HumanSplat: Generalizable Single-Image Human Gaussian Splatting with Structure Priors
Despite recent advancements in high-fidelity human reconstruction techniques, the requirements for densely captured images or time-consuming per-instance optimization significantly hinder their applications in broader scenarios. To tackle these issues, we
arxiv.org
HumanSplat: Generalizable Single-Image Human Gaussian Splatting with Structure Priors
Despite recent advancements in high-fidelity human reconstruction techniques, the requirements for densely captured images or time-consuming per-instance optimization significantly hinder their applications in broader scenarios. To tackle these issues, we
humansplat.github.io
Abstract
최근 high-fidelity human reconstruction technique의 발전에도 불구하고, densely captured image에 대한 요구사항이나 instance별로 수행되는 최적화가 시간이 오래걸린다는 점은 더 광범위한 분야로의 적용을 방해하게 된다.
이를 해결하기 위해 generalizable한 방식으로 하나의 input image에서 임의의 사람에 대한 3DGS property를 예측하는 HumanSplat을 제안하게 되었다고 한다.
특히, HumanSplat을 2D Multi-view diffusion model, geometric prior과 semantic feature를 하나의 framework에서 결합하는 human structure prior를 받는 latent reconstruction Transformer로 구성이 되어 있다.
Human semantic feature들을 합치는 hierarchical loss는 high-fidelity texture modeling을 가능하게 하였고, 추정된 multiple view에서 더 강한 constraint를 부여한다. 이를 통해 HumanSplat은 photorealistic novel-view synthesis 분야에서 SOTA를 달성했다고 한다.
Introduction
Realistic 3D human reconstruction은 다양한 분야에 적용할 수 있는 Computer vision 분야의 근본 task이다. Single-image로 human reconstruction을 하는 이전 연구들은 크게 explicit/implicit 접근법으로 구분할 수 있다.
- Explicit methods
: SMPL 같은 parametric body model에 기반을 두고 있고 parameter와 clothing offset을 직접적으로 최적화해서 observer image에 맞춰가는 방식을 사용한다. 하지만, 이 방식들은 복잡한 옷 스타일에는 어려움을 겪고 최적화 시간이 오래걸린다는 단점이 있다. - Implicit methods
: Implicit method는 human을 SDF [Signed Distance Function], NeRF 같은 continuous function으로 표현을 한다. 이 방식의 경우 flexible한 topology를 modeling 하기에는 좋지만, training과 inference 과정의 높은 연산량이 확장성과 효율성의 발목을 잡는다. - 3D Gaussian Splatting
: 3DGS는 효율성과 렌더링 퀄리티의 밸런스를 잡은 획기적인 접근 방식이다. 하지만, multi-view image나 monocular video로 구성된 input에 의존한다는 단점이 있다. - Score Distillation Sampling [SDS]
: 최근의 human reconstruction 연구들은 SDS를 통해 2D diffusion prior를 3D로 올리는 접근 방식을 사용하고 있다. 하지만, 이 방식은 각각의 instance에 대한 최적화가 시간이 오래걸린다는 단점이 있다. - Generealizable and large-reconstruction-model-based works
: 이 방식의 경우 3D representation의 regression을 직접적으로 일반화하지만, human prior를 무시하거나 multi-view input을 요구하기 때문에 확정성과 안정성, downstream task로의 적용 가능성을 낮추게 된다.
본 논문에서는 finetuning 시킨 2D multi-view diffusion model을 결합시킨 generalizable Gaussian Splatting framework와 3D human structure prior를 함께 사용하여 single-image human reconstruction을 하고자 하였다. 기존의 human 3DGS 방식과 달리 humansplat은 하나의 input image로부터 직접적으로 Gaussian property들을 유추해서 instance마다 최적화를 할 필요가 없어지고 dense하게 capture한 image도 필요가 없어지게 된다.
The key insight behind our method is to reconstruct Gaussian properties from the diffusion latent space in a generalizable end-to-end architecture, integrating a 2D generative diffusion model as appearance prior and a human parametric model as structure prior
- Leverage a 2D multi-view diffusion model [a.k.a novel-view synthesizer]
: Hallucinate the unseen parts of clothed humans
→ Clothed human의 보이지 않는 부분을 그럴싸 하게 복원함 - Generalizable latent reconstruction Transformer
: Enable interaction among the generated diffusion latent embeddings and the geometric information of the structured human model, enhancing the quality of 3DGS reconstruction
→ Diffusion으로 생성한 latent embedding과 SMPL에서 얻은 human model의 structure prior 간의 interaction을 통해 3DGS로 생성한 결과물의 퀄리티를 높임 - Projection strategy
: Mitigate the limitations of inaccurate human priors like the SMPL model to strike a balance between robustness and flexibility
→ SMPL 같은 human prior가 robustness와 flexibility 간의 밸런스를 맞춰서 부정확함을 줄임 - Projection-aware attention
: Projecting 3D tokens into the 2D space and conducting searches within adjacent windows
→ 3D token들을 2D space로 투영하는 projection-aware attention 기법을 사용하였고, window를 사용해서 인접한 영역 구간에서 탐색을 진행함
Human reconstruction에서 또 다른 어려운 작업은 얼굴이나 손 같이 visually sensitive한 부분에 대한 detail을 포착하는 것이다. 이를 해결하기 위해 structure prior로 부터 semantic cue들을 활용하고 semantics-guided objectives를 제안해서 fine detail에 대한 reconstruction quality를 더 좋게 만들었다고 한다.
이런 요소들이 시너지를 잘 발휘하도록 하나의 framework로 결합하여 quality와 efficiency 측면에서 향상을 이뤄냈다고 한다.
Contribution
- We propose a novel generalizable human Gaussian Splatting network for high-fidelity human reconstruction from a single image. To the best of our knowledge, it is the first to leverage latent Gaussian reconstruction with a 2D generative diffusion model in an end-to-end framework for efficient and accurate single-image human reconstruction.
- We integrate structure and appearance cues within a universal Transformer framework by leveraging human geometry priors from the SMPL model and human appearance priors from the 2D generative diffusion model. Geometric priors stabilize the generation of high-quality human geometry, while appearance prior helps hallucinate unseen parts of clothed humans.
- We enhance the fidelity of reconstructed human models by introducing semantic cues, hierarchical supervision, and tailored loss functions. Extensive experiments demonstrate that our method achieves state-of-the-art performance, surpassing existing methods.
Method
Preliminary

Overview

주어진 human body single input image I에 대해 본 논문의 task는 3D representation을 복원하는 것이다. 위의 overview를 보면 알 수 있듯이 method는 2D diffusion model과 novel latent reconstruction Transformer를 leverage해서 2D appearance prior, human geometric prior, semantic cue들을 하나의 framework에서 leverage하는 것이다.
- SMPL estimator를 사용해서 human structure prior M을 예측하고 CLIP을 이용해서 input image c에 대한 image embedding을 만들어낸다.
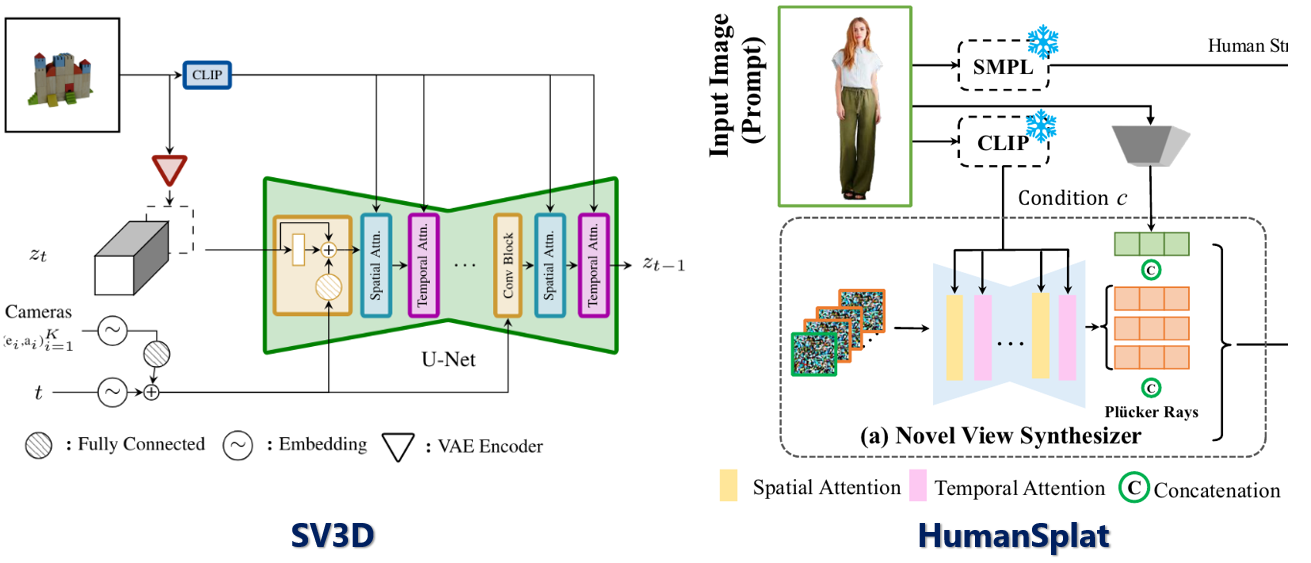
- Latent temporal-spatial spatial model [novel-view synthesizer]는 fine-tuning 되어 있고 multi-view latent feature F_i을 만들어 낸다.
- 그 뒤, novel latent reconstruction Transformer를 이용해서 human geometric prior와 latent feature 들을 하나의 framework에서 결합해서 Gaussian attribute $G$를 예측하고 새로운 image로 rendering 한다.
- High-fidelity texture momdeling을 얻고 예측된 multiple view를 더욱 잘 제어하기 위해 hierarchical loss를 제안해서 human semantic prior를 결합했다.
주목할 점은, training 동안 network는 3D scan data로 training 되어 SMPLify의 multi-view version에 fitting되고, Inference 동안 model은 PIXIE를 이용해서 human structure prior M을 예측하고 어떠한 fine-tuning이나 optimization 없이 학습시킨 model 만을 기반으로 하나의 input image에 대해 novel-view synthesis를 수행한다.
Video Diffusion Model as Novel-view Synthesizer
본 논문에서는 pre-trained video diffusion model SV3D를 appearance prior로 이용을 했다. Input image I_0에 대해 CLIP image encoder와 pre-trained VAE epsilon을 leverage해서 image embedding c와 latent feature F_0를 condition으로 얻었다고 한다.
이어 gaussian noise를 temporal UNet $D_\theta$와 objective로 temporal-continuous한 N개의 multi-view latent feature F_i를 점진적으로 denoising 했다고 한다. 그렇게 하면 식은 아래와 같이 된다.

SV3D가 단지 dataset에 대해 pre-train만 되어 있기 때문에 human dataset을 이용해 fine-tuning을 시키고 이 method의 human reconstruction task에 대한 효율성을 높였다고 한다.
SV3D
SV3D는 Stable Video Diffusion model로 single image를 input으로 주었을 때 보이지 않는 옆과 뒤를 hallucinate해서 마치 원래 이랬던 것처럼 3차원으로 복원하는 모델이다.

전체 pipeline을 보면 위와 같고, 조금 더 detail하게 들어가면 coarse-to-fine 학습 방식을 이용하여 NeRF를 학습시킨 뒤 Marching cube algirithm으로 mesh를 입혀서 최종결과물을 얻게 된다는 것을 알 수 있다.
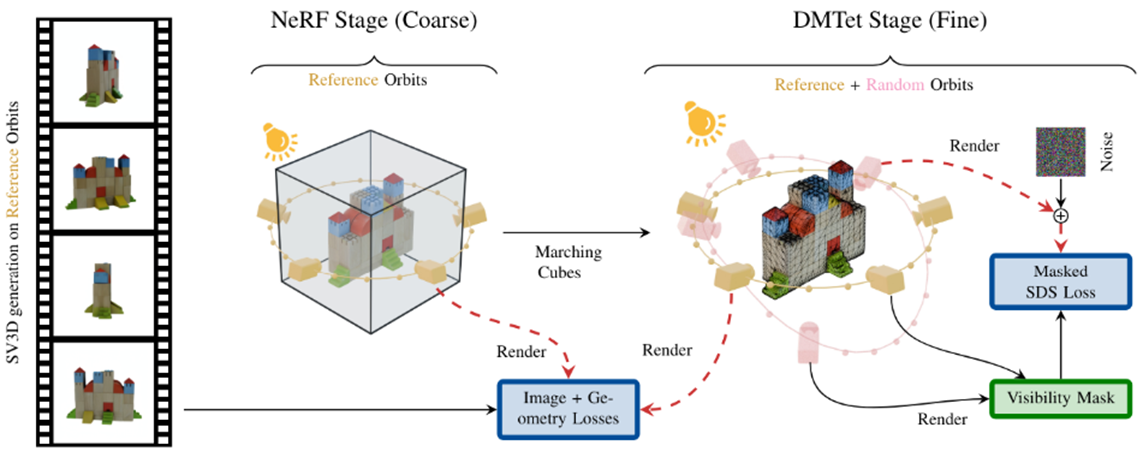
HumanSplat의 Novel-view synthesizer를 보면 SV3D를 사용한다고 되어 있는데, 실제로 SV3D 논문에 나와 있는 diffusion model의 형태와 비교를 해 보면 VAE와 CLIP이 사용되는 것 부터 U-Net 형태의 backbone이 사용되는 것 까지 매우 유사하다는 것을 알 수 있다. 차이점은 camera와 time embedding의 유무정도..?

실제로 위 4개의 image들을 각각 input으로 SV3D에 넣어주면 아래와 같은 결과물을 얻을 수 있다.
Conditions of Diffusion Model
SVD와 SV3D는 conditioning을 줄 때 CLIP text embedding을 image embedding으로 대체하였다. Text prompt와 비교했을 때 image prompt는 더 정확하고 직접적으로 정보를 제공하고 text 변환이나 image caption 과정에서 걸리는 시간을 절약시켜 준다. SV3D는 image와 relative camera orbit elevation, azimuth angle을 input으로 사용해서 여러장의 해당 novel-view image들을 만들어 내는데 3D space에서 연속적이고 camera moving에 의해 video로 여겨질 수도 있다.
본 논문에서는 SV3D를 human dataset에 대해 finetuning 시켜서 기존의 relative camera elevation과 azimuth angle과 함께 4개의 orthogonal view들을 만들어내었다고 한다.
Latent Reconstruction Transformer
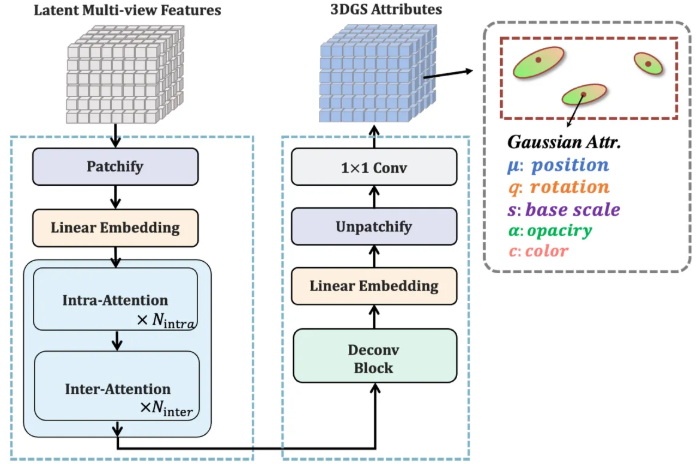
Latent reconstruction Transformer는 latent embedding interaction과 geometry-aware interaction 2개의 부분으로 나눠져 있다. 이 둘은 이음매 없이 novel view synthesizer와 human structure prior로 부터 latent feature들을 합친다. 이 둘은 cohesive framework를 형성해서 복잡한 human detail도 정확하게 복원을 한다.
본 논문에서는 pretrained VAE encoder epsilon을 이용해서 input image I를 latent representation F_0로 encoding하고 생성한 F_i과 합친다.
이전 논문들에 이어 latent representation들은 이것들에 대응하는 Plucker embedding들과 channel dimension을 따라서 concatenate 되어 dense pose-conditioned feature map을 만들어낸다.
이 latent들은 그 뒤 non-overlapping patch들로 나눠져서 linear layer에 의해 d 차원의 latent token들로 mapping 된다. Intra-attention module이 N_intra block의 multi-head self-attention과 feed-forward network [FFN]을 갖는 Transformer에 의해 추출된 latent token의 spatial correlation에 이어 나오게 된다.
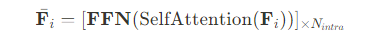
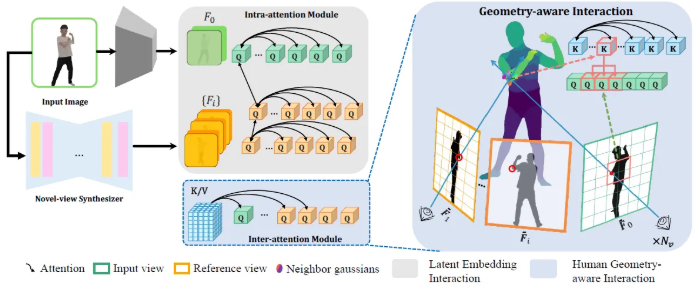
Geometry-aware Interaction
Human Geometric Tokenizer
주어진 human geometric model M에 대해, feature representation을 얻기 위해 M을 input view에 project하고 feature grid에서 bilinear interpolation을 통해 feature vector를 연산했다고 한다.

Human Geometry-aware Attention
Human prior [SMPL model]을 human reconstruction으로 합치는 것은 robustness와 flexibility 사이의 trade-off에 대한 dilemma에 직면해왔다고 한다. SMPL model은 broken body part나 artifact 같은 흔한 이슈들을 줄여주긴 하지만, 복잡한 옷의 스펙트럼을 표현하고 정확히 포착하는 것에 대해는 어려움을 겪는다. 이 점이 정확하게 다양한 의류를 표현하는 모델의 능력 부족을 강조하게 된다고 한다.
그래서 HumanSplat은 human prior에서의 부정확함을 3D token을 2D space에 project 시켜서 adjacent window 안에서 local search를 진행하여 redundancy를 최소화 하면서 효율적으로 prior를 이용하는 접근법을 이용하였다고 한다.
특히 HumanSplat에서 제안된 inter-attention module 내부의 projection-aware attention으로 window $\mathbf{W}(K_{win}\times K_{win})$을 활용하고 masked multi-head cross-attention을 활용하였다고 한다.
Latent feature $\lbrace\bar{\mathbf{F}}_i$을 query로 사용하고 human prior token $\bar{\mathbf{H}}$를 key와 value로 이용하여 다음 수식을 구성했다고 한다.

Semantics-guided Objectives
각각의 output token $\tilde{\mathbf{F}}_i$에 대해 pixel-aligned Gaussian $G$를 1X1 kernel을 갖는 convolutional layer의 patch로 decoding을 하면 이 attribute들이 3D Gaussian Splatting rasterization을 통해 novel-view image로 rendering되게 된다.
이상적인 training objective는 rendering된 output이 supervised image와 밀접하게 matching이 되어야 한다는 점이다. 그래야 reconstructed rendering과 ground truth 사이의 consistency를 유지할 수 있다.
그러나, human attention은 특히 얼굴 부분에 focusing이 되기 때문에 perception과정에서 복잡한 detail들이 중요한 역할을 하게 된다. 그러므로, reconstructed human model의 fidelity를 높이기 위해 objective function을 최적화해서 얼굴 부분에 focusing하는 것을 preferentially하게 하도록 했다고 한다.
Hierarchical Loss
기존의 접근 방식들은 human anatomy의 풍부한 semantic 정보들을 무시해왔기 때문에 중요한 detail이 없어지고 정확도도 낮아지게 된다. 이를 해결하기 위해 training process를 guide 하는 semantic cues, hierarchical supervision, tailored loss function을 사용하는 novel framework를 제안했다고 한다.
이를 통해 정확히 표현된 human body의 전체 구조를 보장할 뿐만 아니라 얼굴 같은 중요한 영역들이 예외적인 detail이나 fidelity와 reconstruct된다고 한다.
결과적으로 중요한 body part의 정확한 localization을 촉진할 수 있었다고 한다.

Reconstruction Loss

Experiments
Implementation Details
Training Details
- 500 THuman2.0, 1500 2K2K, 1500 Twindom
- 200 epochs of 256-res training with a learning rate of $1e^{-5}$ and a batch size of 32
- 2 days on 8 A100 [40G VRAM] GPUs
- 512-res finetuning costs 2 additional days
- AdamW optimizer [$\beta_1=0.9,\space\beta_2=0.95$]
- Weight decay of $0.05$ is used on all parameters except those of the LayerNorm layers
- Cosine learning rate decay scheduler with a 2000-step linear warm-up
- Peak learning rate is set to $4e^{-4}$
- For parts related to the heads, hands and arms, $\lambda_j=2$, rest human parts are set to $1$
- $\lambda_i,\lambda_p,\lambda_m=1$
- The model is trained for $80K$ iterations on $256$-res and then fine-tuned on $512$-res for another $20K$ iterations
- Flash-Attention-v2 in the xFormers library, gradient checkpointing and FP16 mixed-precision for efficient training and inference
- Fine-tuning SV3D : $18$ hours
Comparison
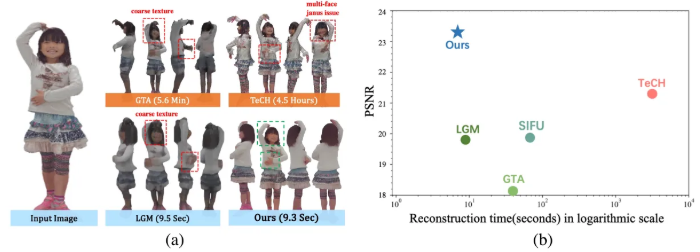
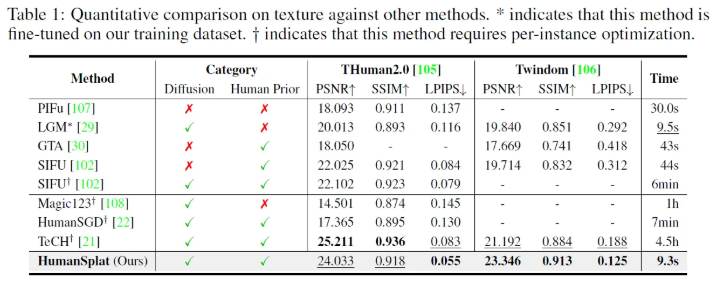




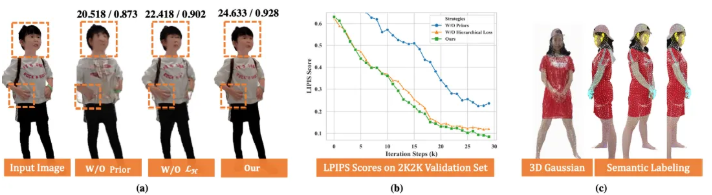
Ablation Study
Latent Reconstruction Transformer
HumanSplat leverages the Stable Diffusion latent space for feature extraction.
→ Utilizing the compact latent space for reconstructions leads to better rendering quality compared to using the pixel space
HumanSplat exhibits robustness in testing against challenging poses with imperfect estimation, with minor declines in metrics

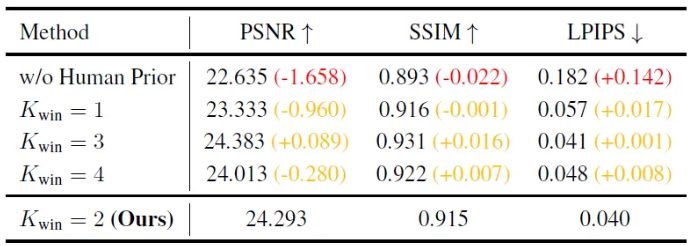
Semantics-guided Training Objectives
Conclusion
HumanSplat, a pioneering generalizable human reconstruction network that derives 3D Gaussian Spltting properties from a single image
This model integrates generative diffusion and latent reconstruction Transformer models with human structure priors, enhanced by a tailored semantic-aware hierarchical loss
→ High-fidelity reconstruction results in a feed-forward manner without any optimization or fine-tuning, especially in the important focal areas such as the face and hands