DiffDance: Cascaded Human Motion Diffusion Model for Dance Generation
When hearing music, it is natural for people to dance to its rhythm. Automatic dance generation, however, is a challenging task due to the physical constraints of human motion and rhythmic alignment with target music. Conventional autoregressive methods in
arxiv.org

Abstract
자동으로 dance를 생성하는 것은 human motion과 rhythm의 alignment로 인해 어려운 task이다. 전통적인 autoregressive 방식들은 sampling 과정에 compounding error를 제안하였고 dance sequence의 long-term sequence를 포착하려고 노력해왔다.
이러한 제한사항을 해결하기 위해 본 논문에서는 cascaded motion diffusion model, DiffDance를 제안해서 high-resolution, long-form dance generation을 하고자 하였다.
Conditional generation에서의 music과 motion 간의 차이를 연결하기 위해 DiffDance는 pretrained audio representation learning model을 사용해서 music embedding을 뽑아내고 이것을 contrastive loss로 music의 embedding space를 motion에 align 시켰다.
Cascaded diffusion model을 학습시키는 동안 연구원들은 여러 개의 geometric loss를 결합해서 model output이 물리학적으로 그럴듯 하도록 억제하고 dynamic loss weight를 추가해서 sample diversity를 이용하기 위해 diffusion timestep마다 adaptive하게 바꿨다. AIST++ benchmark dataset으로 실험을 한 결과 DiffDance는 input music에 align된 real한 dance sequence를 생성할 수 있었다는 것을 확인했다고 한다.
Introduction
Dance is inherently intertwined with music, as individuals naturally move to the rhythm
하지만, 만족스러운 dance를 생성하는 것은 elegant한 movement가 global style, local rhythm level에서 music과 synchronize되어야 하는 것이 요구되기 때문에 어려운 일이다. 전문적인 dancer들도 몇년이 걸리는 작업이라는데 인공지능 따위가 어떻게…?
이러한 점이 연구원들을 자극?해서 자동으로 music에서 dance를 생성하는 task는 최근들어 deep learning community에서 핫한 연구주제가 되었다고 한다.
기존의 연구들은 주로 music-to-dance generation을 autoregressive하게 dance sequence를 생성하는 seq2seq generation task로 인식해왔다. 하지만, 이러한 접근 방식들은 teacher forcing strategy로 학습을 시키는데 이 전략이 autoregressive generation에서 제안된 compounding error에 취약하기 때문에 long sequence를 생성하는 것에는 어려움이 존재했다. 게다가 과거의 방식들은 MFCC, onset strength, constant-Q chromagram 등의 handcrafted spectrogram feature들에 의존했기 때문에 music-dance relationship의 깊은 이해가 부족할 수도 있고 music-to-dance generation 분야에 최적이 아닐 수도 있었다.
대조적으로, dance sequence는 일반적인 human motion보다 보통 훨씬 더 길고 복잡한 특성을 보이기 때문에 symmetrocal repetitive motion 같은 global structure를 보여준다. 그래서 이러한 모델들은 극단적으로 긴 sequence를 모델링하였고 long-term structure를 구성하였으나 realistic한 측면에서는 실패를 했다.
본 논문에서는 input music과 align된 high temporal resolution dance sequence를 diffusion model을 사용해서 생성하는 것을 목표로 하였다. 이를 위해 cascaded human diffusion model framework, DiffDance를 제안하였다. 구체적으로, DiffDance는 music-to-dance diffusion model을 포함하여 2단계 방식으로 구성되어 있다. Music-to-dance diffusion model은 먼저 low-resolution dance sequence들을 생성하고 super-resolution model을 통과시켜서 low-resolution sequence를 input motion들 간의 intermediate motion을 채워나가는 과정을 통해 upscaling시켜서 최종 sequence를 생성한다.
Conditional generation을 가능하게 만들기 위해 본 논문에서는 Wav2CLIP을 사용해서 input music을 conventional handcrafted feature들 대신 학습된 embedding에 mapping시키고자 하였다.
이 두 단계에서의 model들은 학습된 embedding에 conditioning 되어 있고 sample의 quality를 높이기 위해 classifier-free guidance를 사용했다는 점이 특징이다. Wav2CLIP audio encoder가 image와 text 사이에서만 embedding space를 공유하기 때문에 이 embedding space를 motion에 align 시키고자 MotionCLIP에서의 motion encoder를 freezing 시켰고 AIST++의 paired data를 이용하여 audio encoder를 finetuning 시켰다고 한다. Finetuning을 시킨 이후에 audio encoder는 motion semantics와 align된 latent representation을 생성할 수 있게 되어 music-to-dance의 성능을 증폭시킬 수 있게 된다. 마지막으로, 본 논문에서는 학습 과정에 여러개의 geometric loss를 결합해서 key joint position과 rotation regularization loss를 제안해서 부자연스러운 artifact들을 방지하고 즉각적인 rotation을 방지하였다.
Contribution
- We propose a cascaded motion diffusion model that generates long-form, high-resolution dance sequences
- We align the CLIP embedding space of music and dance for better feature representation and demonstrate the effectiveness of classifier-free guidance in music-to-dance generation
- We incorporate a variety of geometric losses and a dynamic loss weight schedule to produce realistic samples while maintaining diversity
- Extensive experiments demonstrate our proposed DiffDance surpasses the SOTA model in terms of dance quality and music-dance correspondence
Method

Preliminaries of Diffusion Models

Cascaded Motion Diffusion Model
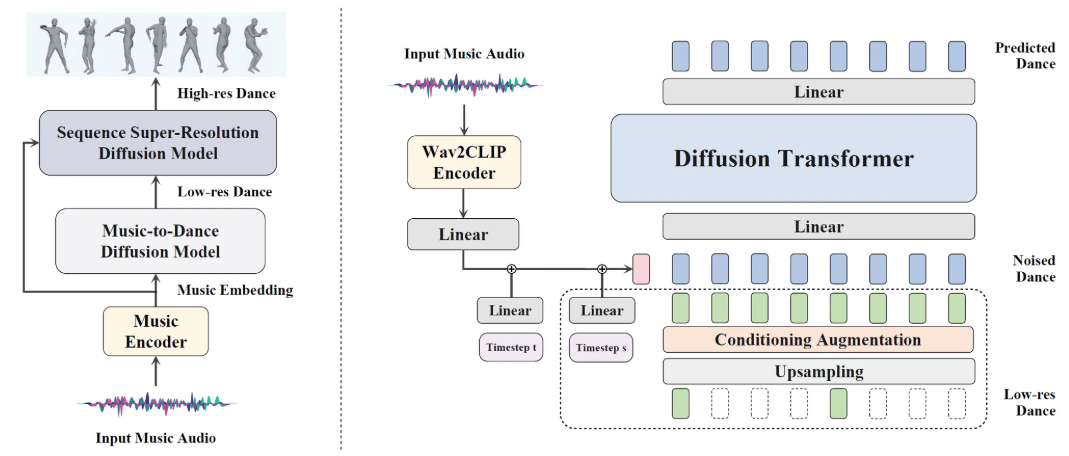
Framework

Training Objective


Conditional Generation

주어진 input music에 대해 본 논문의 objective는 풍부한 semantic information을 포함하고 있는 music representation을 뽑아내는 것이다.
Music Representations
이전의 접근 방식들은 conditional generation을 위한 music representation에 큰 중요도를 부여하지 않았다. 이 방식들은 주로 onset strength as rhythmic features, constant-Q chromagram as chroma features 같은 handcrafted music feature들을 이용했는데, 이 feature들의 한 가지 결점은 high-level semantics가 부족해서 cross-modality generation에는 치명적이라는 점이다.
Large-scale visual-textual embedding model인 CLIP은 text-guided generation 작업에서 효율성을 보였다. 마찬가지로, Wav2CLIP의 audio encoder를 이용해서 audio clip을 CLIP에서 text와 image가 공유하는 embedding space의 512차원 vector로 encoding 하였다. 그러나, Wav2CLIP audio encoder가 일반적인 audio-visual dataset에 대해서만 학습이 되었기 때문에 뽑아낸 music representation과 dance motion 사이에는 큰 domain gap이 여전히 존재했는데, 이 둘의 embedding space를 더 잘 align 시키기 위해 audio encoder에 adapter layer 같은 MLP를 추가해서 finetuning 하고 output을 motion encoder에 mapping 시켰다고 한다.
Modal collapse를 완화하기 위해 motion encoder와 music encoder의 weight를 finetuning 동안 freeze 시키고 adapter layer만 InfoNCE loss로 학습시켰다고 한다. Music-to-dance의 i번째 pair의 contrastive loss는 다음과 같다고 한다.

Classifier-Free Guidance
Music-dance joint embedding space를 학습한 이후에 music representation을 뽑아내고 classifier-free guidance를 이용해서 sample quality를 높이고자 하였다.
실제로 하나의 diffusion model에 무작위로 music condition $c$를 떨어뜨려서 conditional/unconditional objective로 동시에 학습시켰다. Sampling 동안에 $x_0$ prediction을 다음 수식을 이용해서 수정함으로써 sample quality를 높일 수 있었다고 한다.

Experiment
Dataset
AIST++는 3D human dance dataset으로 1363개의 3D dance sequence와 music pair를 갖고 있다.
Implementation Details
Alignment Setting
- Optimizer: AdamW, learning rate $1e^{-5}$
- Epochs: 100
- Batch Size: 64
- Music Clip: Librosa 사용, 6초 단위 분할
- Dance Clip: Rotation 6D format, 6초 단위 분할
- Frame Rate: 60 FPS → 30 FPS [MotionCLIP setting 따라감]
- Adapter: 2-layer MLP, hidden size 512
Cascaded Diffusion Model Setting
- Optimizer: AdamW, learning rate $1e^{-4}$
- Epochs: 500
- Music Representation: Frozen Wav2CLIP → 512D vector
- Classifier-Free Guidance: 10% 확률로 music condition masking
- Diffusion Transformer:
- 12 layers,
- hidden size 768,
- 6 heads,
- dropout 0.1
- Geometric Loss Weight $\lambda_1,\lambda_2,\lambda_3=1.0$
- Decay Coefficient $\alpha=0.1$
- Base M2D Model:
- Batch Size: 32
- FPS: 60 → 15
- Sequence Length: 20초
- SSR Model:
- Batch Size: 8
- FPS: 60
- Training Hardware: Tesla V100 × 4, 1일 소요
Inference Setting
- Seed Sequence: 2초 [120 frames]
- Generated Sequence: 20초 [1200 frames]
- Classifier-Free Guidance Weight: $w=2.5$
- Inference Diffusion Timestep: $T=100$
Evaluation Metrics
Dance quality, dance diversity, music beat alignment의 관점에서 평가를 하였다고 한다.

Comparison with Baselines
DanceNet, DanceRevolution, FACT, Bailando와 비교를 했다고 한다.




Conclusion
DiffDance는 music-to-dance diffusion model과 sequence super-resolution diffusion model로 구성되어 high-resolution, long-form dance sequence를 temporal consistency를 유지하면서 생성할 수 있게 해주었다. Semantic music representation을 향상시키기 위해 motion을 music embedding space에 contrastive objective로 music encoder를 finetuning 시킴으로써 align 시켰다. 추가적으로, classifier-free guidance를 사용하였고 다양한 geometric loss와 dynamic loss decay weight를 사용해서 fidelity와 diversity를 향상시켰다.
'Paper Review > Music-to-Dance' 카테고리의 다른 글
| [논문] POPDG: Popular 3D Dance Generation with PopDanceSet (0) | 2025.03.19 |
|---|---|
| [논문] Controllable Group Choreography using Contrastive Diffusion (0) | 2025.03.14 |
| [논문] EDGE: Editable Dance Generation from Music (1) | 2025.03.12 |