https://shunsukesaito.github.io/PIFu/

Abstract
What if PIFu?
An implicit representation that locally aligns pixels of 2D images with the global context of their corresponding 3D object
→ End-to-End deep learning method for digitizing highly detailed clothed humans that can infer both 3D surface and texture
- 매우 복잡한 shape [hairstyles, clothing …] 뿐만 아니라 이것들의 변화나 변형도 unified way로 digitize할 수 있다
- PIFu는 사람의 등과 같이 안보이는 영역도 high-resolution으로 생성해낼 수 있다.
- voxel representation과 달리 memory efficient하다
Voxel - Wikipedia
From Wikipedia, the free encyclopedia Element representing a value on a grid in three dimensional space A set of voxels in a stack, with a single voxel shaded Illustration of a voxel grid containing color values A voxel is a three-dimensional counterpart t
en.wikipedia.org
- PIFu는 임의의 view에도 확장가능하다 [view의 숫자에 상관하지 X]
[이전의 기법들은 single-view나 multiple-view 둘 중 하나만 했다] - Public benchmark에서 SOTA 성능을 달성했고 single image에서 옷을 입은 사람을 digitize하는 이전의 작업들을 능가했다
Introduction
Digitize and Understand 3D objects in the wild
3D Object를 digitizing하는게 사진찍는 것 처럼 쉬웠다면 3D scanning 장비, multi-view stereo algorithm 같은 기법들은 생겨나지도 않았을 것이다.
그래도 Domain-specific object [Face, Human bodies]의 경우 parametric model들이나 data-driven technique, deep neural network 등의 도움으로 image 몇장이나 심지어는 1개의 image만으로도 정확한 3D surface의 추론이 가능했었다
하지만, 이 마저도 비효율적인 model representation 때문에 resolution과 accuracy 측면에서는 한계점이 보였다
그래서 이 논문에서는 새로운 기법인 Pixel-Aligned Implicit Function [PIFu]를 제시했다
We propose a new PIFu representation for 3D deep learning for the challenging problem of textured surface inference of clothed 3D humans from a single or multiple input images
대부분의 2D image processing에서 성공한 deep learning 기법은 Semantic segmentation [FCN]이나 2D joint detection 같은 방식인데 여기서는 fully-convolutional network를 사용해서 image와 output의 spatial alignment를 보존했다. 하지만 이 방식을 3D로 가져오기에는 한계점이 존재했다.
Voxel representation에는 fully-convolutional network를 적용할 수는 있지만, memory를 상당히 많이 잡아먹기 때문에 PIFu는 다른 방식으로 접근하게 되었다고 한다
PIFu aligns individual local features at the pixel level to the global context of the entire object in a fully convolutional manner, and does not require high memory usage
아마 옷을 입은 대상의 3D reconstruction 때문일텐데 이 사람들의 형태가 무작위적인 topology이고 크게 변형이 가능하고 디테일하기 때문일 것이다.
이전의 방식의 경우 local feature들은 이용하지만 3D-aware feature fusion mechanism이 없기 때문에 single-view에서 3D shape를 추론하지 못한다. 이 방식의 경우 local feature들과 3D-aware implicit surface representation을 합쳐서 single view에서도 매우 detail한 reconstruction이 가능해졌다고 한다.
특히 저자들은 encoder가 image의 pixel들 [per-pixel]에서 각각의 feature vector를 학습하도록 training 시켰는데 이는 encoder가 global context를 고려할 수 있게 만들었다고 한다.
그래서 이 per-pixel feature vector와 outgoing camera ray로 specified된 z-depth로 z-depth와 관련된 3D point가 surface의 내부인지 외부인지를 구별할 수 있는 implicit function을 학습할 수 있었다고 한다. 이 feature vector의 경우 특히 global 3D surface shape를 pixel에 align하는데 이 과정에서 unseen region의 물체를 추론할 때도 input image에 있는 local detail을 보존할 수 있게 된다고 한다.
단순히 implicit function을 RGB 값을 회귀하는데 사용함으로써 PIFu는 per-vertex color를 추론하는 영역까지 사용이 가능했다고 한다. 이를 통해 PIFu가 surface의 완전한 texture를 생성할 수 있었다고 한다. 또한 PIFu는 multi-view stereo constraint를 통해 여러 input image를 다룰 수 있고, single input image에서는 이미 가능했던 완전한 textured mesh를 만들어내는 것에 더해 view를 추가하는 것 만으로 unseen region에 대한 정보를 향상시킬 수 있었다고 한다.
Related Work
Single-View 3D Human Digitization
Single-view digitization technique는 문제의 모호한 특성 때문에 강한 prior를 요구한다. 따라서 human body의 parametric model들이 input image에서 사람을 digitizing하기 위해 주로 사용되어 왔다. 실루엣이나 다른 유형의 manual annotation들이 body model을 initialize하기 위해 사용했었다.
- 다음 논문에서 unconstrainted input data에 대한 fully automated pipeline을 제시했다.
“Automatic estimation of 3D human pose and shape from a single image” - 최근의 방식들은 deep neural network를 매우 challenging한 image의 pose와 shape parameter들의 robustness를 향상시키기 위해 사용했다.
- Part Segmentation을 사용한 방식은 더 정확한 fitting을 만들어낸다.
이 방식들이 human body measurements와 motion들을 capture할 수 있지만, parametric model들은 hair나 accessory같은 detail 것들은 제외하고 오로지 맨몸을 만들어내는 것에 국한되어 있었다.
이 문제를 해결하기 위해 BodyNet 같은 template-free method들을 학습시켜서 직접적으로 deep neural network가 사람의 voxel representation을 생성하도록 했다. Voxel representation이 memory usage가 굉장히 높기 때문에 fine-scale detail은 memory 사용량을 줄이기 위해 무시될 수 밖에 없었다.
이에 반해 PIFu의 경우 memory 효율이 좋고 per-vertex color를 예측하면서 image의 fine-scale detail들을 파악할 수 있다고 한다.
Multi-View 3D Human Digitization
Multi-view acquisition method는 사람의 전체적인 모습을 생성하고 reconstruction 문제를 간단히 만들기 위해 설계되었지만, studio setting에서만 가능하고 calibrated sensor들이 필요하다는 단점들이 있다.
- visual hull [여러 view들로 부터 실루엣을 가져와서 포착한 volume의 visible area를 깎아내는 방식]에 의존하는 여러 기법들의 경우 reasonable reconstruction은 카메라를 많이 쓰면 가능하지만 오목한 부분은 다루기가 어렵다는 문제점이 있다.
https://en.wikipedia.org/wiki/Visual_hull
Visual hull - Wikipedia
From Wikipedia, the free encyclopedia Silhouette cones Visual hull A visual hull is a geometric entity created by shape-from-silhouette 3D reconstruction technique introduced by A. Laurentini. This technique assumes the foreground object in an image can be
en.wikipedia.org
- 더 정확한 geometry는 multi-view stereo constraints를 사용하거나 controlled illumination [multi-view photometric stereo technique]를 사용함으로써 얻어질 수 있었다.
- Digitization process를 더 멀리 guide하기 위해 여러 방법들에서 parametric body model들을 사용했다.
- Motion cue들의 사용은 additional prior들에도 소개가 되었다
- Multi-view capture technique이 single-view 보다는 더 성능이 좋다는 것은 명백하지만, flexible하지 않고 deploy가 어렵다는 단점이 존재한다.
- Middle ground solution은 deep learning framework를 사용해서 매우 sparse한 view에서도 그럴듯한 3D surface를 생성하도록 했다
- 다음 논문에서 임의의 view에서 object의 3D voxel representation을 예측하도록 3D convolutional LSTM을 training 시켰다고 한다.
“3d-r2n2: A unified approach for single and multi-view 3d object reconstruction”
다만, 이 모든 방식들은 voxel representation을 사용하는데, 이전에도 많이 언급되었지만 memory intensive하고 high-frequency detail들을 포착하지 못하게 한다.
Texture Inference
Single image에서 3D model을 reconstruct할 때 texture는 쉽게 input으로 부터 sampling 될 수 있다.
하지만, 가려진 부분의 모습은 완전한 texture를 얻기 위해서는 inferring 과정이 필요하다.
- 다음 논문에서 clothed human body의 texture mesh의 context를 inference하기 위해 앞쪽의 모습으로 뒷모습을 예측하는 view synthesis 기법을 제시했다고 한다. 앞쪽의 view와 뒷쪽의 view 모두 final 3D mesh의 texture를 표현하기 위해 사용되었지만, self-occluding region과 side view는 다뤄질 수 었었다.
“Siclope: Silhouette-based clothed people" - Image impainting 문제에 취약했기 때문에 다음 논문에서는 detect된 surface point들의 output으로 부터 sampling된 UV image들을 impaint했다고 한다.
“Dense pose transfer” - 그리고 다음 논문들에서 per voxel color들을 infer했지만, output resolution이 매우 한정적이였다고 한다.
“Multi-view supervision for single-view reconstruction via differentiable ray consistency” ”Hierarchical surface prediction for 3d object reconstruction” - 다음 논문에서는 RGB image를 UV parameterization 환경에서 직접적으로 예측을 했지만, 이 방식의 경우 알려진 topology에서만 shape를 다룰 수 있었고 clothing에는 적합하지 않았다.
"Learning category-specific mesh reconstruction from image collections"
이 논문 [PIFu]에서 제시한 방식은 per vertex color를 end-to-end 방식으로 예측할 수 있고 임의의 topology에서도 다룰 수 있다고 한다.
PIFu: Pixel-Aligned Implicit Function
주어진 Single/Multi view image에서 우리의 목표는 주어진 3D geometry, clothed human의 texture를 image에 주어진 detail을 보존하면서 reconstruct하는 것이다.
제시된 pixel-aligned implicit function의 경우 fully convolutional image encoder g와 MLP에 의해 제안된 continuous implicit function f로 이뤄져 있다.

Pixel-aligned feature F(x)의 경우 X의 2D projection이 discrete space가 아니라 continuous space에서 정의 되었기 때문에 bilinear sampling을 사용했다고 한다.
여기서 주목해야할 점은 global feature보다 pixel-aligned image feature를 사용하기 위해 3D 공간에서 implicit function을 학습했다는 점이다. 이를 통해 image에 제시된 local detail을 보존할 수 있었다고 한다.
또한 PIFu의 continuous nature가 memory efficient한 방식에서 임의의 topology를 갖는 detail한 geometry를 만들 수 있게 해줬다고 한다.
Digitization Pipeline
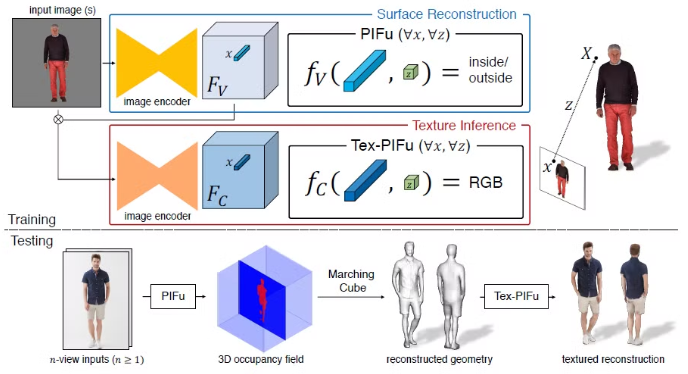
주어진 image에서 PIFu의 surface reconstruction 부분은 clothed human의 continuous inside/outside probability field를 예측하고, texture inference [Tex-PIFu] 부분은 surface geometry의 3D position에서의 RGB 값을 output으로 전달한다. 이를 통해 self-occluded surface 영역에서 texture inference가 가능해지고 임의의 topology의 shape도 유추가 가능하다고 한다.
Single-view Surface Reconstruction

이 식을 최소화하는 과정을 통해 image encoder g와 PIFu f_v의 parameter들은 jointly updated된다고 한다.
Inference 과정 동안 3D space에서 probability field를 dense하게 sampling한 다음 Marching Cube algorithm을 사용해서 threshold가 0.5를 넘는 영역에 대해 iso-surface를 추출한다고 한다.
https://en.wikipedia.org/wiki/Marching_cubes
Marching cubes - Wikipedia
From Wikipedia, the free encyclopedia Computer graphics algorithm Head and cerebral structures (hidden) extracted from 150 MRI slices using marching cubes (about 150,000 triangles) Marching cubes is a computer graphics algorithm, published in the 1987 SIGG
en.wikipedia.org
Spatial Sampling
Training data의 resolution은 implicit function의 expressiveness와 accuracy를 달성하는데 중요한 역할을 한다고한다. Voxel-based method와는 달리 PIFu는 ground truth 3D mesh들의 discretization을 요구하지 않는다.
그 대신, 효율적인 ray tracing algorithm을 사용해서 원본 resolution에서의 ground truth mesh로 부터 3D point들을 직접적으로 sampling할 수 있다. 이 방식의 경우 빈틈없는[water-tight] mesh들을 요구하는데, water-tight하지 않는 경우 mesh를 water-tight하게 만들기 위해 off-the-shelf solution을 사용할 수 있다고 한다.
https://en.wikipedia.org/wiki/Ray_tracing_(graphics)
Ray tracing (graphics) - Wikipedia
From Wikipedia, the free encyclopedia Rendering method This recursive ray tracing of reflective colored spheres on a white surface demonstrates the effects of shallow depth of field, "area" light sources, and diffuse interreflection. (c. 2008) In 3D comp
en.wikipedia.org
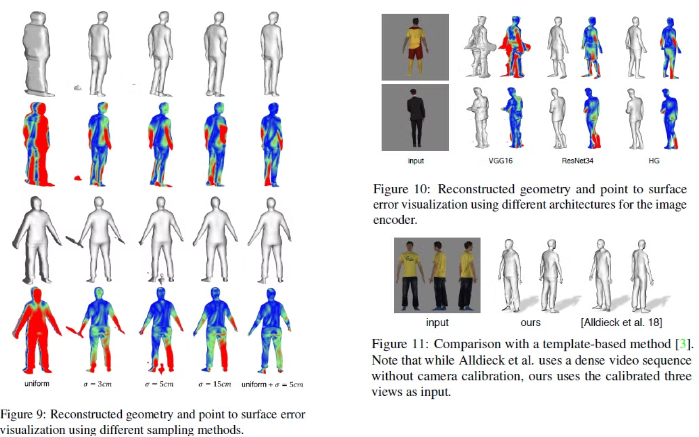
Sampling 전략이 최종 reconstruction policy에 큰 영향을 준다는 것을 발견했다고 한다.
만약 3D 공간에서 point들을 균일하게 sampling 했다면, 대부분의 point들은 iso-surface에서 멀 것이고 iso-surface 주변에서만 sampling을 했다면 overfitting이 될 가능성이 커진다고 한다.
따라서 이 논문에서는 첫번째 방식인 uniform sampling과 두번째 방식인 adaptive sampling을 결합한 방식을 제안했다.
- Surface geometry에서 random하게 point들을 sampling하고 surface 주변의 position을 방해하기 위해 x, y, z 좌표에 normal distribution을 따르는 offset을 더해준다
- 그 뒤 이 sample들을 16:1 비율의 bounding box안에서 uniform하게 sampling해준다
Texture Inference
Texture inference는 보통 surface의 2D parameterization이나 view-space에서 진행이 되지만, PIFu는 직접적으로 f(F(x),z(X))=s 식에서의 s를 정의함으로써 surface geonetry의 RGB color를 예측할 수 있게 해주었다.
이 부분이 arbitrary topology와 self-occlusion을 갖는 shape들의 texturing에 도움을 준다고 한다. 그러나 PIFu를 color prediction으로 확장을 하면 RGB color들이 3D occupancy field가 전체 3D 공간을 넘어서 정의가 되어있다는 점으로 인해 non-trivial task가 된다.
따라서 이 부분을 고려하기 위해 PIFu에서 일부분을 수정했다고 한다.

f_c를 loss function 만으로 naive하게 training을 하는 것은 overfitting이 생길 수 밖에 없다고 한다. 그 이유는 f_c가 surface의 RGB color를 학습하는 것 뿐만아니라 f_c가 inference 동안 다른 pose와 shape를 갖는 unseen surface의 texture를 추론할 수있게 하기 위해 object의 3D surface를 underlining하는 과정도 포함되어 있기 때문인데, 이 과정이 상당한 난이도가 존재한다고 한다.
이를 해결하기 위해 다음의 내용들을 수정했다고 한다.
- surface reconstruction F_V를 위해 image feature들로 학습된 image encoder를 조정했다
→ 이 방식으로 image encoder는 unseen object들이 다른 shape, pose, topology를 갖고 있어도 주어진 geometry의 color에만 focus할 수 있었다고 한다. - offset epsilon를 surface point에 적용해서 color가 exact surface 뿐만 아니라 주변의 3D space에서도 정의되게 했다.
이 내용을 반영하면,
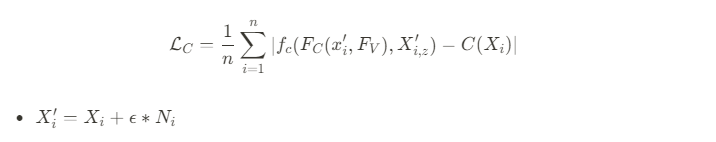
Multi-view Stereo
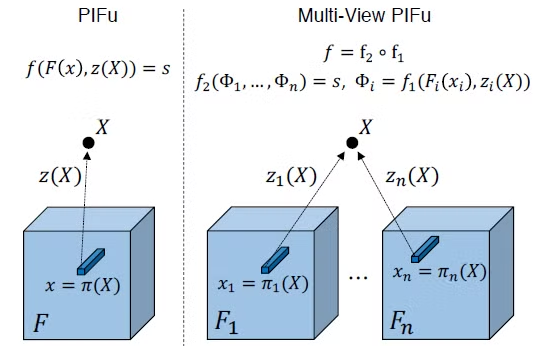
여러 view로 보면 당연하게도 coverage가 넓어지기 때문에 digitization accuracy가 높아질 수 밖에 없다. PIFu의 formulation은 surface reconstruction과 texture inference 모두에서 더 많은 view들을 합칠 수 있는 option을 제공해주었다.
특히, 이 논문에서는 pixel-aligned function f를 feature embedding network f_1과 multi-view reasoning network f_2로 decompose 했다고 한다.
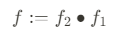

The additive nature of the latent embedding allows us to incorporate arbitrary number of inputs
주목할 점은 single-view input의 경우 average operation이 단순히 원래의 latent embedding을 return하기 때문에 같은 framework에서 수정 할 필요 없이 사용할 수 있다는 점이다.
Training을 하기 위해서는 이전에 언급된 loss function과 point sampling scheme을 포함한 single-view case들의 training 과정을 이용한다.
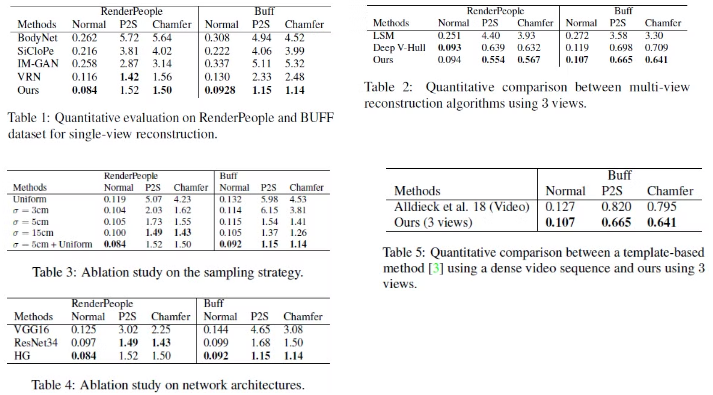
Experiment
Dataset은 ground truth measurement를 갖고 있는 RenderPeople, BUFF와 다양한 종류의 complex clothing을 갖고 있는 DeepFashion을 사용했다고 한다.
Implementation Detail
PIFu의 framework는 특정한 network architecture에 국한되어 있지 않기 때문에 fully convolutional neural network를 image encoder로 사용할 수 있다.
Surface reconstruction을 위해서 stacked hourglass architecture가 real image를 일반화 하는 것에 효율적이라고 하고, texture inference 과정에서는 residual block을 갖고 있는 CycleGAN을 채택했다고 한다.
https://arxiv.org/abs/1603.06937
Stacked Hourglass Networks for Human Pose Estimation
This work introduces a novel convolutional network architecture for the task of human pose estimation. Features are processed across all scales and consolidated to best capture the various spatial relationships associated with the body. We show how repeate
arxiv.org
https://junyanz.github.io/CycleGAN/
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks In ICCV 2017 Abstract Image-to-image translation is a class of vision and graphics problems where the goal is to learn the mapping between an input image and an output image us
junyanz.github.io
Implicit function은 layer들이 image feature F(x)로 부터 skip connection들을 갖고 있고 효율적으로 depth 정보를 propagate할 수 있는 depth z를 갖고 있는 MLP에 기초한다고 한다.
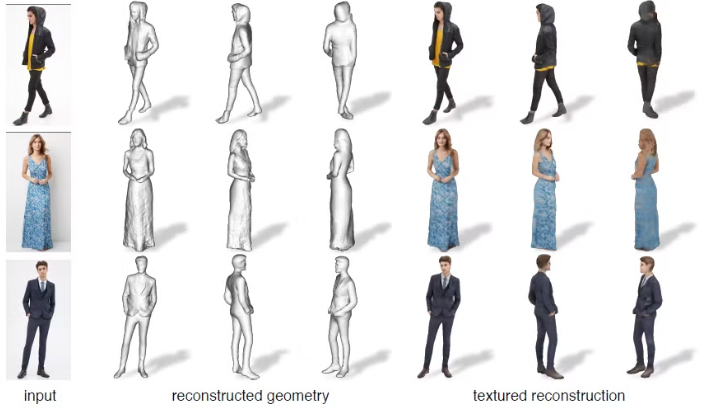
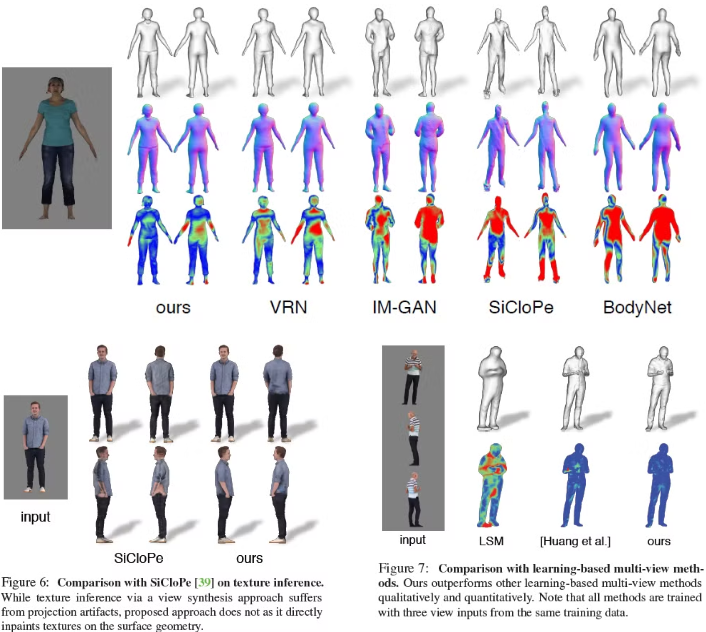
Result
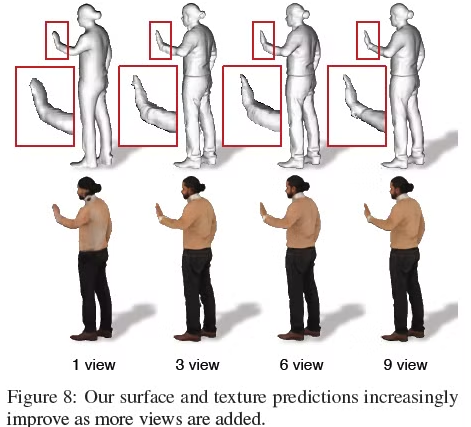
Appendix
Implementation Detail
Experimental Setup
High-resolution cothed human에 대한 large scale dataset이 없기 때문에 일일히 491개의 다양한 clothing, shape, pose를 갖는 high-quality textured human mesh를 모았다고 한다. 이 dataset을 High Fidelity Clothed Human Dataset이라고 부르기로 했다고 한다.
저자들은 무작위로 dataset에서 training/test로 442:49로 나눴다고 한다. 또한 효율적으로 digital human을 rendering하기 위해 Lambertian diffuse shading도 사용했다고 한다.
하지만 이 과정에서 real image를 high-fidelity reconstruction 하기 위해서는 synthetic rendering이 ambient occlusion 같은 global, local geometric property들에 의한 light transport effect를 올바르게 시뮬레이션할 필요가 있다는 것을 찾아냈다고 한다. 이를 위해 spherical harminics를 사용해 surface에서 visibility를 미리 구하고 spherical harmonics와 illumination, visibility의 coefficient를 연산하는 과정으로 global light transport effect를 표현하는 precomputed radience transfer technique (PRT)를 사용해서 해결하려고 했다고 한다.
PRT는 object 당 1번만 계산하면 되고 임의의 illumination과 camera angle에 대해 재사용할 수 있다는 장점이 존재한다.
Network Architecture
PIFu의 framework가 어떤 특정한 network architecture에 국한되어 있는 것이 아니기 때문에 fully convolutional neural network를 image encoder로 사용할 수 있다는 말을 위해서 했다.
- Surface reconstruction을 하기 위해서 stacked hourglass network를 사용하고 batch size가 작을 때 training stability를 향상시키는 group normalization을 사용했다.
- Texture inference 과정에는 6개의 residual block들을 갖고 있는 CycleGAN을 사용했다.
- Surface reconstruction을 위한 PIFu는 MLP에 기반하고 있는데 neuron의 개수가 sigmoid activation을 사용한 마지막 layer를 제외하고 leaky ReLU를 사용한 non-linear activation을 가진 [257,1024,512,256,128,1]개라고 한다.
- Depth 정보를 효과적으로 전달하기 위해 MLP의 각각의 layer는 image feature F(x)와 depth z로부터 skip connection들을 갖고 있다.
- Multi-view PIFu를 위해 다른 view들에서 embedding을 합치기 위해 4개의 output layer를 사용하고 average pooling을 사용했다.
- Tex-PIFu F_C(x)는 MLP의 첫 번째 뉴런의 개수를 257 대신 513으로 해서 surface reconstruction F_V(x)을 image feature와 진행했고, 이 논문에서 PIFu의 마지막 3개 layer를 RGB 값을 표현하기 위해 tanh activation을 사용했다고 한다.
Training procedure
- Texture inference module이 surface reconstruction으로 부터 pretrained된 image feature를 요구하기 때문에 PIFu를 surface reconstruction을 위해 먼저 training하고 나중에 pretrained image feature F_V를 이용해서 texture inference를 했다고 한다.
- 이 논문에서는 surface reconstruction을 위해 RMSProp를 사용했고, texture inference에서는 Adam과 learning rate 1*10^{-3}, batchsize 3과 5, epoch은 12와 6, 그리고 sampled point의 개수는 모든 training batch 각각마다 5000또는 10000개의 sampled point를 사용했다고 한다.
- RMSProp의 learning rate decay는 10번의 epoch마다 0.1씩 decay된다고 한다.
- Multi-view PIFu는 single-view surface reconstruction과 texture inference를 위해 2 epoch, learning rate 1*10^{-4}로 training된 뒤 model에 따라 fine-tuning되었다고 한다.
- single-view surface reconstruction과 texture inferenece는 1080ti GPU 1개만을 사용했을 때 4+2=6일이 걸렸고, multi-view PIFu로 fine-tuning을 했을 때는 1일 안으로 걸렸다고 한다.