
EDGE: Editable Dance Generation from Music
EDGE: Editable Dance Generation from Music, 2022.
edge-dance.github.io
EDGE: Editable Dance Generation From Music
Dance is an important human art form, but creating new dances can be difficult and time-consuming. In this work, we introduce Editable Dance GEneration , a state-of-the-art method for editable dance generation that is capable of creating realistic, p
arxiv.org
들어가기에 앞서, Music-to-Dance task에 대해 간단히 설명을 하자면,
Music과 Image 또는 사람의 initial position [pose]를 input으로 사용해서 Transformer나 VQ-VAE, Diffusion 등 여러 모델들을 이용하여 음악에 어울리는 댄스 모션을 생성하는 분야이다.
그렇기 때문에 음악의 feature를 잘 분석하는 것이 중요하고 분석한 음악의 context나 가사 등을 활용하여 적절한 안무를 취하도록 3D human model을 움직이게 하는 것이 궁극적인 목표이다.
이 task를 보면 그런 생각이 들 수 있다.
이런걸 왜하는거지?
충분히 이해가 된다. 나 역시 그렇게 생각했었으니까. 그런데 잠깐 생각을 해보면 손쉽게 활용할 수 있는 분야를 찾을 수 있다. Just Dance 게임만 봐도 특정 캐릭터가 노래에 맞춰 춤을 추고 있는 것을 볼 수 있다.
그리고 실제로 사용할지는 모르겠지만 대학생들이 Chat-GPT를 이용해서 과제 해결에 도움을 받는 것 처럼 안무가들 역시 Music-to-Dance model을 이용하여 안무 창작에 도움을 받을 수도 있을 것이다.
또한 애니메이션에서 캐릭터가 춤을 추게 하고 싶을 때 blender 같은 tool에 의존하지 않게 되어 시간 측면에서 상당한 메리트가 있을 것이다. 이를 좀 더 파해쳐 보고자 여러 논문들 중 2023 CVPR에 accept된 EDGE라는 논문을 review하고자 한다.
Abstract
Editable Dance GEneration [EDGE]: Capable of creating realisic, physically-plausiable dances while remaining faithful to the input music
본 논문에서는 Editable한 Music-to-Dance model을 다룬다. 이 모델의 핵심 method는 다음 4가지이며, 뒤쪽에서 더 자세히 설명하도록 하겠다.
1. Transformer-based diffusion model paired with Jukebox
2. Joint-wise Conditioning

3. In-betweening
4. Long-form Sampling
Introduction
새로운 dance나 dance animation을 만드는 것은 dance movement가 표현력이 높고 자유로운 형태에다가 음악에 잘 맞춰져야 하기 때문에 어려운 task이다. 그렇기 때문에 이 과정이 상당한 수작업과 motion capture system이 필요했었고 그로 인해 값 비싼 장비에 의존해야 하고 실용적이지 못했다.
이에 반해 computational method는 dance를 자동으로 생성해서 위 과정에서의 부담감을 상당히 낮출 수 있었다.
본 논문에서는 Editable Dance GEneration [EDGE]를 통해 현실적이고 신체학적으로 가능한 dance motion을 input music에 맞춰 생성을 하는 모델을 제안했다. EDGE에서는 Jukebox와 paring한 transformer-based diffusion model이 사용되어 강력한 editing 능력이 부여되었다.
Contribution
- We introduce a diffusion-based approach for dance generation that combines SOTA performance with powerful editing capabilities and is able to generate arbitrarily long sequence
- We analyze the metrics proposed in previous works and show that they do not accurately represent human-evaluated quality as reported by a large user study
- We propose a new approach to eliminating foot-sliding physical implausibilities in generated motions using a novel Contact Consistency Loss, and introduce Physical Foot Contact Score, a simple new acceleration based quantitative metric for scoring physical plausibility of generated kinematic motions that requires no explicit physical modeling.
- We improve on previous hand-crafted audio feature extraction strategies by leveraging music audio representations from Jukebox, a pre-trained generative model for music that has previously demonstrated strong performance on music-specific prediction tasks
Method
Pose Representation
본 연구에서는 dance를 24-joint SMPL format에서 6-DoF rotation을 모든 관절에 사용한 pose들의 sequence로 표현을 했다.
발뒷꿈치와 앞꿈치의 경우 binary contact label b를 추가해서 최종적인 pose representation을 구성했다고 한다.
EDGE는 주어진 임의의 음악 c에 대해 N개의 frame들의 sequence를 synthesize하는 것을 학습하기 위해 diffusion-based framework를 사용했다.

Diffusion Framework

Auxiliary losses

Sampling and Guidance

Editing

EDGE에 의해 생성된 dance들을 editing할 수 있도록 하기 위해 diffusion image inpainting에서 masked denoising 기법을 가져와서 사용을 했다고 한다.
EDGE는 어떠한 temporal, joint-wise constrant들을 지원한다고 한다.

결과적으로 N개의 frame sequence가 나오게 되는데 첫번째와 마지막 n개의 frame은 reference motion으로 부터 제공된 motion이고 나머지 부분이 그럴듯한 “in-between” dance로 채워지게 된다.
Long-form Sampling
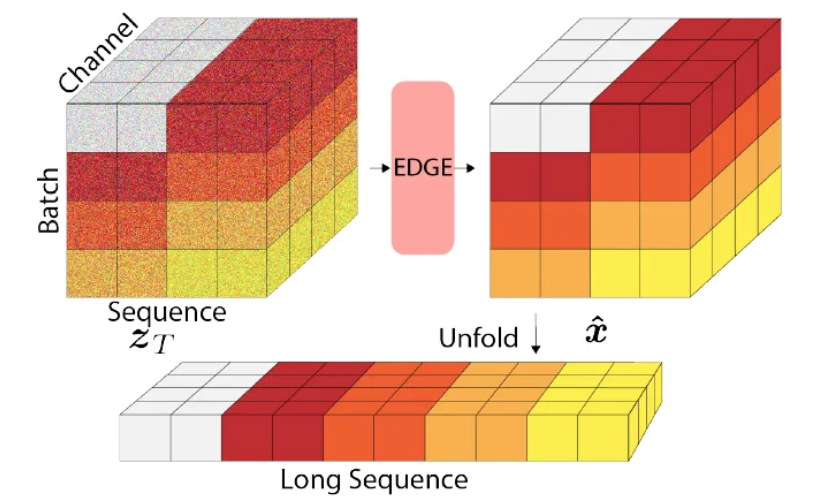
임의의 길이의 sequence 들을 합성하는 능력은 오랜 시간이 걸리긴 하지만 dance generation에서는 빼놓을 수 없는 작업이다. EDGE가 한번에 모든 dance sequence의 frame을 생성하긴하지만 naive하게 생각해보면 최대의 sequence 길이는 computational cost가 linear하게 증가하게 된다. 또한 dance generation은 conditioning c가 motion sequence와 길이가 일치해야 하기 때문에 memory 필요량도 충분해야하는데 Jukebox 같은 큰 모델들에게는 치명적일 수 밖에없다.
이를 해결하기 위해 EDGE는 Jukebox의 editing 능력을 leverage해서 여러 sequence들의 temporal consistency를 강화하고자 했고, 하나의 긴 sequence로 결합될 수 있었다고 한다.
Model
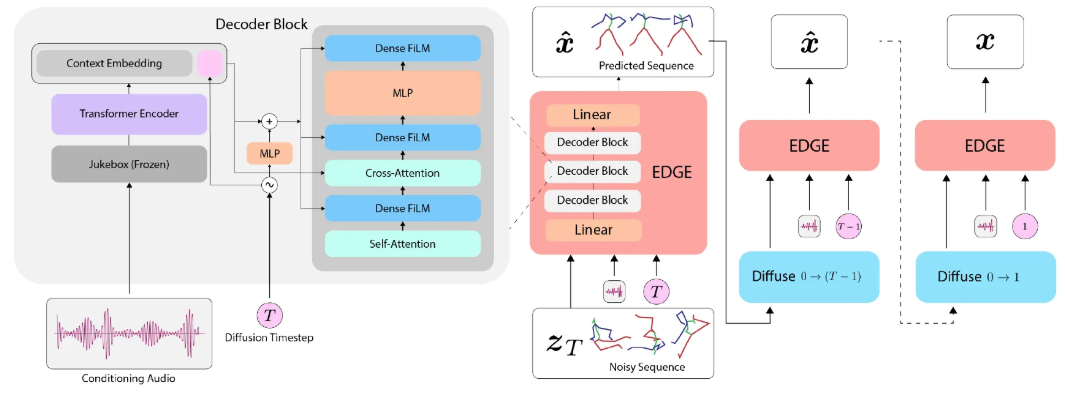
Transformer decoder architecture를 채택해서 music conditioning이 transformer의 차원으로 project되도록 처리하고 cross-attention mechanism을 적용했다고 한다. Timestep 정보는 music conditioning, feature-wise linear modulation [FiLM]과 token이 결합된 형태로 존재하고 있다고 한다.
Music Audio Features
이전의 연구들은 주로 dance generation에서의 generative modeling의 성능을 높이는 것에 초점을 두었고 music signal 자체에는 그닥 관심이 없었다. 본 논문의 저자들은 이것의 중요성을 주장하면서 text encoder의 scaling이 diffusion model을 scaling 하는 것보다 성능 측면에서 더 중요하다고 말하고 있다.
같은 맥락에서 music information retrieval 분야의 최근 연구들을 보면 raw music audio를 생성하기 위해 1M개의 노래들로 학습을 시킨 large GPT-style model인 Jukebox는 music audio prediction task를 위한 강력한 feature들을 제공한다. 이 점에서 영감을 받아서 diffusion model의 conditioning input으로 Jukebox feature들을 제공하는 것을 채택했다고 한다.
또한 memory 효율적인 구현을통해 하나의 GPU로 거의 real-time extraction이 가능하도록 했다고 한다.
Experiments
Dataset
AIST++를 사용했고 원본 dataset에서 제공된 train/test split을 재사용했다고 한다.
Baselines
- FACT : Autoregressive model introduced together with the AIST++ dataset
- Bailando : Follow-up approach that achieves the strongest qualitative performance to date
Comparison to Existing Methods
Human Evaluation
임의의 147명의 평가단에게 무작위로 11,610개의 clip들을 평가하도록 한 결과 EDGE가 이전 모델들 보다 더 선호도가 높았다는 것을 확인할 수 있었다고 한다.
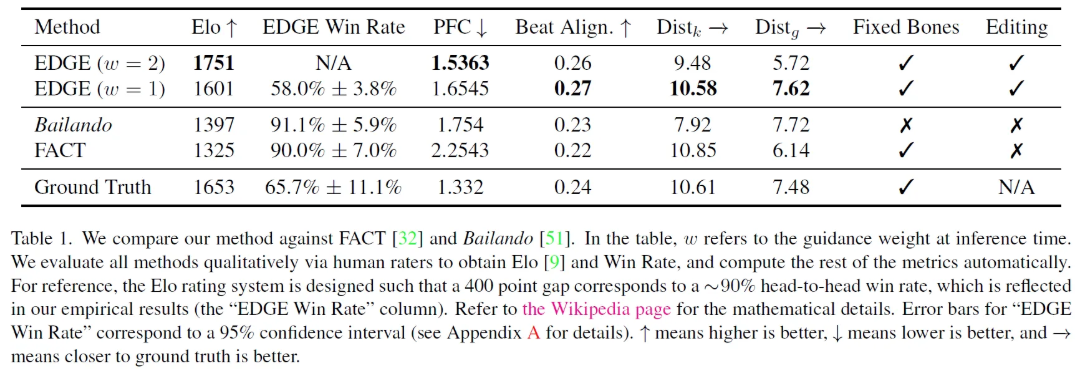
Physical Plausibility
이전의 연구들은 foot-ground contact를 foot sliding을 측정함으로써 평가했다. 하지만, dance는 독창적인 분야이기 때문에 sliding으로 평가를하는 것은 흔하기도 하고 많은 안무에 중추적인 역할을 한다. 이러한 점이 새로운 metric의 필요성을 느끼게 해였고 본 논문에서 Physical Foot Contact Score [PFC]를 제안하게 된 계기가 되었다.
PFC is a physically-inspired metric that requires no explicit pysical modeling
- On the horizontal [xy] plane, any center of mass [COM] acceleration must be due to static contact between the feet and the ground. Therefore, either at least one foot is stationary on the ground or the COM is not accelerating
: Center of Mass가 가속화 되려면 반드시 발과 지면 사이의 마찰이 있어야 한다. 즉, 적어도 한 발이 지면에 고정되어 있거나 COM이 가속되지 않고 있는 경우에만 이 조건이 충족된다. 만약 두 발이 모두 떠 있다면, 지면을 통한 가속이 불가능하므로 COM이 가속될 수 없다. - On the vertical [z] axis, any positive COM acceleration must be due to static foot contact
: Center of Mass가 위쪽 방향으로 가속되려면 반드시 정지 마찰을 이용한 발의 접촉이 있어야 한다. 즉, 지면을 밀어 올리는 힘 [ground reaction force]이 필요하다. 만약, 두 발이 모두 지면에서 떨어져 있다면, 중력 외에 추가적인 위쪽 가속을 발생시킬 수 있는 힘이 없으므로 COM은 자유 낙하 하게 된다.
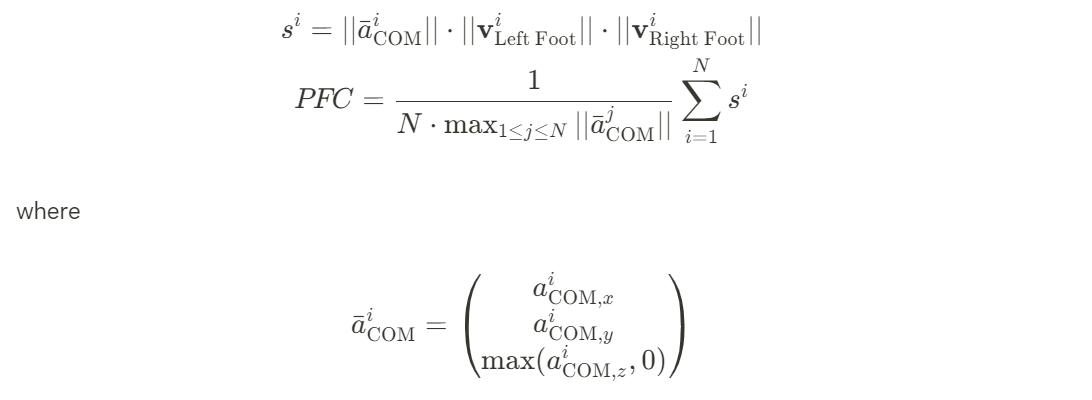
고정된 뼈 길이를 유지하는 것은 physical plausibility의 측면에서 또 하나의 중요한 부분이라고 한다. Bailando 같이 joint Caretsian space에서 동작하는 방식들의 경우 상당히 다양한 뼈의 길이가 나타날 수 있다. 하지만, EDGE의 경우는 축소된 coordinate [joint angle] space에서 동작하기 때문에 고정된 뼈의 길이를 보장한다.
Beat Alignment Scores
본 연구를 통해 생성된 dance가 음악의 beat와 잘 맞아떨어지는지를 확인하기 위해 Beat Alignment Score를 적용했다고 한다.
Diversity
Diversity metrics are computed following the methods of previous work, which measure the distributional spread of generated dances in the “kinetic” [Dist_k] and “geometric” [Dist_g] feature spaces.
In-the-wild Music
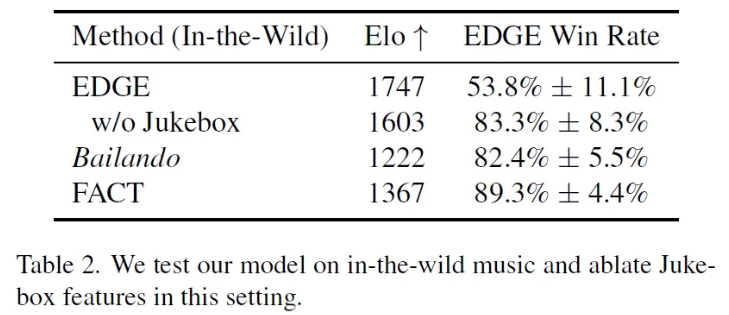
Playlist에 ITZY노래가 있는게 인상적이다
Additional Evaluation
Editing
In-betweening, Motion continuation, joint-conditioned generation, long-form generation이 가능하다.
Physical Plausibility
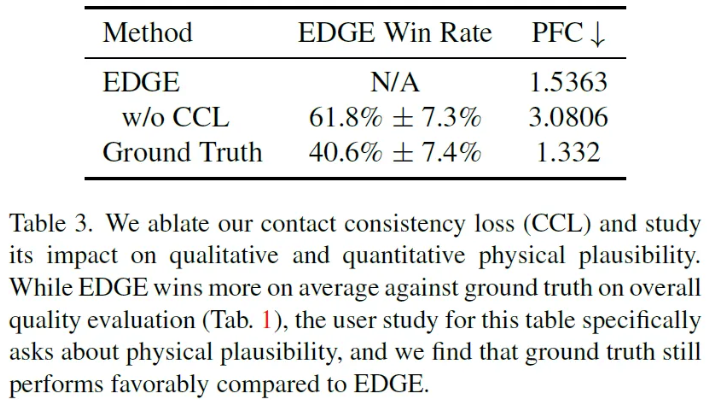
PFC와 CCL [Contact Consistency Loss]를 측정했다고 한다. Ablation으로 CCL의 유/무에 따라 결과가 어떻게 달라지는지도 확인을 해보았는데 CCL이 있을 때가 눈에 띄게 PFC metric과 정량적인 physical plausibility가 증가했다고 한다. 또한 이 결과를 통해 알 수 있는 점은 PFC가 physical plausibility에 대한 human perception을 잘 따른다는 것을 알 수 있다.
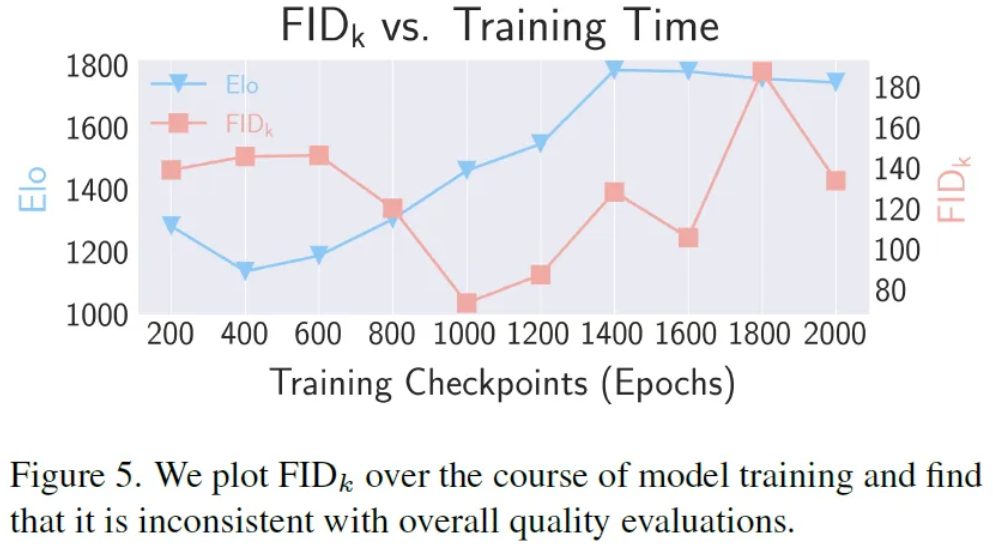
FID Results
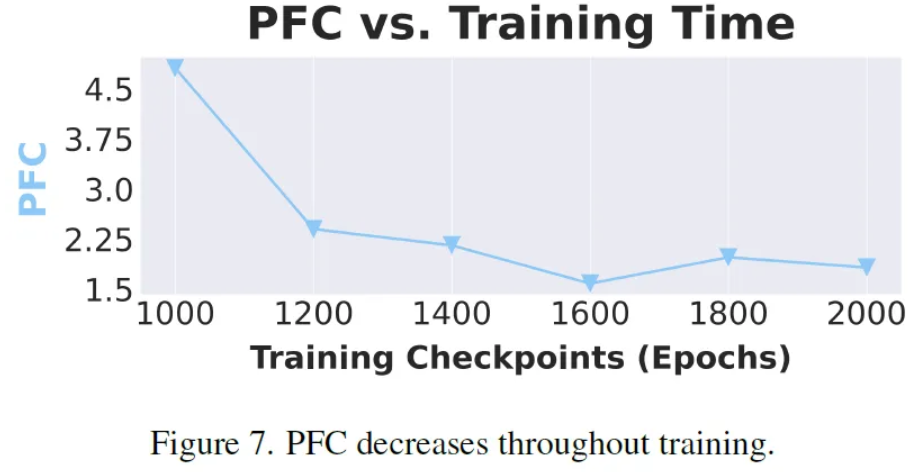
Conclusion
We propose a diffusion-based model that generated realistic and long-form dance sequences conditioned on music
- Our model admits powerful editing capabilities, allowing users to freely specify both temporal and joint-wise constraints
- Our method is able to create arbitrarily long dance sequences via the chaining of locally consistent, shorter clips, it cannot generate choreographies with very-long-term dependencies
- Editability also opens the door to the generation of more complex choreographies, including multi-person and scene-aware dance forms
'Paper Review > Music-to-Dance' 카테고리의 다른 글
| [논문] POPDG: Popular 3D Dance Generation with PopDanceSet | 2025.03.19 |
|---|---|
| [논문] Controllable Group Choreography using Contrastive Diffusion | 2025.03.14 |