
https://arxiv.org/abs/2103.14030
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as
arxiv.org
이번 포스팅은 2021 ICCV에 accept된 Swin Transformer에 대한 내용이다.
Abstract
Swin Transformer - serves as a general-purpose backbone for computer vision
- Language에 쓰이는 Transformer를 Vision에 적용시키는 것은 2가지 domain 측면에서 차이점이 존재함
- Large variations in the scale of vision entities
- High resolution of pixels in images compared to words in text
Shifted window의 경우 cross-window connection은 허용하면서 겹치지 않는 local window에 대해 self-attention 연산을 제한함으로써 효율을 높였음
이 hierarchical architecture의 경우 다양한 scale에서 model에 flexibility를 갖고 있고 image size에 대해 linear computational complexity를 가짐
Introduction
Computer Vision에서의 modeling은 CNN이 지배적이였고, AlexNet의 등장으로 가속도를 받았음.
반면에 NLP에서는 Transformer가 지배적이였는데, Transformer의 경우 sequence modeling과 transduction task들을 위해 설계가 되어있어서 attention을 이용해서 data의 long-range dependency를 modeling하는 것에 장점이 있었다.
이 Transformer를 vision task로 가져오는 것은 2개의 modality에서 차이점이 있었다.

- Scale
Word token과 달리 vision에서의 visual element들은 scale에 따라 천차만별임. 즉, Transformer-based model에서의 token들은 고정된 크기 값을 갖기 때문에 vision에는 적합하지가 않았다. - Much higher resolution of pixels in images
: Self-attention의 computational complexity는 image size에 quadratic하기 때문에, 이를 극복하기 위해 hierarchical feature map을 만들고 image size에 대해 linear한 complexity를 갖는 general purpose Transformer backbone [Swin Transformer]를 제시함.
- Hierarchical feature map을 이용하여 Swin Transformer는 편리하게 FPN [Feature Pyramid Networks], U-Net 같은 dense prediction technique들과 leverage 할 수 있음
- Linear computational complexity의 경우 겹치지 않는 window들에서 local하게 self-attention 연산을 수행함으로써 얻을 수 있다. 각각의 window에서의 patch들의 개수는 고정되어 있기 때문에 complexity는 image size에 linear하게 된다.
Swin Transformer의 가장 중요한 design 요소는 연속적인 self-attention layer들 사이에서 window partition이 shift하는 것이다.
Shifted window들은 연속하는 layer의 window들을 연결해주고 connection을 만들어서 modeling power를 증가시켜준다.
결론적으로 shifted window가 sliding window 방식과 비슷한 modeling power를 가지면서 보다 훨씬 낮은 latency를 갖는다.
Related Work
CNN and variants
CNN은 standard model 역할을 했고 AlexNet의 등장으로 더 깊고 효과적인 convolutional neural architecture를 연구하는 것이 대세가 되었다.
이로 인한 결과물이 VGGNet, GoogLeNet, ResNet, DenseNet, HRNet, EfficientNet 등이 있다.
또한 depth-wise convolution과 deformable convolution 같은 개별적인 convolution layer들의 성능을 높이는 연구도 진행되고 있다.
물론 CNN based model의 성능도 좋지만, 연구원들은 Transformer의 potential에 주목을 했고 vision과 language 사이의 unified modeling을 기대했다.
Self-attention based backbone architectures
ResNet이 optimization 성능도 좋고 accuracy/FLOPs trade-off에 있어서 더 좋다는 것을 확인했지만, memory를 많이 잡아먹는다는 점이 문제점이여서 self-attention layer과 Transformer architecture에 주목하게 되었다.
Transformer based vision backbones
Swin Transformer와 가장 유사한 작업은 ViT [Vision Transformer]이다.
ViT의 pioneering work는 Transformer architecture를 non-overlapping medium-sized image patches에 적용해서 image classification을 수행했다는 점이다. ViT는 CNN과 비교했을 때 속도 측면에서 엄청난 향상을 보였다.
하지만, ViT는 제대로 수행이 되려면 training dataset이 굉장히 많이 필요하다는 단점이 존재했다. 그 뒤에 나온 DeiT가 ViT보다 적은 dataset으로 training을 하는 방법을 제시했지만, input image의 resolution이 높으면 complexity가 quadratic하게 증가하기 때문에 general-purpose backbone network로는 적합하지 않았다.
Swin-Transformer가 general-purpose backbone network로 가장 적합하다
Method
Overall Architecture
- Input RGB image를 non-overlapping patch들로 split [by splitting module like ViT]
→ 각각의 patch들은 token으로 여겨지고 이들 각각의 feature는 raw pixel RGB 값의 concatenation으로 setting됨 - Modified self-attention computation이 있는 여러 개의 Transformer block들이 이 patch token들에 적용됨
- Hierarchical representation을 만들기 위해 network가 깊어지면서 layer들을 merge함으로써 token들의 수를 줄여나감
- The first patch merging layer concatenates the features of each group of 2X2 neighboring patches, and applies a linear layer on the 4C-dimensional concatenated features
: Token의 개수가 2Xdownsampling of resolution 만큼 줄어들고 output dimension이 2C로 setting됨
- The first patch merging layer concatenates the features of each group of 2X2 neighboring patches, and applies a linear layer on the 4C-dimensional concatenated features
- Swin Transformer block들이 feature 변환 이후에 적용됨 [Resolution을 H/8 X W/8로 유지시키면서]
These stages jointly produce a hierarchical representation with the same feature map resolutions as those of typical convolutional networks such as VGG, ResNet
Swin Transformer block
Swin Transformer는 나머지는 동일하게 유지하고 기존에 있는 multi-head self attention [MSA] module을 shifted window로 바꾼 형태를 지니고 있음
이 그림에서 처럼 Swin Transformer block은 shifted window based MSA module을 갖고 있고 나머지는 기존의 Transformer와 동일함
Shifted Window based Self-Attention
The standard Transformer architecture and its adaptation for image classification both conduct global self-attention, where the relationships between a token and all other tokens are computed.
Global computation은 token의 개수에 따라 quadratic complexity를 유도할 수 있어서 많은 vision problem에 적합하기 않게 만든다. [dense prediction과 high-resolution image를 위해 어마어마한 양의 token이 필요하기 때문]
Self-attention in non-overlapped windows
Efficient modeling을 위해 self-attention을 local window 영역에서 연산을 하는 방식을 제안함.
Window들은 non-overlapping 방식으로 image를 공평하게 partition하는 방식으로 하고 MXM patch를 갖고 있음
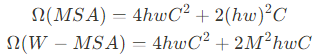
Window based self-attention is scalable
Shifted window partitioning in successive blocks
Window-based self-attention module은 window들 사이의 connection이 부족해서 modeling power에 제약이 생겨버린다.
효율적인 non-overlapping window들의 연산을 유지하면서 cross-window connection을 도입하기 위해 2개의 partitioning configuration들을 연속적인 Swin Transformer block들로 바꾼 shifted window partitioning approach를 제안함
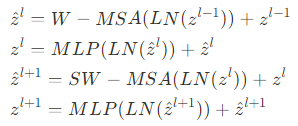
The shifted window partitioning approach introduces connections between neighboring non-overlapping windows in the previous layer
Efficient batch computation for shifted configuration
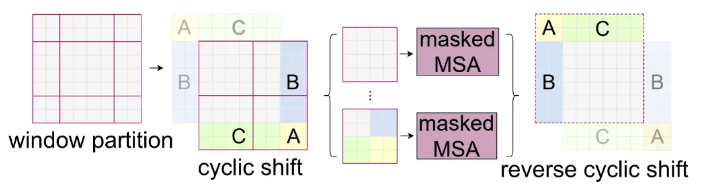
Masking mechanism is employed to limit self-attention computation to within each sub-window
Relative position bias
[Computing Self-attention]

Architecture Variants

Experiment
- ImageNet-1K : Image classification
- COCO : Object detection
- ADE20K : Semantic segmentation
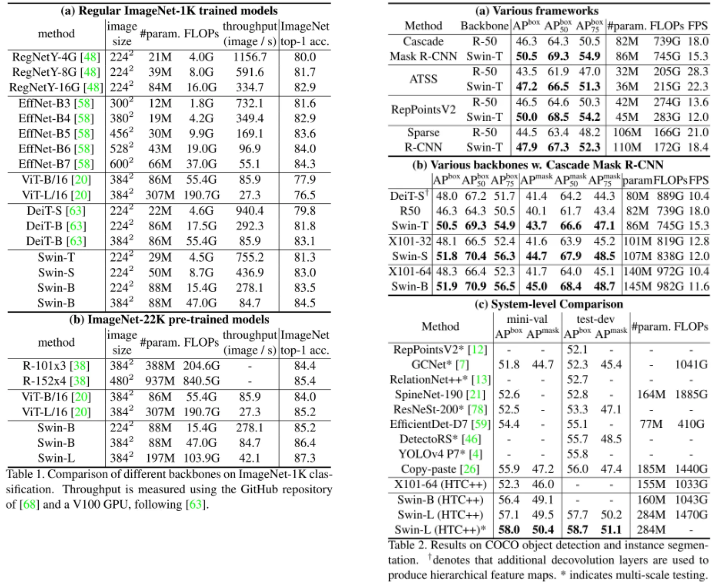
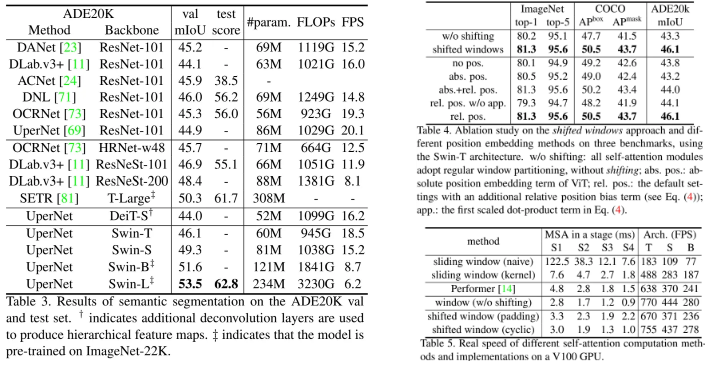
Conclusion
This paper presents Swin Transformer, a new vision Transformer which produces a hierarchical feature representation and has linear computational complexity with respect to input image size.
Swin Transformer achieves the SOTA performance on COCO object detection and ADE20K semantic segmentation, significantly surpassing previous best methods.
We hope that Swin Transformer’s strong performance on various vision problems will encourage unified modeling of vision and language signals.
As a key element of Swin Transformer, the shifted window based self-attention is shown to be effective and efficient on vision problems, and we look forward to investigating its use in NLP as well
- Computational Complexity가 Quadratic한 ViT의 단점을 Linear complexity를 갖도록 해결
- Hierarchical Architecture, Shifted Window 방식을 사용하여 Computational Complexity를 줄이고 성능을 높임
- Object Detection이나 Semantic Segmentation과 같은 분야에서 좋은 성능을 보였고, general-purpose backbone architecture로 사용할 수 있음
'Paper Review > Baseline' 카테고리의 다른 글
| [논문] Emerging Properties in Self-Supervised Vision Transformers [a.k.a DINO] | 2024.09.13 |
|---|---|
| [CV] Transformer in Computer Vision | 2024.09.11 |
| [논문] Masked Autoencoders Are Scalable Vision Learners | 2024.09.10 |