
POPDG: Popular 3D Dance Generation with PopDanceSet
Generating dances that are both lifelike and well-aligned with music continues to be a challenging task in the cross-modal domain. This paper introduces PopDanceSet, the first dataset tailored to the preferences of young audiences, enabling the generation
arxiv.org
POPDG: Popular 3D Dance Generation with PopDanceSet
Zhenye Luo, Min Ren, Xuecai Hu, Yongzhen Huang, Li Yao Beijing Normal University
luke-luo1.github.io

Lifelike하고 music과 잘 align된 dance를 생성하는 것은 cross-modality domain에서는 항상 난제였었다. 이 논문에서는 PopDanceSet dataset을 소개하는데, 기존의 AIST++ dataset에 비해 music-genre diversity, dance movement의 intricacy와 depth 측면에서 성능을 능가했다고 한다. 또한 POPDG model을 iDDPM framework에서 제안해서 Space Augmentation Algorithm을 통해 dance diversity를 증가시키고 human body joint들 간의 spatial physical connection을 강화했다고 한다. 또한 streamlined Alignment Module을 추가해서 dance와 music 간의 temporal alignment를 향상시켰다고 한다. 결과적으로 이를 통해 SOTA 성능을 달성했다고 한다.
Introduction
The task of music-driven dance generation not only helps choreographers improve the efficiency of creating innovative dances but also facilitates performances by virtual characters
이 task는 수년간 dataset의 부족함과 generative model의 성능 부족에 의해 전진을 못하고 있었다.
AIST++ dataset이 이러한 문제점을 일부 해결 해주었지만, training step의 복잡함, generation의 불안정함, diversity의 부족함은 여전히 존재하고 있다.
그래서 이 논문에서는 PopDanceSet과 POPDG를 제안해서 dance generation에서의 dataset과 model의 성능 증가 두 마리 토끼를 모두 잡고자 하였다.
AIST++ dataset의 단점은 aesthetically oriented dance가 없어서 dance의 범주가 좁고 diversity가 부족하다는 점이다. 이 dataset의 dance는 street dance 10개로 분류가 되는데 실제 현실에서의 다양한 범위를 포괄하기에는 상당히 부족할 수 밖에 없다.
이 논문에서 popularity function을 통해 생성된 PopDanceSet은 popular aesthetics와 align되는 dance video를 filtering 한다. 이를 통해 aesthetically orient content 측면에서 상당한 진보를 이뤄냈고 dance type, music genre, dance movement의 diversity를 높일 수 있었다고 한다.
또한 Attention Mechanism에 기반한 space augmentation algorithm을 제안해서 dance decoder block을 만들고 dance movement에서의 joint들끼리의 spatial connection을 강화했다고 한다. 또한 streamlined alignment module이 dance의 music의 spatiotemporal feature들을 encode해서 rhythmical synchronization을 강화할 수 있었다고 한다.
Contribution
- We build the PopDanceSet, reflecting contemporary aesthetic preferences. It significantly enriches the diversity and quantity of dances and music, increases the complexity of dance movements, and offers excellent extensibility for continuous supplementation.
- We introduce POPDG[Popular 3D Dance Generation], which is based on iDDPM and achieves a balance between generation quality and diversity. The model pays particular attention to the spatial features of the dancer’s body joints, especially proposing the Space Augmentation Algorithm. In addition, our newly designed Alignment Module integrates the spatiotemporal features of music and dance, strengthening the alignment between dance and music.
- Extensive experiments were conducted in this study. It was observed that the POPDG produced the exciting results, both on AIST++ and PopDanceSet. And we also make a reasonable extension to the evaluation metrics, making the assessment of dance generation more comprehensive and objective.
PopDanceSet
Popularity Function and Dataset Construction
BiliBili라는 중국에서 청소년들에게 유행하는 video platform에서 data를 불러와서 video popularity에 영향을 주는 요소들을 여러 개의 linear regression을 통해 구해서 popularity function을 구했다고 한다.
Selecting popular dance videos
⇒ Recommendation function이 video의 view count만 고려하는 것이 아니라 다양한 요소를 고려한다는 것을 알 수 있음
Dataset description
180개의 음악이 있는 263개의 dance video를 모았다고 한다. 이 dataset에는 SMPL과 HybrIK model을 사용해서 모든 video에서 dancer들의 3D joint feature들을 뽑았다고 한다.
- 24 SMPL pose parameters along with the global scaling, translation and pred_scores
- Predicted camera parameters along with root and translation
- 17 COCO-format human joint locations in 3D
Method
본 논문의 framework는 DDIM [Denoising Diffusion Implicit Models]에 의해 denoising이 진행되는 iDDPM [improved-Denoising Diffusion Probabiliistic Models]로 sampling을 했다고 한다.
Training 동안 model은 dance pose의 sequence x를 먹여서 특정 frame의 개수만큼 spanning을 한다고 한다. 대부분의 방식들과 유사하게, 처음 3차원은 single root translation을 의미하고 SMPL human body model의 24개의 joint X 6DoF가 그 뒤를 이으며 발, 손, 목의 binary contact label까지 해서 pose가 다음과 같이 표현된다고 한다.
여기서 사용한 model은 music과 motion에 같은 importance를 준다고 한다.
EDGE처럼 Jukebox로 4800차원의 music feature들을 뽑는 것에 더해서 dance decoder와 구조적으로 대칭인 music encoder를 표현했다고 한다.
iDDPM and DDIM
DDPM framework는 action domain과 dance generation domain 두 분야 모두에서 사용된다. DDPM과 달리 iDDPM은 data distribution의 평균을 학습할 뿐만 아니라 분산까지 학습해서 quality를 보장하면서 generation의 diversity를 높였다.

하지만, 이 식은 분산을 고려하지 않는다. 그래서 iDDPM 방식을 따라서 variational lower bound loss term을 추가했다고 한다.
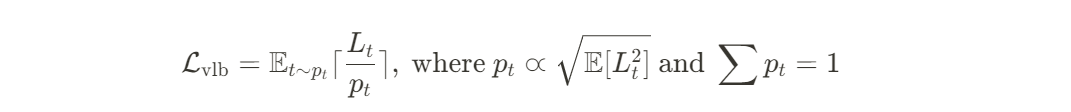
따라서 iDDPM의 total loss는 다음과 같이 된다.
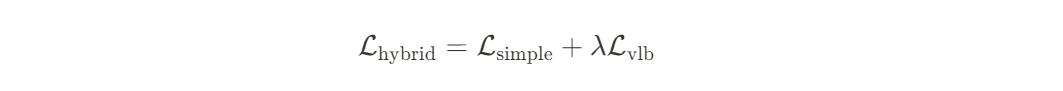
This method allows for significantly faster training and inference without much compromise on the quality of the generation
Music and Dance Spatiotemporal block
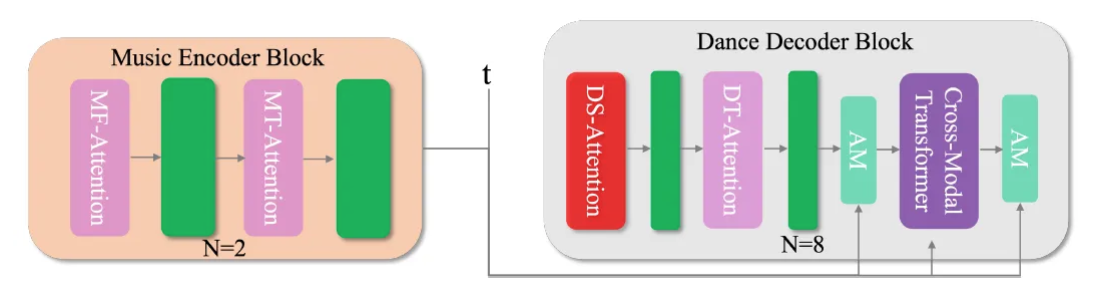
POPDG는 2개의 block [music encoder, dance encoder]으로 구성되어 있다. 이 2개의 block은 symmetry와 empirical validation의 원리에 기초해서 구성이 되어 있고, 유사한 spatiotemporal Transformer module을 갖고 있다.
- Four Attention Mechanism
- MF-Attention [Music Feature-Attention]
- MT-Attention [Music Temporal-Attention]
- DS-Attention [Dance Spatial-Attention]
- DT-Attention [Dance Temporal-Attention]
Dance Decoder Block
이전의 방식들은 주로 DT-Attention을 사용해왔다.

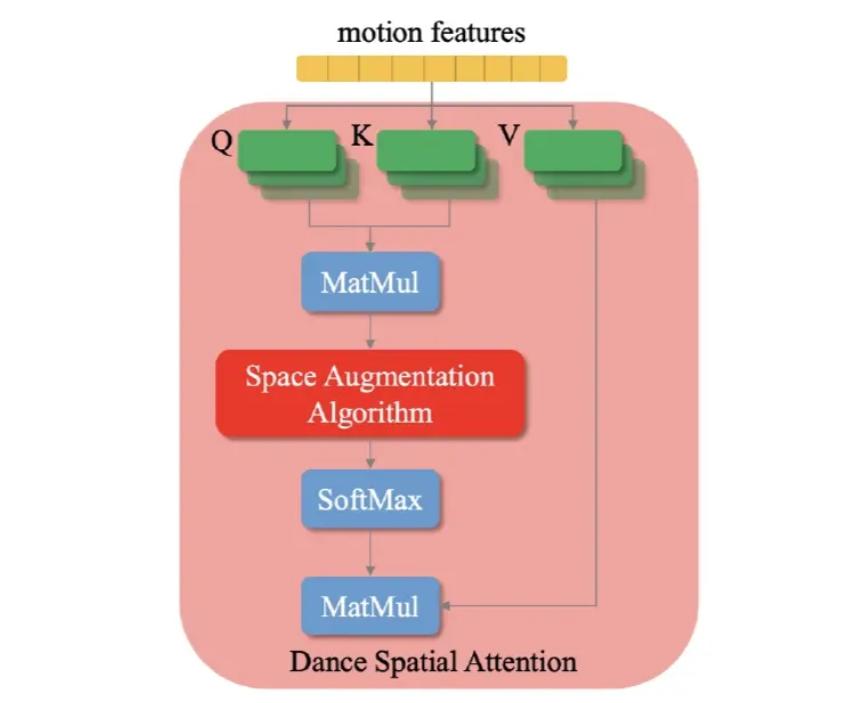
POPDG에서 dance spatial attention [DS-Attention]을 human body joint들 사이의 spatial connection을 포착하기 위해 사용을 했다고 한다.

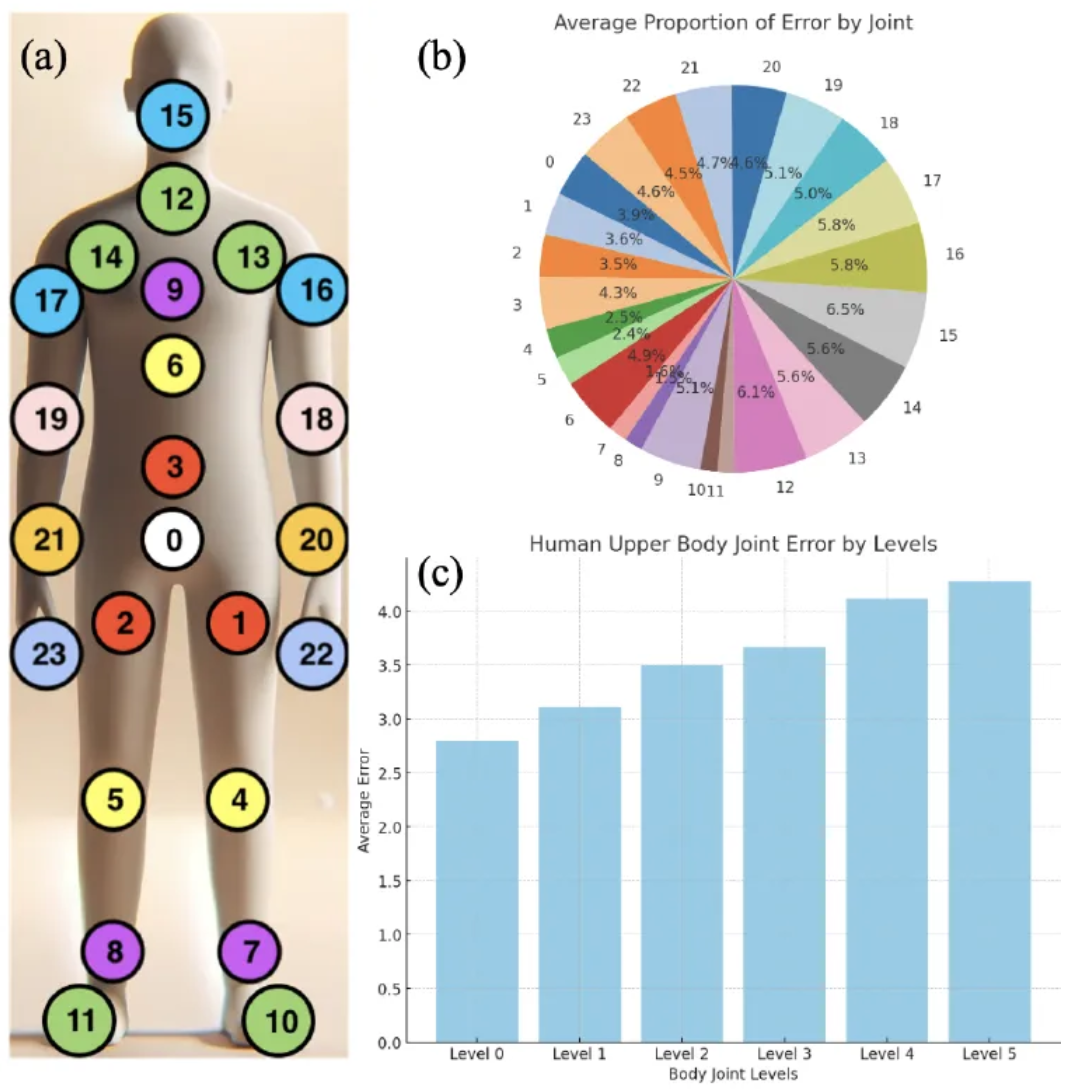
SMPL은 엉덩이 [hip]을 root joint로 지정을 했기 때문에 다른 joint들은 hip으로 부터의 거리로 분류가 된다. 위 그림의 [a]에서 처럼 같은 background color를 갖는 위치가 같은 level을 갖는다는 것을 확인할 수 있다. [b]에서 Ground truth와 생성된 dance movement를 비교하면서 joint error가 root joint와의 거리가 멀 수록 더 커진다는 것을 확인할 수 있었다. [c]는 서로 다른 joint level에서의 평균 error rate를 보여주고 있다.
전통적인 multi-head attention model에서 attention weight는 query와 key 사이의 similarity에 기초해서 구해진다. 특정 joint들 간의 spatial relationship을 얻기 위해서 Space Augmentation Algorithm을 제안했다고 한다. 이 알고리즘의 경우 root joint로부터 joint까지의 거리에 기초해서 weight 값을 부여한다.
Algorithm의 physical meaning은 상체의 각각의 joint와 부모 joint 간의 relationship을 강화하는 것이다. 구체적으로, m의 i+1번째 joint가 n의 i번째 joint보다 위에 있다고 가정을 하자. DS-Attention에서 attentionmap의 계산은 잘 알려져 있다. Root joint와 이웃하는 joint 간의 connection weight [0,m],[m,0],[m,n],[n,m]이 있을 때 만약 [0,n]을 [0,m],[m,0]에 더한다고 하면 필연적으로 joint m과 root joint 간의 connection을 강화하게 될 것이다.
비슷하게, 연속적으로 parent joint로부터 정보를 통과시켜서 downstream-level joint로 전달할 수 있다.

Music Encoder Block
Music Encoder Block의 경우 dance decoder block을 mirroring 해서 생성했다고 한다. Clear temporal spatial definition을 갖고 있는 dance motion과 달리 MF-Attention을 통과시킨 이후에 musical feature는 MFCC나 chroma 같은 수학적 feature들 사이에서 relationship을 얻게 된다.
Alignment Module
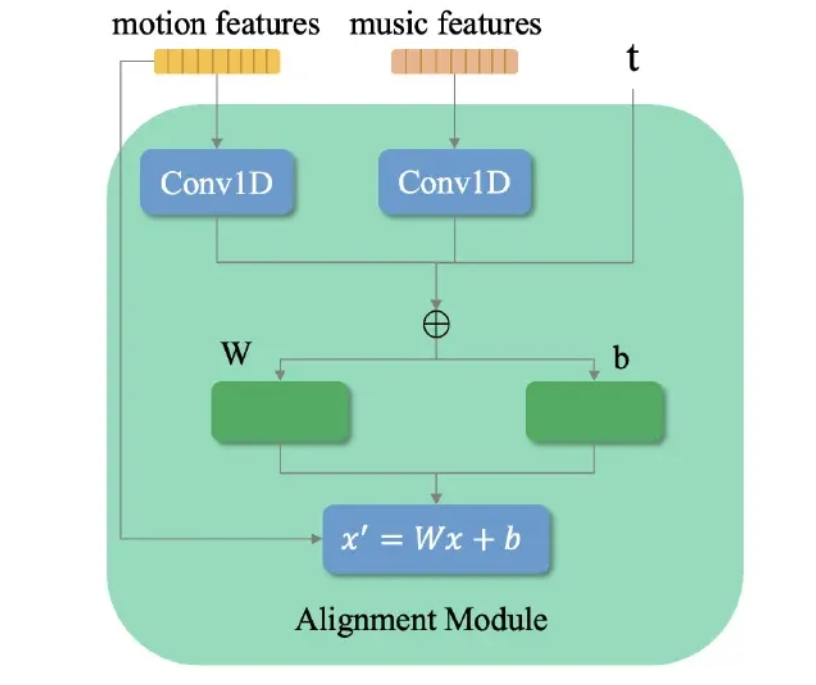
The quality of generated dance is also contingent on its compatibility with the music
따라서 Alignment Module을 만들어서 dance generation의 quality는 유지하면서 dance to music의 adaptability를 향상시켰다고 한다.
Dance와 Music data를 module에 먹이기 전에 이 둘에게 temporal processing을 적용한다. Dance sequence에 spatial position encoding을 적용하던 기존의 방식들과는 달리 본 연구에서는 dance의 temporal, spatial 특성을 동등하게 강조한다. 이 과정은 1차원 convolution 연산을 포함하고 diffusion model에서 timestep 마다 결과 값을 더하는 과정 역시 포함한다.
이렇게 결합된 feature는 DenseFiLM과 동등한 MLP를 통과하게 된다.
Loss Function
Velocity and Acceleration Loss
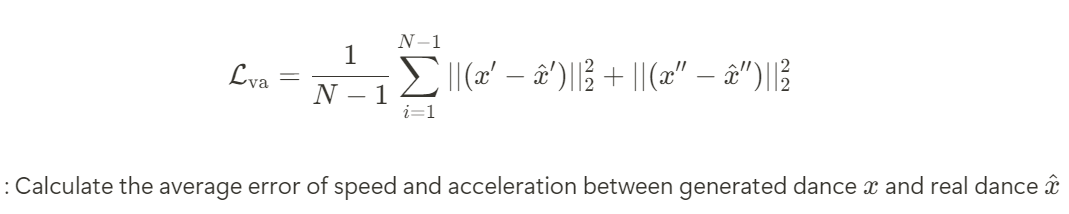
FK Loss and Body Loss

Final Loss
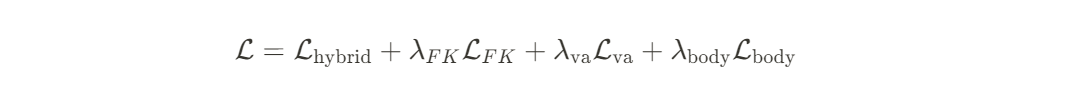
Experiments
Implement Detail
Training에는 736개의 video segment가 사용되었고 Test에는 24개의 video segment가 사용되었다.
전체 실험 과정은 AIST++ dataset에 대해 A800 GPU 2대로 100시간 정도 걸렸고, PopDanceSet에 대해서는 66시간이 걸렸다고 한다.
Dance decoder의 parameter setting은 3D Pose Estimation에서의 parameter와 유사하며 DT-Attention, MF-Attention, MT-Attention은 conventional 8-head attention mechanism에 사용되었다고 한다.
Evaluation Metrics
Motion Quality
- FID [Frechet Inception Distance] : 생성된 댄스의 motion quality 측정
→ FID score는 높게 측정되지만, visual quality가 낮은 결과물이 보임 - PFC [Physical Foot Contact score] : EDGE 논문에서 제안되었으며, hip의 acceleration과 feet의 velocity에 대해 직접적으로 dance movement의 plausibility를 측정
→ 전체 댄스는 전신을 사용하는데 PFC는 하반신만 고려하기 때문에 한계가 있음
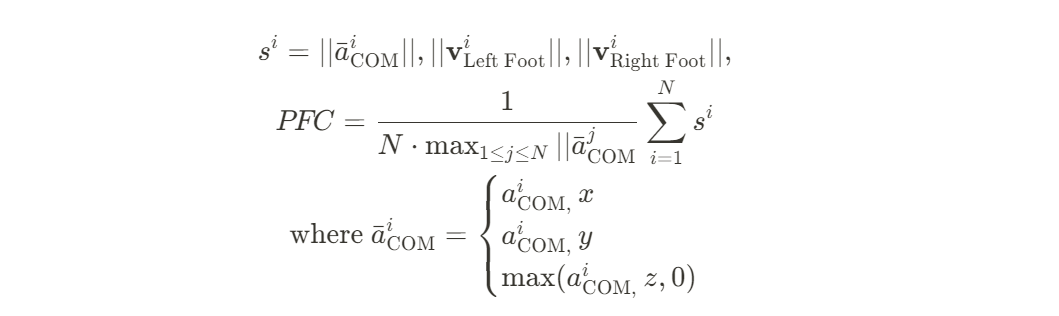
따라서 목, 손까지 고려한 PBC [Physical Body Contact score]를 제안했다

⇒ PFC와 비교해서 PBC는 더 넓은 dance movement의 plausibility를 고려한다
Motion Diversity
Div_k, Div_g : Average kinematic and geometric distance between generated dances and the ground truth to quantify diversity
Motion-Music Correlation
FACT에서 제안된 Beat Align Score 를 사용
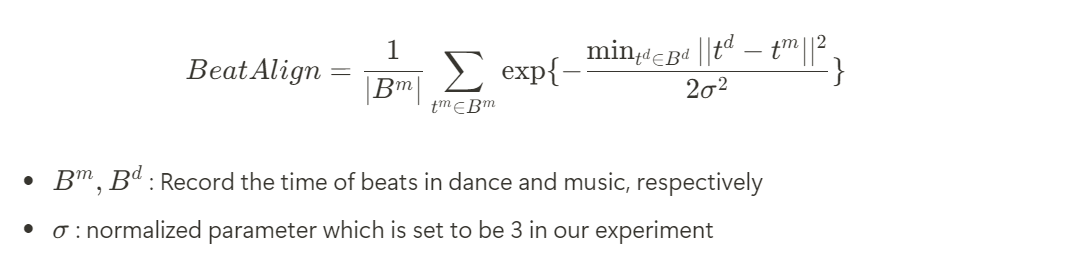
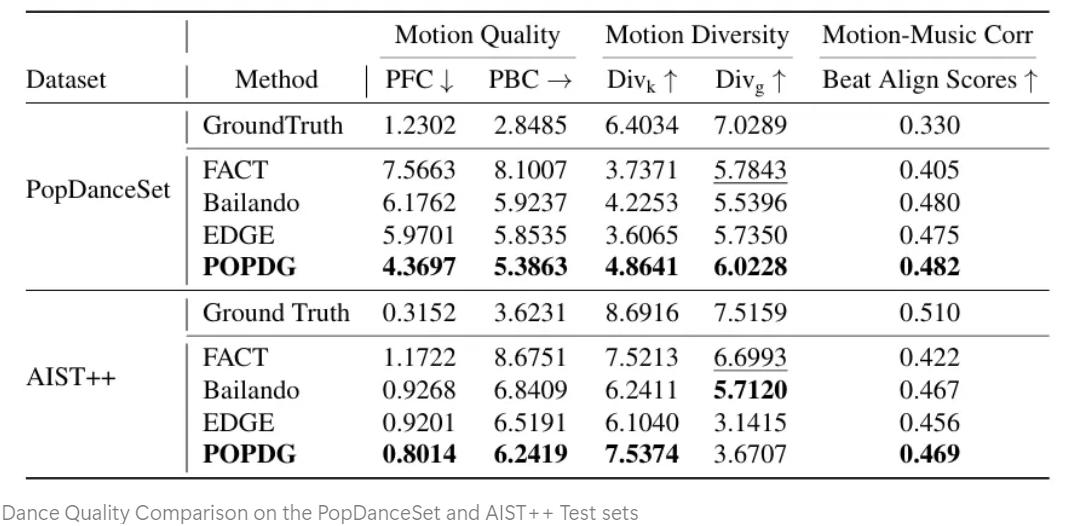
Comparing to Existing Methods

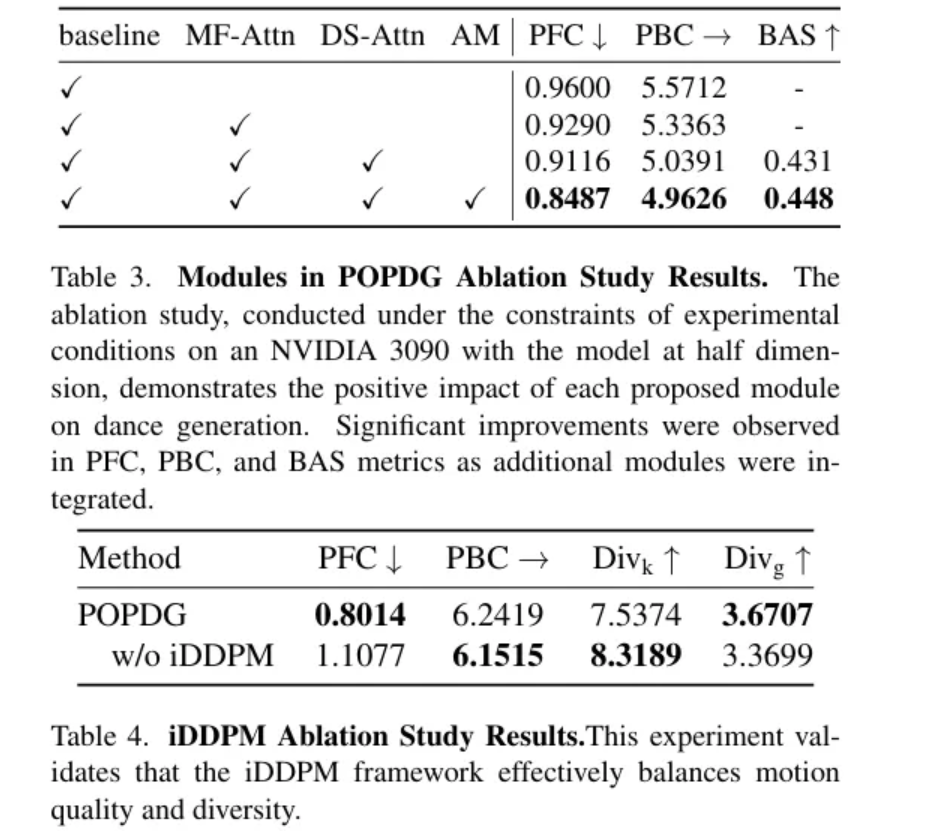
Ablation Study
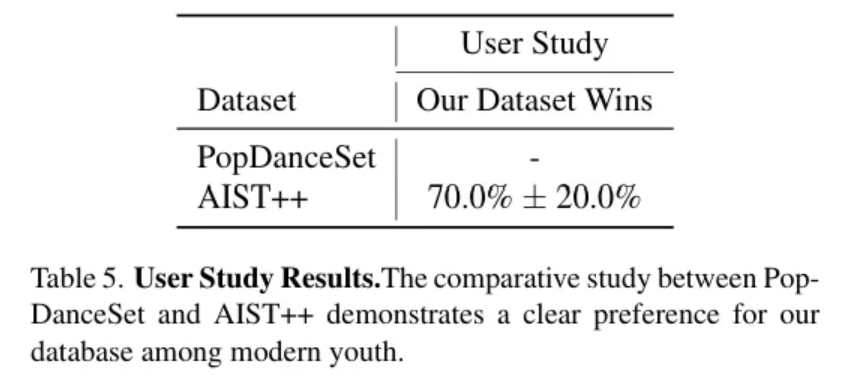
User Study
Conclusion

Model이 end-to-end로 training이 되었지만, 여전히 training cost가 높은 편이기 때문에 future research로는 diversity와 generated dance의 quality의 balance를 유지하면서 더 lightweight한 모델을 사용하는 것을 목표로 했다고 한다.
또한 객관적으로 dance quality를 평가할 수 있는 metric을 발전시킬 것이라고 한다.
'Paper Review > Music-to-Dance' 카테고리의 다른 글
| [논문] Controllable Group Choreography using Contrastive Diffusion | 2025.03.14 |
|---|---|
| [논문] EDGE: Editable Dance Generation from Music | 2025.03.12 |