
2024.09.10 - [Paper Review] - [논문] Segmentation
이번 posting에서는 NLP에서 성능이 매우 좋다는 것이 증명된 Transformer를 vision task로 가져온 논문 3편에 대해 요약을 할 것이다.
- ViT [Vision Transformer]
https://arxiv.org/abs/2010.11929 - [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org
- DETR [Detection Transformer]
https://arxiv.org/abs/2005.12872
End-to-End Object Detection with Transformers
We present a new method that views object detection as a direct set prediction problem. Our approach streamlines the detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression procedure or anchor gene
arxiv.org
- Segmenter [Transformer on Segmentation]
https://arxiv.org/abs/2105.05633
Segmenter: Transformer for Semantic Segmentation
Image segmentation is often ambiguous at the level of individual image patches and requires contextual information to reach label consensus. In this paper we introduce Segmenter, a transformer model for semantic segmentation. In contrast to convolution-bas
arxiv.org

ViT [Vision Transformer]
Transformer가 대두되게 된 이유는 여러 이유들이 있지만 대표적으로 computational efficiency와 scalability가 있다. 이러한 이유로 NLP에서는 Transformer가 Vision에서의 CNN과 같은 base of base model의 위치에 도달할 수 있게 된 것이고 당연하게도 vision 분야에 Transformer를 적용해보려는 연구들이 여럿 존재했었다.
Vision task에 Transformer를 적용하는 방식은 생각보다 간단하다.
위의 그림처럼 input image를 같은 크기의 patch로 나눈 뒤, position embedding과 함께 linear embedding을 해서 Transformer의 encoder를 통과한 뒤 MHA[Multi-Head Attention]와 MLP[Multi-Layer Perceptron]를 거쳐 이 object가 어떤 class인지를 예측하게 된다. 이 때, position embedding의 경우 NLP의 BERT에서의 [class] token과 같이 이 image가 전체적으로 어떤 context를 담고 있는지에 대한 정보가 담겨있다.
Inductive bias
https://en.wikipedia.org/wiki/Inductive_bias
Inductive bias - Wikipedia
From Wikipedia, the free encyclopedia Assumptions for inference in machine learning The inductive bias of a learning algorithm is the set of assumptions that the learner uses to predict outputs of given inputs that it has not
en.wikipedia.org
Inductive bias란 직역하면 편향 추론이고 의미를 해석하면 쉽게 말해 이전의 결과가 다음 결과에 얼마만큼의 영향을 주는지에 대한 정도라고 보면 될 것 같다.
예를 들어, y=x라는 식이 있다고 가정을 하자. 이 식에 x=1, 2가 주어졌고 output으로 y=1, 2가 나온다는 것을 알았을 때 다음 input으로 x=5가 나오게 되면 output이 y=5가 나올 것이라고 예상을 하는 사람들이 대부분일 것이다. 이러한 경우를 "inductive bias가 강하다"라고 한다.
기존의 CNN의 경우 kernel이 input image를 sliding하면서 feature를 얻어내는 방식을 사용한다. 이 방식의 경우 locality에 의해 inductive bias가 상대적으로 강한 편에 속하게 된다. 반면에 Transformer의 경우 input image를 patch 단위로 쪼개서 한꺼번에 encoder에 집어넣기 때문에 CNN에 비하면 상대적으로 inductive bias가 낮아지게 된다.
Inductive bias가 높다는 의미는 적은 dataset으로도 높은 성능을 낼 수 있다는 의미로 해석할 수 있다.
따라서 inductive bias가 약한 것을 보완하기 위해 Transformer는 많은 dataset에 의존하는 방법을 사용하게 된다. 많은 dataset이 필요하기 때문에 연산량도 비례해서 많아지긴 하지만, Transformer는 robust하게 동작하기 때문에 NLP 뿐만 아니라 여러 task에서 좋은 성능을 보일 수 있게 된다.
MSA [Multihead Self-Attention]
MSA는 query, key, value의 pair로 구성되어 있고 일반적인 transformer처럼 진행이 된다
MLP [Multi-Layer Perceptron]
MLP를 수식으로 접근하면 위와 같다. z0를 보면 {x_p^i, i∈{1,2,...,N}}에 position embedding E가 곱해져 있는 것을 확인할 수 있고, 이를 linear하게 embedding한 vector형태를 하고 있다. 이 때 제일 앞에 위에서 언급한 BERT의 [class] token과 같은 역할을 하는 x_class도 있는 것을 확인할 수 있다.
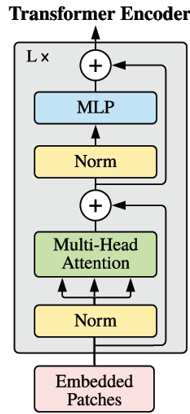
그 다음 transformer의 encoder 구조를 보면 LN을 거쳐 MSA를 통과하는데 옆에 skip connection이 존재하는 것을 확인할 수 있는데, 이에 대한 수식이 이다. 동일하게 MLP를 통과할 때도 LN을 거쳐 skip connection까지 거치면 식이 나오게 된다.
Result
Attention Map

Dataset




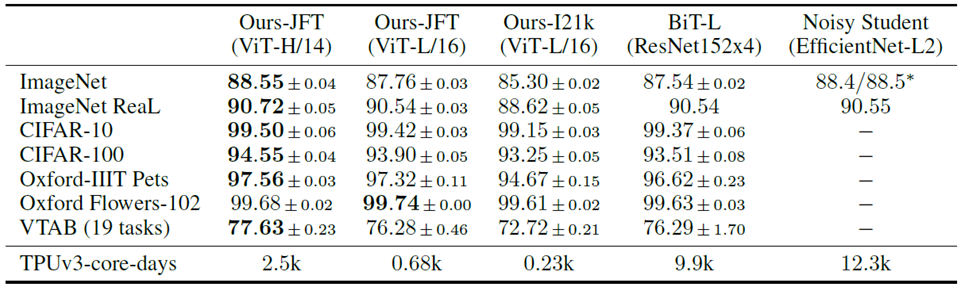
위 dataset으로 pre-trained 시킨 뒤 benchmark task들에 transfer해서 성능을 확인한 결과 mAP값이 높게 측정된다고 한다.
DETR [Detection Transformer]

두 번째 논문은 transformer model을 detection 분야에 적용을 한 DETR 논문이다.
오른쪽 그림을 보면 기존의 detection task의 경우 anchor [region proposal]를 미리 정해서 detection model에 input으로 주면 그 model이 object가 있을법한 위치에 bounding box를 예측을 해서 output으로 주면 Non-max Suppression 같은 post-processing을 거쳐서 흔히 아는 detection의 결과가 도출되게 된다.
이렇게 하면 accuracy가 높게 나오더라도 너무 많은 과정을 거치기 때문에 시간이 오래걸릴 수 밖에 없다.
그런데 이 논문에서는 DETR이라는 transformer-based detection model을 사용하게 되면 비슷하거나 더 높은 성능을 보이면서 pipeline이 더욱 간단해지고 post-processing을 할 필요가 없어진다는 점에서 DETR의 장점을 어필하고 있다.
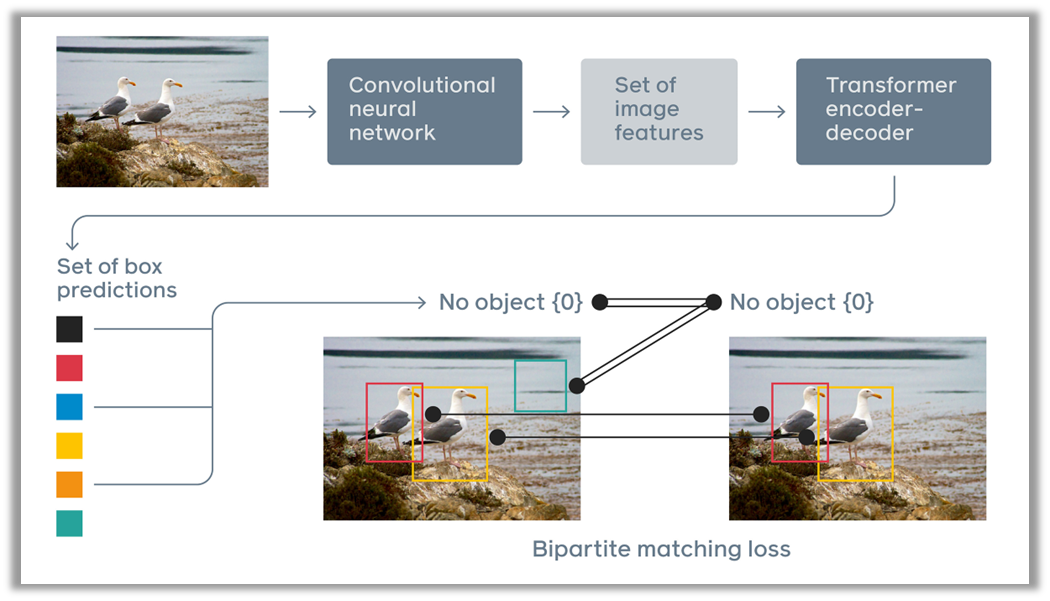
DETR의 pipeline을 그림으로 보면 위와 같다.
여기서 Transformer에 의해 예측된 class와 object를 matching 시킬 때 bipartite matching이라는 방식이 사용되는데 이는 뒤에서 설명하고 먼저 loss함수 부터 살펴보도록 하겠다.
Loss Function
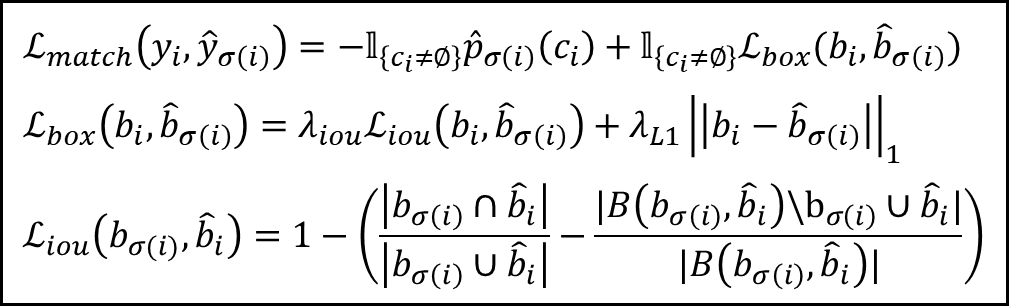
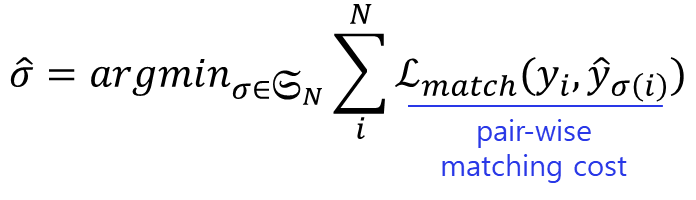
전체적인 loss는 match loss의 의 최솟값을 구하는 형태로 되어 있고, match loss는 class loss와 box loss의 합으로 이루어져 있다.
Bipartite Matching
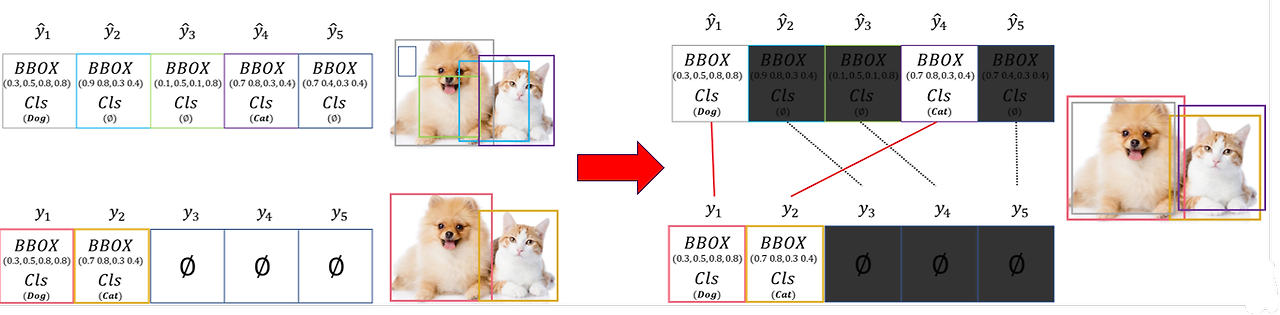
Bipartite matching이란 이웃한 정점끼리는 같은 집합에 속하지 않으면서, 전체 정점을 두 집합으로 나눌 수 있어야 하는 matching으로 쉽게 말해 두 그룹의 정점이 다른 그룹에 최대 1개의 간선만 가지도록 구성된 matching을 의미한다.
위의 그림에서 강아지와 고양이가 있는 image에 5개의 bounding box가 존재하고, 각각 class label이 embedding되어 있다. 이 때, Dog와 Cat을 제외한 나머지는 object가 없거나 bbox에 여러 object가 존재하는 경우 등등에 해당한다.
이걸 bipartite matching으로 mapping을 하면 오른쪽과 같이 되는데, 이렇게 했을 때 아래쪽에 있는 빨간색과 노란색의 ground truth와 비교했을 때 가장 큰 IoU 값을 갖는 bounding box만 mapping되게 되는 원리이다.
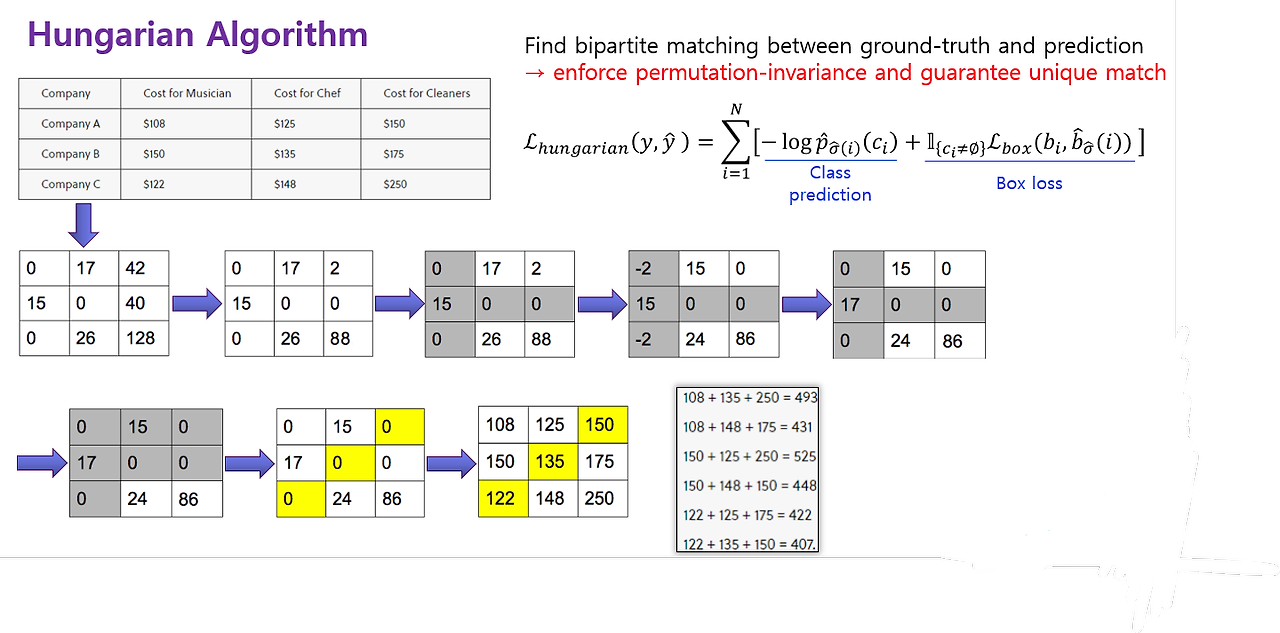
여기서 mapping을 할 때는 Hungarian Algorithm이 사용된다.
참고
https://en.wikipedia.org/wiki/Hungarian_algorithm
Hungarian algorithm - Wikipedia
From Wikipedia, the free encyclopedia Polynomial-time algorithm for the assignment problem The Hungarian method is a combinatorial optimization algorithm that solves the assignment problem in polynomial time and which anticipated later primal–dual method
en.wikipedia.org
https://gazelle-and-cs.tistory.com/29
할당 문제 & 헝가리안 알고리즘
이번 포스팅에서는 assignment problem과 Hungarian algorithm에 대해서 알아보겠습니다. 먼저 assignment problem이 어떤 것인지에 대해서 살펴보고, 이를 해결하는 방법을 알아보도록 하겠습니다. 인터넷을 찾
gazelle-and-cs.tistory.com
Hungarian Algorithm이란, 간단히 설명하자면 minimum cost를 찾는 algorithm이다. 자세한 방식은 위의 두 site를 참고하면 이해가 될 것이다.
Architecture
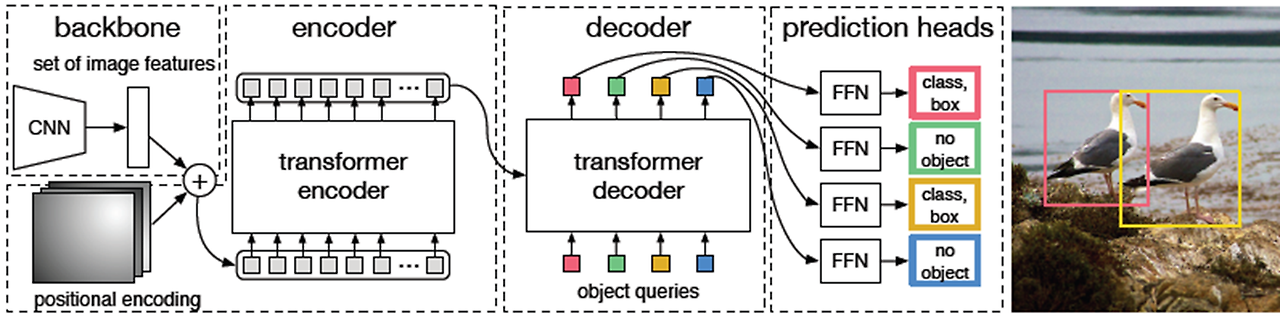
DETR의 전체 flow를 보면 CNN으로 image feature를 뽑아낸 뒤 position embedding과 결합해서 Transformer의 encoder로 들어가고, encoder에 의해 나온 output이 decoder에서 object query와 결합하여 class와 bounding box를 예측하게 된다.
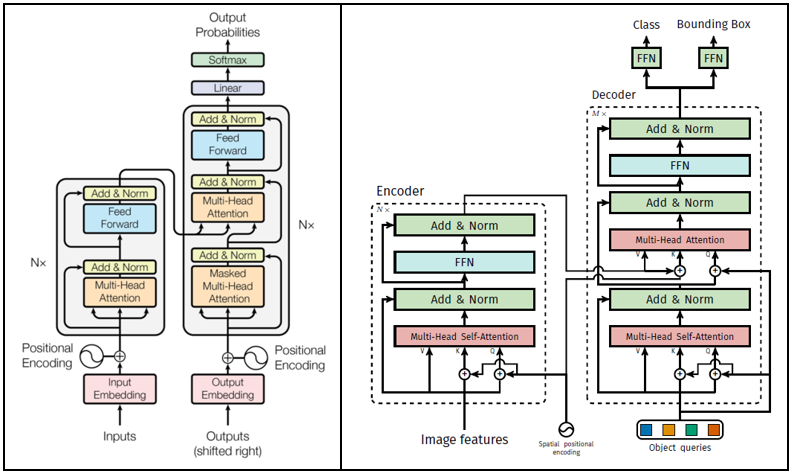
오른쪽이 DETR의 Transformer 구조이다. 흔히 알고 있는 Transformer의 구조가 왼쪽인데 이 둘을 비교하면 전체적인 큰 틀은 비슷하지만 detail한 부분에서 차이점들이 존재한다.
- Positional encoding
: Positional encoding이 기존의 transformer는 encoder와 decoder 이전에 들어가는 반면, DETR은 spatial positional encoding encoder에서는 query 부분에서만 들어가고 decoder에서는 cross-attention에서 들어간다. - Auto-regression / Parallel
: NLP에서는 transformer에 들어갈 때 한 번에 하나의 token을 예측하는 반면, Vision에서는 image 전체가 patch화 되어 한번에 들어가기 때문에 병렬적으로 예측이 가능하다 - Encoder
: Encoder에 들어가는 input이 NLP는 word embedding이고 vision은 Image feature map이다. - Decoder
: Decoder에 들어가는 output이 NLP는 target embedding이고 vision은 Object query이다. - Masked Multi-Head Attention
: 기존의 Transformer의 decoder에는 Masked Multi-Head Attention이라는 구조가 존재하는데, 이것의 역할은 현재 위치 이후의 단어를 masking하여 보지 못하도록 하는 것이다. 이를 통해 decoder가 올바른 순서대로 단어를 생성할 수 있게 한다.
그러나 Vision의 경우 permutation invariant 하기 때문에 image patch의 순서가 고려될 필요가 없다. 따라서 DETR의 Masked MHA는 Masking이 되어 있지 않다. - Output
: 기존의 Transformer와 DETR을 비교해보면, NLP에서의 Transformer는 다음 단어를 예측하기 때문에 output으로 가장 적합한 단어의 probability를 생성한다. 반면에 DETR은 detection task를 수행하기 때문에 class에 대한 probability와 bounding box에 대한 probability 2개의 output을 생성한다. 따라서 이 부분에서도 차이점이 존재한다.

Encoder와 Decoder를 통해 나온 결과를 보면, Encoder에서는 Object에 대한 attention map이 생성되고, 이 attention map이 decoder로 들어가면서 object query와 만나 bounding box와 class에 대한 예측 값이 나오게 되어 아래와 같이 detection이 가능하게 된다.
특징으로는, attention이 object의 끝부분이나 경계부분에서 높게 측정이 된다는 점인데, background와 foreground를 구분하는 위치이기 때문에 높게 측정되는 것은 어쩌면 당연하다고 생각한다.
Panoptic Segmentation
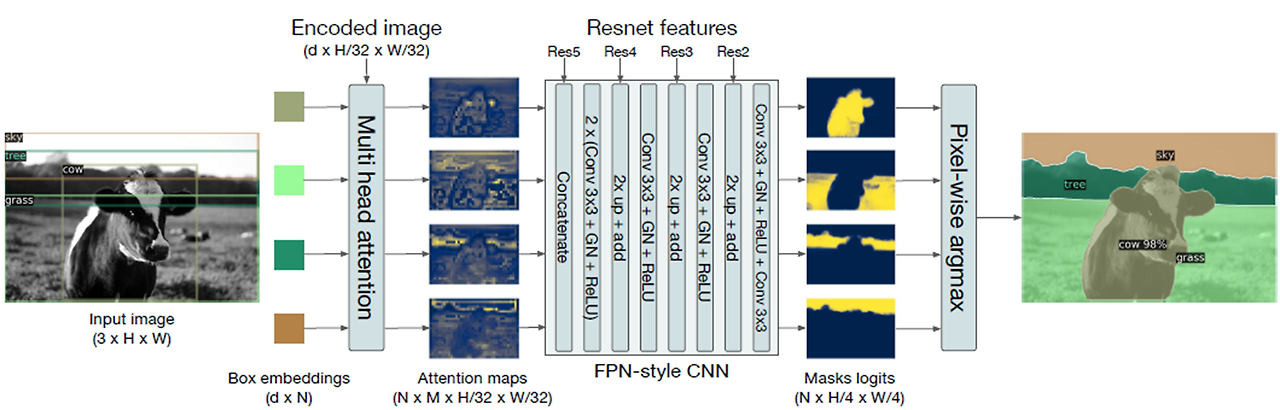
위에서 말단 부분이나 경계부분에 attention score가 높게 측정된다는 점이 background와 foreground를 더 높은 확률로 구분할 수 있다고 했었는데, 이 점이 panoptic segmentation과 연결이 되게 된다.
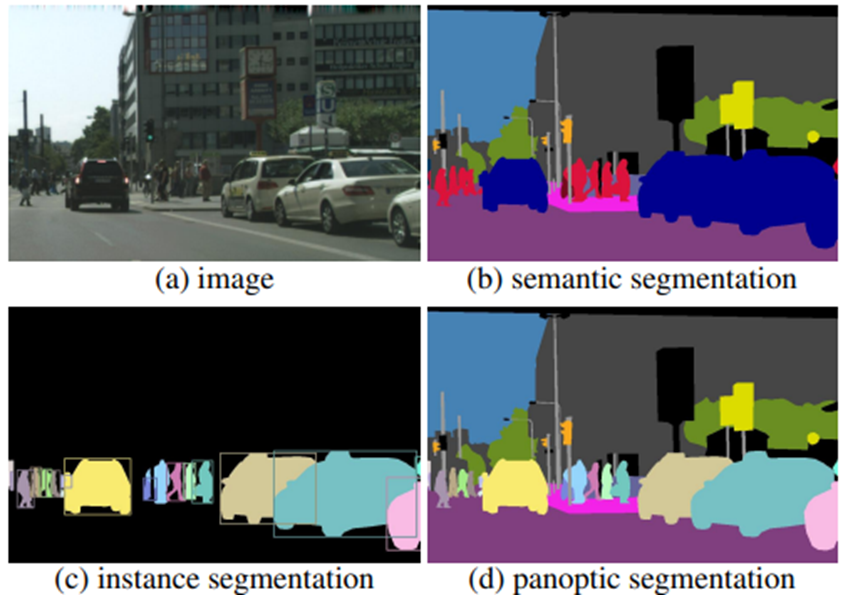
이전 posting에서 panoptic segmentation에 대해 다루긴 했었지만 다시 간단히 설명하면 segmentation은 크게 instance segmentation, semantic segmentation, panoptic segmentation으로 나눌 수 있는데 앞의 두 segmentation의 장점들을 합친 것이 panoptic segmentation이라고 생각하면 쉽다.
DETR의 특징을 이용하면

위의 그림과 같이 특정 object에 대한 attention score가 높게 측정된다는 점으로 segmentation task까지 확장이 가능하다.
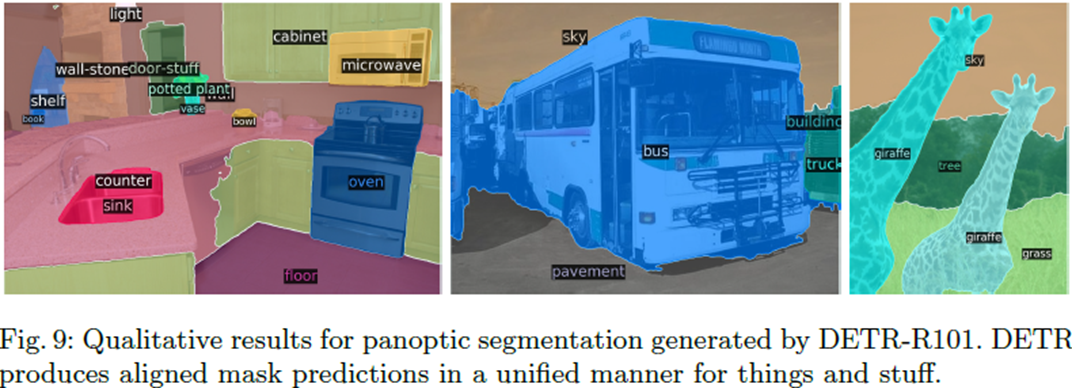
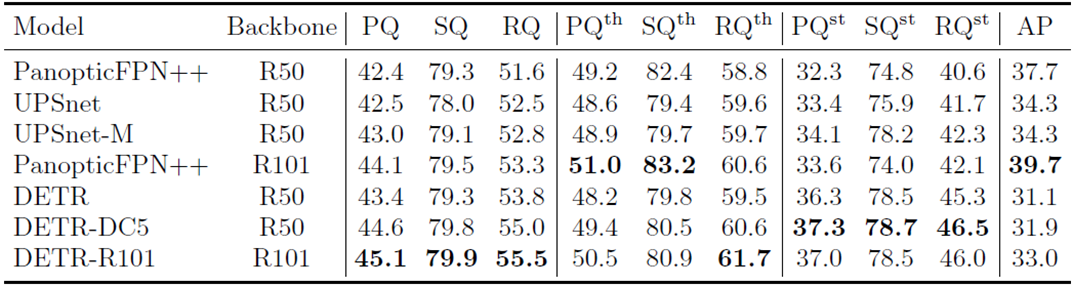
그리고 결과도 panopticFPN과 비교하면 DETR의 panoptic quality가 높게 측정되는 것을 확인할 수 있다.
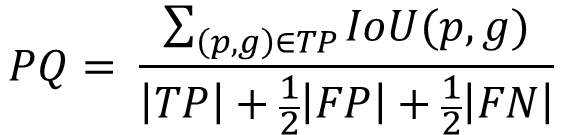
2024.09.10 - [Paper Review] - [논문] Segmentation
[논문] Segmentation
이번 posting에서 다룰 논문은 Segmentation에 대해 3개의 논문을 다룰 것이다.Segmentation의 경우 크게 3가지로 분류할 수 있는데, Semantic Segmentation, Instance Segmentation, Panoptic Segmentation이 그 3가지 이다.Sema
phj6724.tistory.com
이전에 posting했던 Segmentation에 대한 내용을 보면 Panoptic Quality에 대한 설명이 있으니까 참고하면 좋을 것 같다.
Segmenter [Transformer for Semantic Segmentation]
마지막으로는 Segmenter라는 논문으로 Transformer를 semantic segmentation의 영역으로 가져온 논문이다.
Image의 경우 contextual information이 미치는 영향이 큰데, convolutional 방법의 경우는 locality가 크기 때문에 large receptive field 과는 거리가 멀다.
따라서 receptive field를 넓히고 semantic segmentation을 NLP처럼 sequence-to-sequence로 접근하기 위해 ViT의 architecture를 참고했다고 한다.
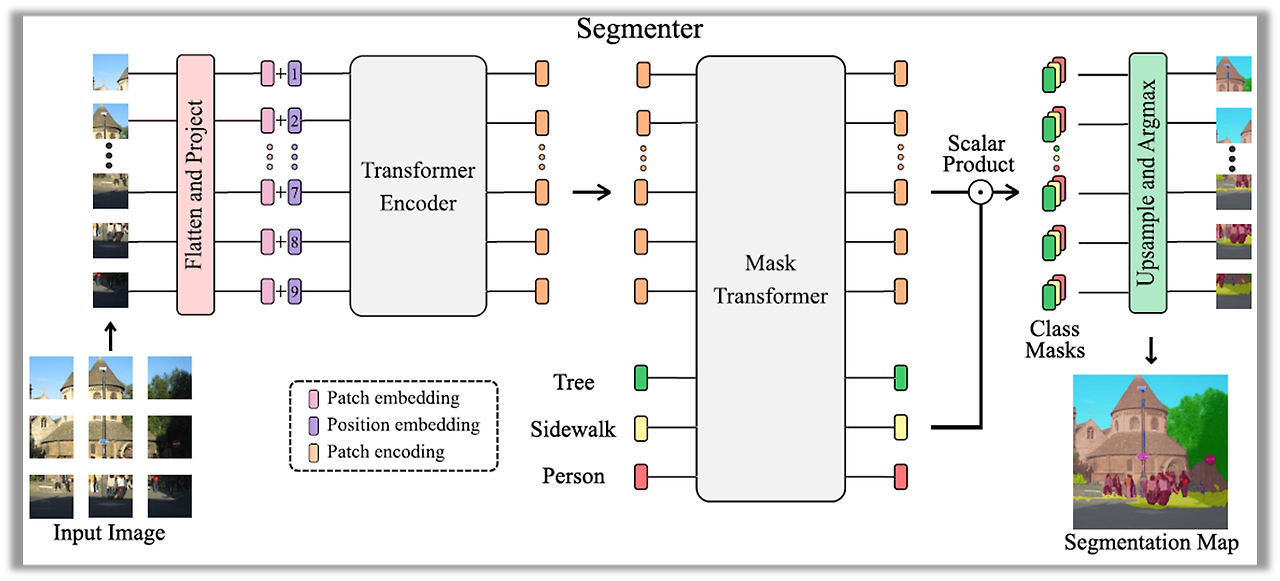
그림을 보면 알 수 있듯이 image를 patch 단위로 쪼개서 linear embedding으로 encoder에 input으로 주는 것이 ViT의 architecture과 굉장히 유사한 것을 알 수 있다. Segmenter에서는 decoder가 라고 나와 있지만, 결국 encoder에서 나온 feature와 object query를 decoder로 통과시켜서 나온 output의 scalar 연산으로 class mask를 얻어서 upsampling으로 segmentation을 하는 과정으로 진행이 된다. 여기서 Mask Transformer인 이유는 object를 제외한 나머지 부분을 masking하기 위함이라고 이해했다.

그리고 Encoder와 Decoder를 각각 나눠서 확인해보면 Encoder에서는 layer가 깊어질 수록 더 detail한 object를 검출한다는 것 을 볼 수 있고, Decoder에서는 각각의 class에 대한 attention이 높게 측정된다는 것을 볼 수 있다.
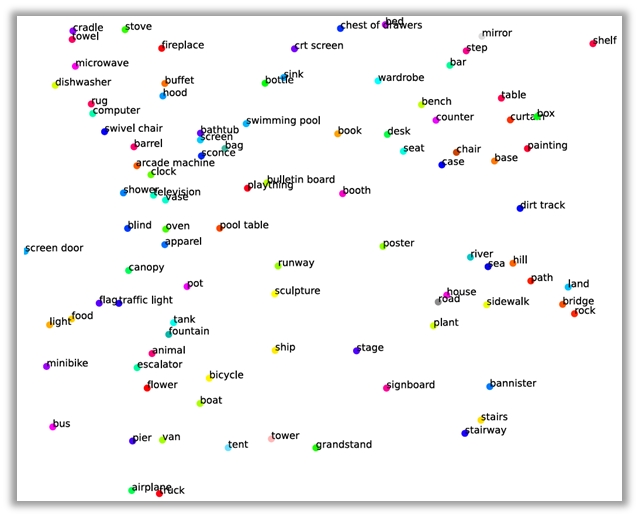
한가지 더 plotting을 한 결과를 보면 비슷한 category끼리 뭉쳐 있는 것도 확인할 수 있다.
Result
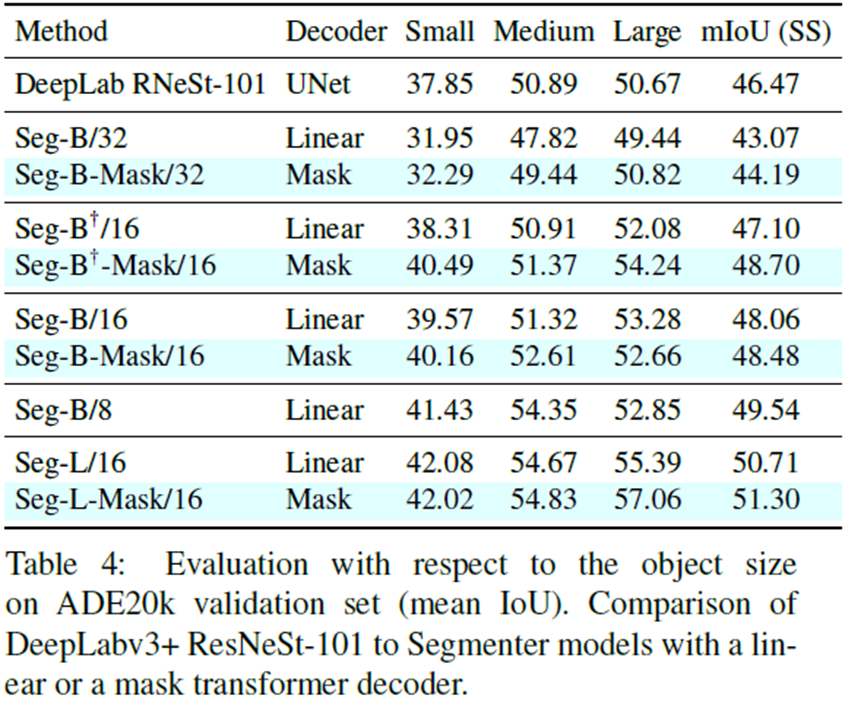
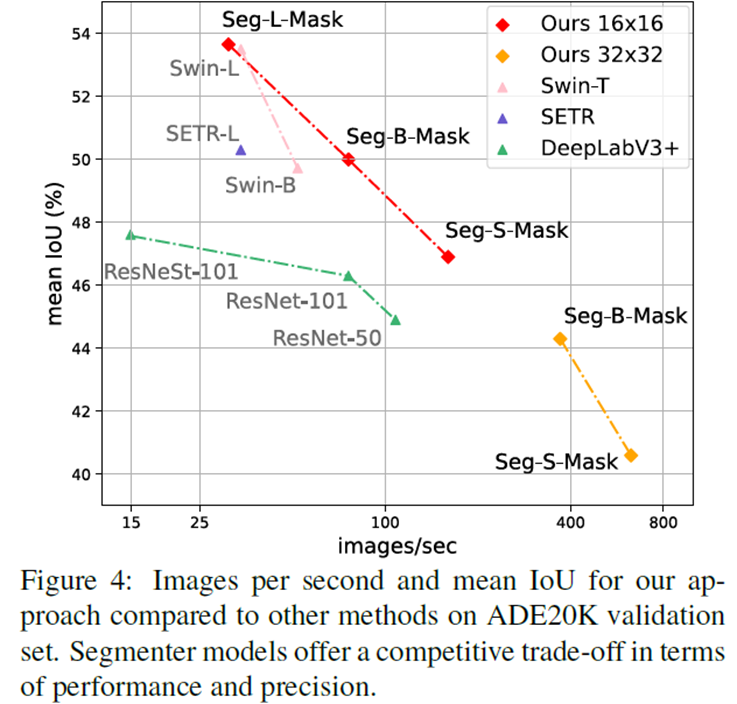
DeepLab을 비롯한 다른 SOTA 모델과 비교했을 때 더 높은 mIoU, mAP, image처리량을 보인다.

지금까지 Transformer를 여러 vision task에 적용하려고 시도한 3편의 논문들을 확인해보았다.
"Transformer는 신이다" 누가 이런 말을 했었는데 이해가 된다. NLP 뿐만 아니라 Vision에서도 성능이 검증되었기 때문에 이쯤되면 신이 맞는 것 같기도..?
긴글 읽어주셔서 감사합니다. 틀린 부분있으면 편하게 댓글 남겨주시면 감사드리겠습니다.
- 다음 posting : Pose Estimation