이전 Posting에서 Vision Transformer에 대해 다룬 적이 있었다.
2024.09.11 - [Paper Review] - [논문] Transformer in Computer Vision
[논문] Transformer in Computer Vision
2024.09.10 - [Paper Review] - [논문] Segmentation이번 posting에서는 NLP에서 성능이 매우 좋다는 것이 증명된 Transformer를 vision task로 가져온 논문 3편에 대해 요약을 할 것이다.ViT [Vision Transformer]https://arxiv.org
phj6724.tistory.com
이번 posting에서는 Vision Transformer에 Self-supervised learning을 적용해서 더 잘 동작하도록 한 것이다.
DINO라는 말은 "Self-distillation with no labels"에서 따왔다. 그렇기 때문에 이 논문에서 중점적으로 봐야 할 점은 no labels에서 알 수 있는 Self-supervised learning과 Self-distillation을 알아야 한다. 이번 포스팅에서는 이 내용을 중점적으로 다뤄보도록 하겠다.
먼저 논문에 대해 소개를 하자면, 이 논문은 2021년 CVPR에서 accepted된 논문이고 Meta의 전신인 Facebook research 팀에서 발표를 한 논문이다.
https://arxiv.org/abs/2104.14294
Emerging Properties in Self-Supervised Vision Transformers
In this paper, we question if self-supervised learning provides new properties to Vision Transformer (ViT) that stand out compared to convolutional networks (convnets). Beyond the fact that adapting self-supervised methods to this architecture works partic
arxiv.org
DINO and PAWS: Advancing the state of the art in computer vision
Many of the most exciting new AI breakthroughs have come from two recent innovations: self-supervised learning, which allows machines to learn from random, unlabeled examples; and Transformers, which enable AI models to selectively focus on certain parts o
ai.meta.com
Introduction
알다싶이 Transformer는 NLP에서 큰 성공을 거두고 있고, 그로 인해 Vision task에도 Transformer를 적용해보자 하고 나온 것이 Vision Transformer이다. 이는 이미지를 patch단위로 나눠서 한번에 encoder로 집어 넣기 때문에 inductive bias가 적다는 장점이 있다. 그로 인해 그 동안 visual recognition에서는 main architecture로 사용되었지만 sliding window 방식으로 인해 inductive bias가 큰 CNN을 ViT의 등장으로 인해 Transformer가 점점 대체를 하고 있는 상황이다.
하지만, Transformer에도 단점이 존재하는데 이는 연산량이 많아진다는 점과 inductive bias를 줄이기 위해 더 많은 dataset이 필요하다는 점, 그리고 feature들이 unique property를 보이지 않는다는 점이다.
그래서 이 논문에서는 Transformer가 NLP에서 성공할 수 있었던 가장 큰 이유 중 하나를 BERT의 close procedure나 GPT의 language modeling과 같은 Self-supervised pretraining이라고 보고 Self-supervised learning을 ViT로 가져오게 되었다고 한다.

연구원들은 연구를 진행하면서 supervised ViT와 CNN에서는 볼 수 없었던 여러 특성들을 확인할 수 있었다고 한다.
- Self-supervised ViT는 scene layout, 특히 object boundary에 대한 feature들을 포함하고 있다고 한다. 그리고 이 정보는 마지막 block의 self-attention 모듈에서 직접적으로 접근이 가능하다고 한다.
- Self-supervised ViT는 fine-tuning, linear classifier, data augmentation 없이도 기본적인 KNN을 잘 수행하고 ImageNet dataset에 대해 78.3%의 accuracy를 보였다고 한다.

다만, KNN이 잘 동작할 때는 momentum encoder와 multi-crop augmentation과 같은 구성요소들과 결합을 했을 때만 높은 성능을 보였다고 한다. 또한 ViT에서 image를 patch단위로 잘라서 사용한다는 점이 output feature들의 quality를 높였다는 것을 확인했다고 한다.
이러한 발견들은 "Knowledge distillation with no labels"라는 형태로 해석이 될 수 있는데, 이 framework의 output은 teacher network의 output을 직접적으로 예측함으로써 self-supervised training 과정을 조금 더 간단하게 했다고 한다.

Figure2를 보면 Self-distillation with no labels에 대한 그림이 나오고 teacher network와 student network가 주어져 있다. 이 방식에 대해 간단히 설명하자면, 단어 뜻처럼 Teacher가 Student에게 지식을 전파해주는 형태이다. 즉, Parameter가 많은 Teacher network에서 model을 training해서 compact한 Student network에 근사를 하는 방식이다. 이 방식을 통해 효율적으로 training을 시킬 수 있다고 한다. 자세한 내용은 아래 첨부한 논문을 보시면 이해가 되실겁니다.
https://arxiv.org/abs/1905.08094
Be Your Own Teacher: Improve the Performance of Convolutional Neural Networks via Self Distillation
Convolutional neural networks have been widely deployed in various application scenarios. In order to extend the applications' boundaries to some accuracy-crucial domains, researchers have been investigating approaches to boost accuracy through either deep
arxiv.org
다시 돌아와서 위의 그림을 설명하면, 이 논문에서는 이 방식으로 2개의 서로 다른 input image의 random transformation을 구조는 같지만 parameter 개수가 다른 teacher와 student network에 통과시키고, 여기서 나온 두 network의 output을 cross-entropy loss로 similarity를 측정을 한다고 한다.
Related Work
Self-training and Knowledge distillation
Self-training은 작은 초기 annotation set을 큰 unlabeled instance들의 set에 propagate함으로써 feature들의 quality를 높이는 것을 목표로 한다. 이 방식은 label을 어떻게 assign하느냐에 따라 soft와 hard 2가지 방식으로 나뉜다.
- Soft assignment (Knowledge distillation)
: 주로 model을 압축시키기 위해 작은 network가 큰 network의 output을 모방하도록 훈련시키게 설계가 되어 있다. [Self-training with noisy student improves imagenet classification] 이 논문을 보면, 저자는 soft pseudo-label들을 self-training pipeline에서 unlabeled data로 propagate해서 self-training과 knowledge distillation의 필수적인 관계를 도출했고 결과적으로 self-supervised model을 압축하고 성능 향상을 이뤄냈다고 한다. 이 점에서 착안해서 label이 없는 case에 knowledge distillation을 확장시키는 작업을 수행했다고 한다.
그러나, 이런 작업들은 pre-trained fixed teacher network에 의존하는 반면에 이 논문에서의 teacher는 fixed가 아닌 dynamic이기 때문에 knowledge distillation이 post-processing step에서 쓰이는 것이 아니라 직접적으로 self-supervised training으로 쓰일 수 밖에 없었다고 한다.
Approach
Self-Supervised Learning with Knowledge distillation
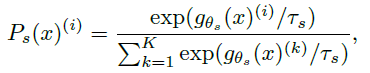
Knowledge distillation을 수식으로 표현하면 위와 같이 된다고 한다. 위 수식은 student에 대한 수식이고, teacher는 s를 t로만 바꿔주면 된다. 이 수식의 변수와 parameter들을 보면 g_theta_s 는 student network, g_theta_t는 teacher network이고 x는 input image라고 한다. tau [tau>0]은 temperature parameter라는건데 output 분포가 sharp해지는 것을 control하는 역할을 한다고 한다. 이 parameter들이 모여 마지막에 softmax를 통과하면 student에 대한 분포가 나오게 된다고 한다.
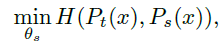
Student와 Teacher의 분포가 나오게 되면, student network의 parameter theta_s에 대해 cross-entropy loss를 구하고 있다. [ ∵ H[a,b] = -alogb ] 그 이유는 이전에 언급했었지만, Teacher와 Student의 관계에 의해 Student를 Teacher에 근사하는 과정이기 때문이다.
이제 이 식을 self-supervised learning으로 가져오기 위해 저자들은 여러 관점의 image view, crop들을 multi-crop strategy로 만들었다고 한다.
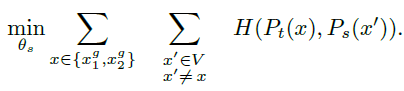
이 set은 2개의 global view [g]와 여러 local view들을 갖고 있는데, global view들만 teacher를 통과하는 동안 모든 crop들은 student를 통과해서 "local-to-global" correspondence를 형성하고 위 수식으로 loss를 최소화했다고 한다.
이 loss는 어떠한 수의 view에 상관없이 사용할 수 있다고 한다.
참고로 multi-crop에 대한 내용은 저자들이 pytorch pseudo code를 제공해서 code로 이해하기도 쉬울듯 하다

Teacher Network
Knowledge distillation과 달리 teacher가 없기 때문에 student network의 iteration 과정 중에 build를 해야 한다. 그래서 다양한 update rule에 대해 연구를 했고 epoch 동안 teacher network를 freezing하는 것이 이 논문의 framework에서 성능이 매우 높았다고 한다. 특히 위쪽 Figure2에 있는 그림에서의 EMA [Exponential Moving Average], 즉 momentum encoder가 유독 잘 들어맞았다고 한다.
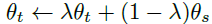
원래 momentum encoder는 contrasive learning에서의 queue의 대체재 역할을 했다고 한다. 그러나 이 논문에서의 momentum encoder는 이 논문 자체가 queue와 contrasive loss를 사용하지 않기 때문에 원래의 역할과 다르다고 한다.
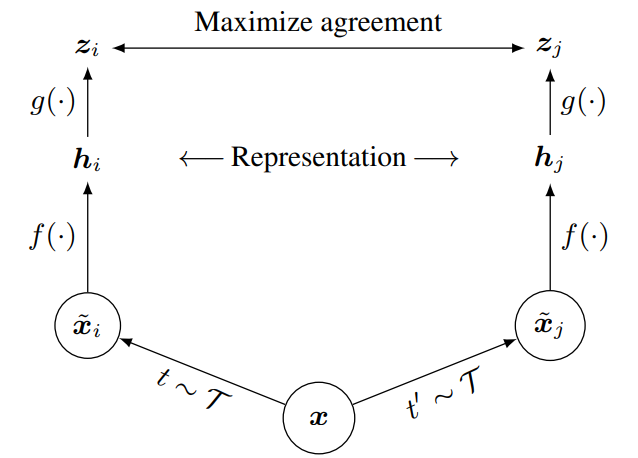
한가지 예로, SimCLR의 architecture를 보면, contrasive learning을 사용하여 학습을 하고 있다.
실제로 teacher network가 Polyak-Ruppert Averaging 기법과 비슷한 모델 앙상블의 형태를 하고 있다는 것을 발견했는데, 이에 대한 내용은 링크를 참고하길 바란다.
https://paperswithcode.com/method/polyak-averaging
Papers with Code - Polyak Averaging Explained
Polyak Averaging is an optimization technique that sets final parameters to an average of (recent) parameters visited in the optimization trajectory. Specifically if in $t$ iterations we have parameters $\theta_{1}, \theta_{2}, \dots, \theta_{t}$, then Pol
paperswithcode.com
결과적으로 Teacher가 training 전반에 걸쳐 student보다 성능이 높았기 때문에 target feature를 high quality로 student에게 guide할 수 있었다고 하고 이 방식은 이 논문에서 처음 시도한 방식이라고 한다.
Network Architecture
Neural network의 backbone은 ViT또는 ResNet으로 구성되어 있고 SwAV의 design과 유사한 3-layer MLP [hidden dim=2048, followed by l2 norm and weight normalized FC layer with K dim]를 갖고 있다.
또 이논문에서는 standard ConvNet, ViT와 달리 batch normalization을 사용하지 않는다.
Avoiding collapse
여러 self-supervised 방식들은 contrasive loss, clustering constraints, predictor, batch normalization 등을 사용하지만 DINO는 이런 것들을 일절 사용하지 않고 단지 여러 normalization만 사용을 해서 teacher의 output의 momentum을 centering하고 sharpening해서 model collapse를 방지했다고 한다.
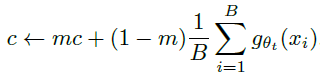
Implementation
https://arxiv.org/abs/2012.12877
Training data-efficient image transformers & distillation through attention
Recently, neural networks purely based on attention were shown to address image understanding tasks such as image classification. However, these visual transformers are pre-trained with hundreds of millions of images using an expensive infrastructure, ther
arxiv.org
저자들은 DeiT의 implementation을 사용하였다. 본 논문에서 사용한 모델들의 설정은 다음 표와 같다.
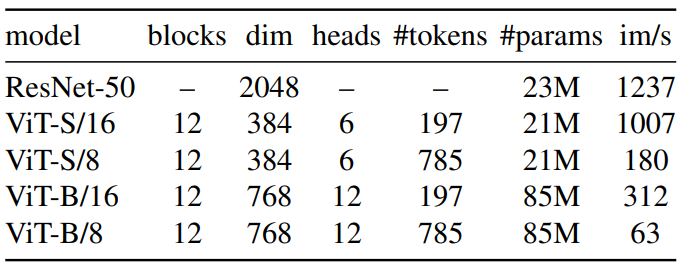
ViT 아키텍처는 겹치치 않는 연속적인 N×N의 이미지 패치를 입력으로 받는다. 본 논문에서는 일반적으로 N=16 [“/16”]이나 N=8 [“/8”]을 사용하였다. 이 패치들은 linear layer을 통과하여 임베딩이 된다.
저자들은 additional learnable token을 시퀀스에 넣어 전체 시퀀스의 정보를 집계하도록 하였으며, 출력에 projection head를 연결하였다. 이 토큰은 어떠한 레이블이나 supervision에 연결되지는 않지만 기존 연구들과의 일관성을 위해 클래스 토큰 [CLS]이라 부른다. 패치 토큰과 [CLS] 토큰은 pre-norm layer normalization을 가진 표준 Transformer network에 입력된다.
Transformer는 self-attention과 feed-forward layer의 시퀀스이며 skip connection으로 병렬화된다. Self-attention layer는 attention mechanism으로 다른 토큰 표현을 보고 각 토큰 표현들을 업데이트한다.
Implementation details
- Dataset: Pre-training with unlabeled ImageNet dataset
- Batch size=1024, Optimizer=AdamW, 16 GPUs
- Learning rate는 처음 10 epoch만 0.005batch_size/256까지 warmup 후 cosine schedule로 decay
- Weight decay: cosine schedule로 0.04에서 0.4
- 는 0.04에서 0.07로 초반 30 epoch동안 linear-warmup
- BYOL의 data augmentation [color jittering, Gaussian blur and solarization]과 multi-crop을 사용
Result
Comparing with Same Architecture
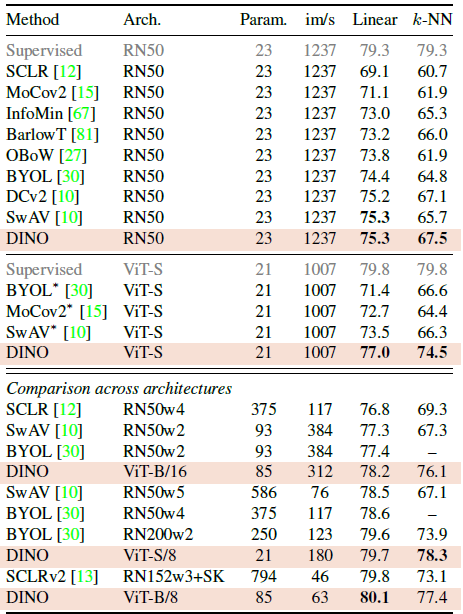
DINO를 같은 architecture를 가진 다른 self-supervised method들과 비교했을 때 ResNet-50 SOTA와 동등한 성능을 보였기 때문에 DINO가 standard setting에서 동작한다는 것을 검증했다고 한다.
ViT로 넘어가면, DINO는 BYOL, MoCov2, SwAV의 성능을 능가했고 simple k-NN classifier는 linear classifier와 거의 동등했다고 한다.
Nearest neighbot retrieval with DINO ViT
Image Retrieval
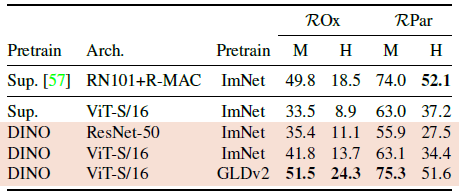
Table3에서 supervised 또는 DINO training에서 얻은 feature들의 성능을 비교하기 위해 feature들을 freeze한 뒤 retrieval을 위해 k-NN을 direct로 적용했다고 한다. 그랬더니 label을 가진 ImageNet으로 training을 한 것들보다 성능이 높게 나왔다고 한다.
이를 통해 SSL [Self-Supervised Learning]의 장점은 어떠한 annotation 없이도 dataset에 상관없이 training을 할 수 있다는 점이라는 것을 확인할 수 없다.
Copy detection
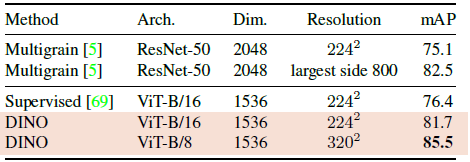
Copy detection task에서도 DINO와 ViT의 성능을 평가했다고 한다.
Discovering the semantic layout of scenes
Video instance segmentation
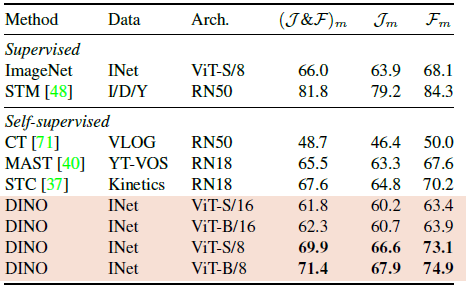
J_m은 mean region similarity, F_m은 mean contour-based accuracy이고 이 metric에 대해 DINO가 video instance segmentation task에 대해 높은 성능을 보였다고 한다.
Probing the self-attention map
다음은 서로 다른 head들이 다른 semantic region에 참여하는 것을 보여주는 그림이다.

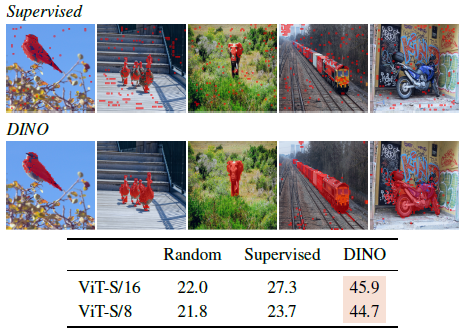
다음은 supervised와 DINO의 segmentation 결과이다. Self-attention map에 임계값을 주어 mask를 얻어 시각화한 것이다.
Transfer learning on downstream tasks
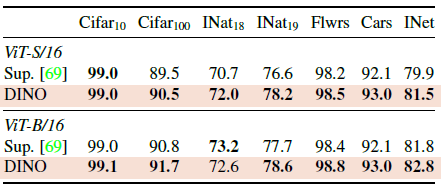
다양한 downstream task들에 대해 pre-trained DINO로 feature들의 quality를 측정한 결과이다. ViT architecture에서 self-supervised pretraining이 supervision을 갖고 train된 fearue들 보다 더 transfer를 잘 한다는 것을 알 수 있다.
Ablation Study of DINO
Importance of the Different Components
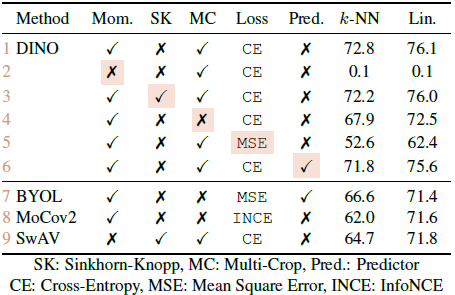
Model을 구성하고 있는 component의 유무에 대한 결과이다. 결과를 보면 가장 최선의 조합은 multicrop augmentation, cross-entropy loss와 결합한 momentum encoder라는 것을 알 수 있다.
Importance of the patch size
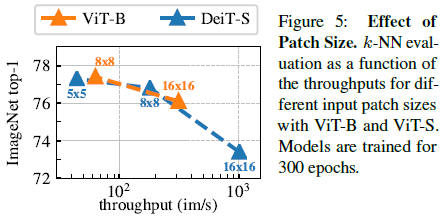
Figure 5는 다양한 패치 크기에서 ViT-S 모델의 k-NN classification 성능을 비교한 것이다. 이 그래프를 보면 x축은 throughput이고 y축이 성능인데, patch size를 줄이면 성느이 상당히 높아진다는 것을 확인할 수 있다. 이를 통해 parameter를 추가하지 않고도 patch size만 조절함으로써 성능을 높일 수 있다는 것을 알 수 있다.
Impact of the choice of Teacher Network
Building different teachers from the student & Analyzing the training dynamic
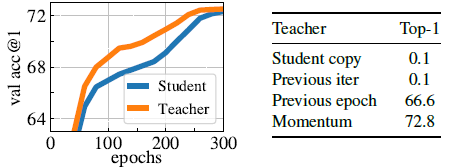
- Left : Comparison between the performance of the momentum teacher and the student during training
- Right : Comparison between different types of teacher network
왼쪽의 그래프는 epoch를 반복할 수록 accuracy가 높아지는데, student가 teacher에 점점 근사해가는 것이 보인다. 이 때 한가지 더 중요한 point는 teacher의 accuracy가 항상 student를 능가한다는 점이다.그리고 오른쪽은 teacher network의 다양한 type를 비교한 결과인데, Momentum의 성능이 제일 높은 것으로 보아 momentum encoder를 사용하는 것이 더 높은 성능을 가져다준다는 것을 알 수 있다.
Avoiding collapse
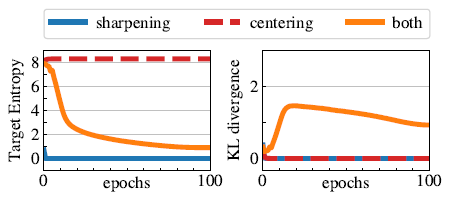
- Left : evolution of the teacher's target entropy along training epochs
- Right : evolution of KL divergence between teacher and student outputs
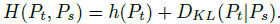
다음은 centering과 sharpening이 collapse를 피하는 것을 수행하는 역할에 대해 연구한 것이다.
Collapse에는 두 가지 형태가 있다. 하나는 입력을 무시하고 모델의 출력이 모든 차원에서 균일한 것이고, 다른 하나는 한 차원이 지배적인 것이다. Centering은 한 차원이 지배적인 collapse를 피하지만 균일한 출력을 유도하며, sharpening은 반대 효과가 나타난다.
Compute requirements
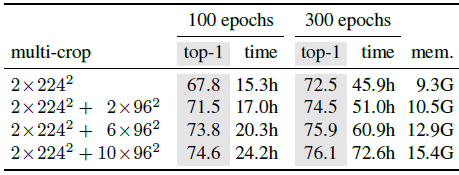
2개의 8-GPU machine에서 ViT-S/16 DINO을 실행하는 데 이정도의 시간과 GPU당 메모리가 필요하다는 것을 실험한 결과이다.
Training with small batches
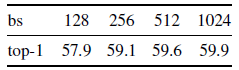
위에서 계속 batch size의 중요성을 강조하고 있는데, 위의 표는 batch size를 128부터 1024까지 4가지로 나눠서 실험을 한 결과이다. Batch size가 128일 때보다 256일 때가 약 2%의 성능 향상을 보이고 1024일 때가 가장 높은 성능을 보이는 것으로 보아 batch size가 작을 수록 quality가 높아진다는 것이 입증되었다고 볼 수 있다.
Conclusion
이 논문을 통해 저자들은 효과적으로 Self-supervised pretraining standard ViT를 제시하였고 대부분의 task에서 ConvNet보다 높은 성능을 보인다는 것을 확인했다. 특히 batch size의 중요성을 강조한 점과 Teacher/Student Network를 적용한 점이 인상적이였다.
Detection, Segmentation, Transformer, Human Pose Estimation의 흐름으로 공부를 하면서 DINO까지 오게 되었다. 기술의 발전은 너무나도 빠르고 공부해야할 건 산더미인걸 다시끔 깨닫게 해주는 논문이였다.
https://arxiv.org/abs/2301.11320
Cut and Learn for Unsupervised Object Detection and Instance Segmentation
We propose Cut-and-LEaRn (CutLER), a simple approach for training unsupervised object detection and segmentation models. We leverage the property of self-supervised models to 'discover' objects without supervision and amplify it to train a state-of-the-art
arxiv.org
학부연구생을 하면서 Paper reading을 할 때 이 논문을 공부했었는데 이 논문에서 DINO가 많이 쓰여서 DINO를 읽고 이 논문을 읽으면 이해가 더 잘될 것 같다.
https://dinov2.metademolab.com/
DINOv2 by Meta AI
A self-supervised vision transformer model by Meta AI
dinov2.metademolab.com
그리고 DINOv2도 벌써?나와서 읽어야 할 논문이 추가되었다...

그리고 이 괴상한건 Imagenet class들에 대해 t-SNE로 visualization을 한 결과라고 한다. 각각의 class에 대해 validation set에서 image의 class feature들의 평균을 내서 embedding하면 이렇게 된다고 한다.
'Paper Review > Baseline' 카테고리의 다른 글
| [논문] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows (0) | 2024.11.06 |
|---|---|
| [CV] Transformer in Computer Vision (5) | 2024.09.11 |
| [논문] Masked Autoencoders Are Scalable Vision Learners (2) | 2024.09.10 |