Music feature representation의 한계점을 해결하기 위해 STFT audio feature [handcrafted]과 Wav2CLIP [music foundation model]에서 얻은 deep feature들을 결합하였고, CLIP을 활용해서 genre description으로 부터 text representation을 뽑아냈다고 한다. Wav2CLIP audio encoder가 text와 embedding space를 공유하기 때문에 이러한 방식의 alignment는 dance movement를 이끄는 획일화된 musical, genre characteristic에 대한 이해로 이끌어주어 model의 generation capability를 향상시킬 수 있다. Music과 text prompt 2개에 대해 conditioning을 받음으로써 music이 주된 driving input을, text prompt가 genre에 특정된 generation을 위한 추가적인 control을 제공하는 classifier-free diffusion framework를 사용할 수 있게 된다.
Dance style에 대한 controllability가 부족한 기존 방식들의 단점을 보완하기 위해서는 dense FiLM [Feature-wise Linear Modulation] layer를 사용해서 text에 있는 genre 정보를 기반으로 dance generation process를 modulate했다고 한다. FiLM layer는 text prompt로 부터 scaling, shifting parameter를 생성하는데 model의 중간 feature들에 적용디어 생성된 결과가 원하는 장르에 맞춰지면서 음악과 synchronize되도록 보장해주는 중요한 역할을 한다.
Contribution
- We introduce GCDance, a classifier-free diffusion-based framework for generation of multi-genre dance sequences. Our framework incorporates fusing cross-attention to generate fine-grained [52 joint] dance movements, encompassing hand gestures and body motion
- GCDance integrates music embeddings extracted from a pretrained music foundation model with hand-crafted features, effectively leveraging the advantages of high-level semantic information and low-level temporal details to improve the quality of generated dance sequences.
- GCDance achieves controllable dance generation by conditioning on both music and textual romprs. By incorporating genre specific information, the model can generate dances in specified genres, additionally supporrting localized motion editing.
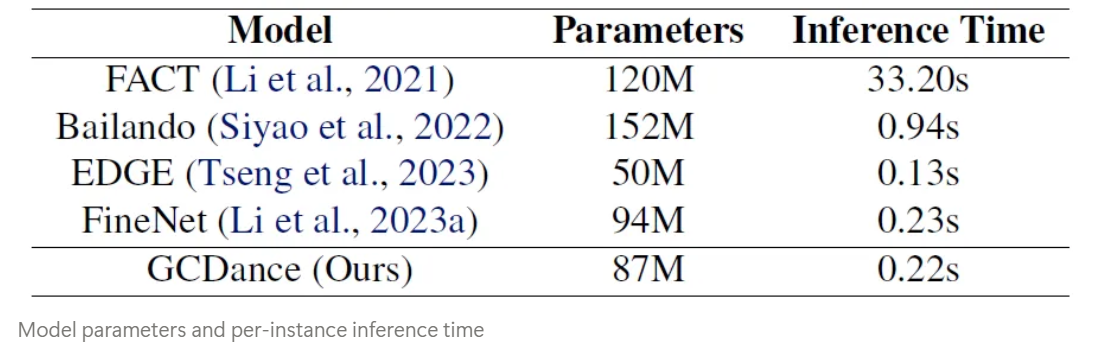
- We perform a comprehensive evaluation to assess existing approaches on the 52 joint dataset - FineDance, conducting separate evaluation for hand and body movements, consistently achieving SOTA performance across metrics. Our ablation test, inference time analysis, and additional results on the 24-joint AIST++ dataset, confirm that GCDance provides an effective solution to music driven dance generation
Proposed Method

The goal of our method is to generate genre-specific dance sequences conditioned on both music sequences and textual descriptions
Long music piece가 주어지면, 먼저 N개의 segment로 나누고 각각의 segment에 대해 k개의 sample을 추출한다. 이 각각의 sample들은 feature vector의 형태이며 feature matrix를 형성한다. 동시에 text feature vector를 뽑아내어 genre-controlled dance generation을 실행한다.
Preliminaries of Diffusion Models
본 논문에서는 dance generation을 하기 위해 diffusion-based model을 사용하는데, diffusion process와 reverse process로 구성이 되어 있다.
Diffusion process에서 DDPM에서 설명된 방식을 차용해서 ground truth에서 점점 gaussian noise를 주입해 가며 Markov chain을 형성한다.

Pose Representations
Motion representation을 위해서는 SMPL format에 따라 3개의 component를 구성했다고 한다.
- Human joint positions : 6DOF rotation representation을 사용해서 52개의 joint position을 312 차원의 공간으로 변환하여 표현했다고 한다.
- Root translation : 3차원 vector가 root joint의 global translation을 설명하기 위해 사용된다.
- Foot-ground contact : EDGE에서의 방식을 따라서 주어진 f에 대해 4차원의 foot-ground contact label을 합쳐서 발의 뒷꿈치, 앞꿈치가 각각의 발에 대해 지면과 접촉하고 있는지를 binary state로 표현하고자 하였다.
Conditional Generation
Music Representations
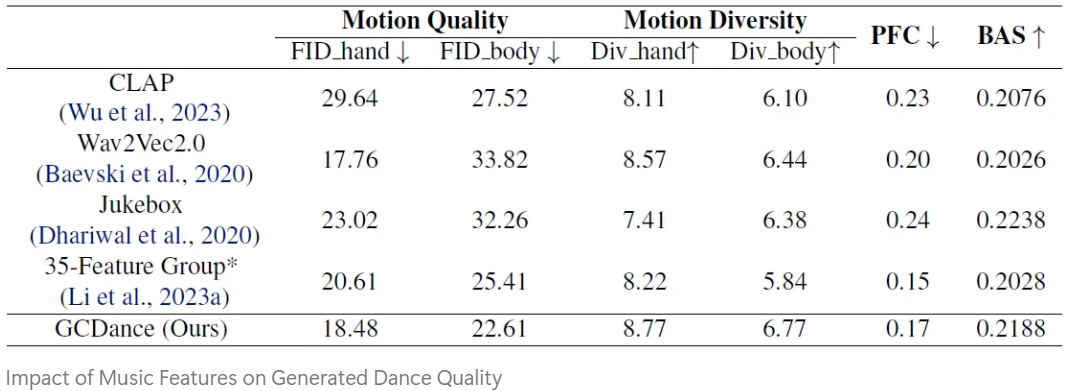
기존의 방식들은 보통 music feature representation의 중요성을 무시한다. 이를 해결하기 위해 CLIP framework에서 audio-visual correspondence를 얻는 Wav2CLIP을 music encoder로 사용하였다고 한다.
구체적으로, 이 과정은 CLIP vision model을 freezing 시켜서 video로 부터 visual stream을 다루는 과정에 의해 진행된다. Handcrafted music feature에 대해 STFT를 적용해서 short time window 내의 frequency 정보를 포착하였다.
본 논문의 접근 방식에서는 Librosa를 사용해서 STFT를 뽑아내었다고 한다.
Text Representations
Music genre labeling을 위해 prompt learning method를 적용해서 label을 완전한 sentence로 확장하고자 하였다. 예를 들어, “Jazz”라는 genre label이 주어지면, 생성된 sentence는 “This is a Jazz type of music”이 출력되게 된다. 그 뒤 CLIP을 사용해서 이 문장에서 feature를 뽑아내게 된다.
하지만, conditional feature와 dance motion 간의 domain gap은 여전히 존재하기 때문에 이 gap을 연결해주기 위해 adapter module을 사용해서 뽑아낸 music과 text representation을 처리하고 효과적으로 latent space에서 align 시켰다.
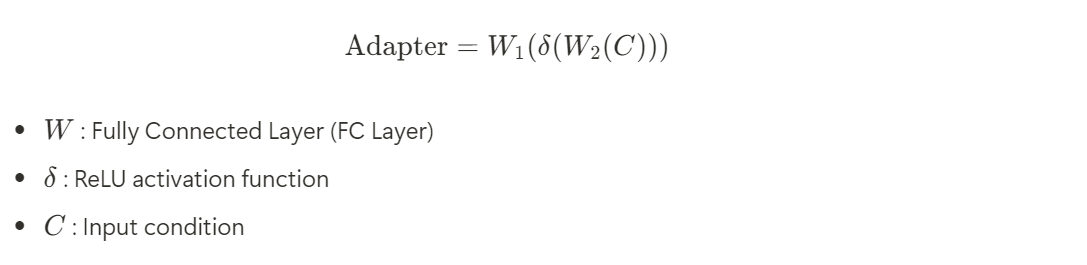
GCDance: The Proposed Framework
Architecture
GCDance의 input은 noise slide d_T, music condition C_M, text condition C_E, diffusion timestep t를 포함한다. 이 input들은 Transformer-based denoising network에 들어가게 되고 본 논문에서는 2가지 expert downsampling module을 사용해서 신체 움직임과 순 움직임의 분포를 별도로 모델링한다.
이 방식은 motion의 범위와 몸과 손의 자유도 차이에 영감을 받았다고 한다.
이들의 unique feature space를 독립적으로 학습시키기 위해 model은 향상된 detail과 표현력을 갖는 dance sequence를 생성할 수 있다록 한다. 이 과정을 정교하게 하기 위해 motion sequence들은 2개의 transformer-based network에 별도로 넣어주었다고 한다.
Transformer-based network는 self-attention module, cross-attention module, multi-layer-perceptrons, time-embedding FiLM layers로 구성되어 있다고 한다.

더하여 music conditioning inpnut을 합치기 위해 cross-attention mechanism을 사용해서 embedding space에 project된 music feature들을 다뤘다고 한다. Genre 정보는 FiLM [Feature-wise Linear Modulation]을 통해 합쳐지는데 multiplicative interaction을 통해 neural network의 output이 modulate 되고 model이 동적으로 contextual information을 기반으로 representation을 조정할 수 있게 된다고 한다.
본 논문의 모델에서는 이전 layer Y의 output과 text embedding C_E를 input으로 사용했다. Embedding은 다음과 같다.

Training Objectives
Fluent하고 physically-plausible한 motion sequence들을 생성하기 위해 EDGE나 MDM 등에서 사용 되는 여러개의 auxiliary loss들을 결합하였다고 한다. 이 auxiliary loss들은 3개의 핵심 요소에서 alignment를 촉진한다.
- Joint positions
- Velocities
- Foot contact

또한 velocity와 acceleration에 대한 loss인 velocity loss도 다음과 같이 구하였다고 한다.

마지막으로, contact loss를 구해서 motion generation 동안의 foot contact consistency를 최적화할 수 있다고 한다.

Sampling
Sampling 과정은 아래의 그림과 같다

각각의 denoising timestep t에 대해 기존에 noise term d_t를 예측함으로써 output을 복원하는 diffusion 모델과 달리 본 논문의 모델은 직접적으로 dance $\hat{m}$을 예측한다. 예측된 pose는 다시 timestep t-1에 대해 re-noised 된다.

이 과정을 t가 0이 될 때까지 반복한다고 한다.
Editing

이전의 method들에 기반해서 본 논문의 접근 방식은 diffusion inpainting 기법을 결합해서 다양성을 향상시켰다. User들은 temporal domain에서 움직임들 사이에 생성을 하거나 spatial domain에서 특정 관절 부분들을 편집하기 위한 condition을 특정할 수 있다. 이 방식에 따라 본 논문은 tailored dance outcome들을 생성하여 생성된 dance sequence에 대해 fine-grained control을 제공해준다. 이 과정은 sampling 과정에서만 발생하고 training 과정에는 포함되지 않는다.

Experiments
Datasets
SOCIAL MEDIA TITLE TAG
SOCIAL MEDIA DESCRIPTION TAG TAG
li-ronghui.github.io
GitHub - li-ronghui/FineDance: FineDance: A Fine-grained Choreography Dataset for 3D Full Body Dance Generation. (ICCV2023)
FineDance: A Fine-grained Choreography Dataset for 3D Full Body Dance Generation. (ICCV2023) - li-ronghui/FineDance
github.com
FineDance Dataset을 주로 사용했다고 한다.
- 7.7 hours of paired music and dance
- 831,600 frames at 30 fps across 16 genres
- Average dance length = 152.3 sec
- Skeletal data of FineDance is stored in a 3D space and is represented by the standard 52 joints, including the finger joints
⇒ Train all the methods on the 183 pieces of music from the training set and generate 270 dance clips across 18 songs from the test set, using the corresponding real dances as ground truth
Implementation details
- NVIDIA GeForce RTX 3090 2장
- Adam Optimizer with learning rate 2e-4 and optimize the model using the L2 loss function
- Batch size : 512
- Training epoch : 2000
- Hidden dimension : 512
- All training segments of the music-dance data are uniformly divided into fixed durations of 120 frames, corresponding to 4 seconds at 30 frames per second [FPS]
- During inference, guidance weight = 2.7
Evaluation Method
Motion Quality
FID score를 사용했다고 한다.
→ Measures the dissimilarity between the feature distributions of generated dance sequences and ground truth dance sequences by computing the distribution distance in the feature space
Generation Diversity
Motion-Music Correlation
Beat Alignment Score를 사용했다고 한다.
→ Assesses the correlation between motion and music by calculating the average temporal distance between each kinematic beat and its nearest musical beat
Physical Plausibility
EDGE에서 제안된 Physical Foot Contact [PFC]를 사용한다고 한다.
Qualitative Results
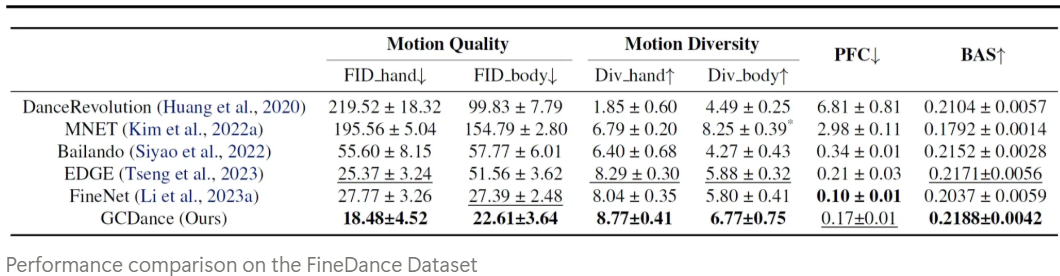

Quantitative Results

Ablation Studies

User Study
Model Efficiency
Conclusion
Our approach enables genre-controllable dance generation by integrating genre information, allowing for the synthesis of dance motions that align with specified genres while maintaining diversity and high quality