GitHub - yukangcao/JIFF
Contribute to yukangcao/JIFF development by creating an account on GitHub.
github.com
JIFF: Jointly-aligned Implicit Face Function for High Quality Single View Clothed Human Reconstruction
This paper addresses the problem of single view 3D human reconstruction. Recent implicit function based methods have shown impressive results, but they fail to recover fine face details in their reconstructions. This largely degrades user experience in app
arxiv.org
Abstract
최근의 연구들이 face detail을 포착하는데 어려움을 겪고 있음
그래서 이 논문에서는 reconstruction에서의 face quality를 높이기 위해 implicit function based method와 model based method의 장점을 결합한 Jointly-aligned Implicit Face Function [JIFF]를 제안하였다.
Shape prior로 3D morphable face model을 사용해서 space-aligned 3D feature를 구해서 detail한 face geometry 정보를 얻고자 하였다고 한다. 이를 통해 얻은 space-aligned 3D feature들은 pixel-aligned 2D feature들과 결합되어 둘이 함께 high quality face reconstruction을 위한 implicit face function을 예측하게 된다.
Such space-aligned 3D features are combined with pixel-aligned 2D features to jointly predict an implicit face function for high quality face reconstruction
Introduction
기존의 방식들은 capturing hardware가 많이 필요했고 좋은 model을 얻기 위해 귀찮은 calibration 과정이 필요했기 때문에 비효율적이였다. 그렇기 때문에 고퀄리티의 3D human model을 만들기 위해 쉬운 tool들이 필요했다.
여러 방법들이 있지만, 그 중에서도 PIFu [Pixel-aligned Implicit FUnction]는 MLP [Multi-Layer Perceptron]을 사용해서 image로 부터 뽑아낸 pixel-aligned feature에 기반해서 occupancy value를 예측하기 위해 implicit function을 modeling 하였다. 하지만, PIFu는 미세한 얼굴의 detail이 부족하다는 단점이 존재했다.
따라서 JIFF에서는 implicit function based approach와 model-based approach의 장점들을 결합하여 이를 해결하고자 하였다. 구체적으로, 3D morphable face model [3DMM]을 이용해서 shape prior를 얻고 space-aligned 3D feature를 구해서 detail한 face geometry와 texture information을 구하였다.
Geo-PIFu나 PaMIR 같이 3D prior를 사용하여 implicit function의 representation을 향상시키고 reconstruction을 제어하기 위해 geometric constraint를 제안했지만, 이들과 다르게 JIFF는 처음으로 shape와 texture 둘 다에서 고퀄리티의 face detail을 포착하는 것에 포커싱한 방식이다.
In summary, our method first fits the 3DMM to the face in an image and employs two separate encoders to compute 3D shape and texture features.
Contribution
- We propose JIFF, a novel implicit face function for high quality single view 3D face reconstruction, which integrates 3D face prior into the implicit function representation for high quality face shape reconstruction.
- We exploit per-vertex color information provided by the 3DMM and introduce a coarse-to-fine architecture for high quality face texture prediction
- We demonstrate how JIFF can naturally be extended to produce full body human reconstruction by simply appending a “PIFu” head [implemented as a MLP] to its convolutional image encoder
- We carry out extensive experiments on public benchmarks and demonstrate that JIFF outperforms current SOTA by a large margin.
Preliminary
PIFu [Pixel-aligned Implicit FUnction]
최근, implicit function이 3D reconstruction에서 주로 사용되고 있다. 3D point X에 대해 MLP에 의해 모델링 되는 deep implicit funciton은 surface를 function의 level set으로 정의한다.PIFu에서 제안된 pixel-aligned implicit function 수식은 다음과 같다.


Impressive한 결과물을 얻을 수 있지만, 얼굴에서의 fine detail이 부족하다.
3DMM as 3D face prior
PIFu를 향상시키기 위한 자연스러운 아이디어는 implicit function representation을 학습할 때 3D shape prior를 강화시키는 것이다.
GeoPIFu에서는 coarse 3D volume feature들을 이용하였고 ARCH(++), PaMIR에서는 voxelized SMPL mesh feature들을 이용했다. 이 방식들이 전반적인 reconstruction quality는 향상시켰지만, face에 초점을 두지 않기 때문에 여전히 face detail이 부족하다고 한다.
이상적인 3D face prior는 geometry와 texture information 둘 다를 제공할 수 있어야 한다고 한다. 3DMM이나 DECA 같은 parametric face/head model은 3D mesh와 texture information을 제공해서 depth ambiguity를 줄이고 texture prediction의 성능을 높일 수 있기 때문에 좋은후보가 될 수 있다.
이 둘은 적은 수의 parameter 만으로도 묘사가 가능하기 때문에 기존 방식들보다 더 효율적이라고 한다. 이 논문에서는 3DMM를 이것의 simplicity와 efficacy로 인해 3D face prior로 사용했다고 한다.
3DMM model은 PCA (Principle Component Analysis) 기반 벡터들의 linear combination으로 얼굴을 모델링할 수 있다. 3DMM의 shape S와 texture T는 다음과 같이 표현할 수 있다.

Jointly-aligned implicit face function
Incorporating 3D face prior in learning implicit function for high quality single view clothed human reconstruction
하지만, 3DMM mesh를 PIFu에서 뽑아낸 mesh와 병합하는 것은 이 둘이 같은 geometry와 topology를 공유하지 않기 때문에 쉬운 일이 아니라고 한다.
따라서 이 두 mesh를 3차원 공간에서 naive하게 merge하는 것 대신에 feature space에서 information을 fuse해서 2개의 3DMM에서 뽑은 space-aligned 3D feature들과 image에서 뽑은 pixel-aligned 2D feature들을 이용해서 함께 implicit face function을 추정하는 방식으로 변화했다고 한다.

이를 기반으로 JIFF를 수식화하면 다음과 같다고 한다.

3DMM prediction and alignment

Point-based 3D face feature encoding
3DMM mesh에서 expressive한 feature들을 뽑아내기 위해 적절한 feature encoder를 사용해야 한다. Point cloud에서 occupancy를 예측하는 논문에 영향을 받아서 PointNet++을 이용해 각각의 vertex에서 hierarchical 3D point feature들을 3DMM mesh에서 뽑아냈다고 한다. 이렇게 뽑아낸 feature들은 average pooling에 의해 3D feature volume으로 project되고 이 feature volume은 3D U-Net에 의해 또 한번 처리가 되어 local과 global information을 모으게 된다고 한다.
Occupancy prediction

Face texture prediction
Face reconstruction을 하기 위한 geometric detail들을 recovering 하는 것 대신에 JIFF는 face texture prediction도 가능하다. Shape prediction과 유사하게 deep implicit function은 다음과 같은 수식으로 표현할 수 있다고 한다.

Texture feature encoder에 의해 뽑아진 space-aligned 3D texture feature는 textured 3DMM으로부터의 space-aware texture information을 embedding해서 나중에 face texture prediction에 사용한다고 한다. 여기서 주목할 점은 PaMIR 같은 기존의 연구들이 parameteric model을 texture information이 없이서 space-aware texture information으로 사용하려고 고려하지 않았다는 점이다.
Coarse-to-fine texture prediction
Textured 3DMM mesh로 부터 뽑아낸 space-aligned 3D feature들 덕분에 JIFF는 PIFu보다 더 좋은 face texture를 생산할 수 있었다고 한다. 여기서 더 나아가서 더 좋은 결과물을 만들기 위해 H3D-Net에 영감을 받아서 coarse-to-fine architecture를 적용했다고 한다.
Coarse branch는 Tex-PIFu와 동일한데, shape prediction network로 부터의 pixel-aligned feature와 texture prediction network에서의 pixel-aligned feature 간의 concatenation을 MLP의 input으로 사용해서 coarse texture를 예측하고 fine branch는 1024X1024X3 크기의 image를 받아서 image encoder를 거쳐서 512X512X256 크기의 feature map을 만들어낸다고 한다.
이 feature map에 의해 연산된 pixel-aligned feature는 penultimate layer에 의해 output과 concatenate 된다. 이를 통해 multi-scale pixel-aligned feature가 만들어지고 shape prediction network와 유사하게 multi-scale pixel-aligned feature와 space-aligned texture feature는 각각 2개의 MLP에 의해 변환되어 최종적인 fine texture prediction을 하는 MLP에 들어가게 된다.
Full body reconstruction
JIFF는 얼굴 뿐만 아니라 전신으로도 확장이 가능한데, 단순히 PIFu의 MLP만 shape prediction network의 image encoder로 갖다 붙이면 된다고 한다.
Our coarse-to-fine design can also notably improve the texture prediction for non-face regions
Experiments

Dataset
- RenderPeople
- AXYZ
- THUman2..0
- BUFF
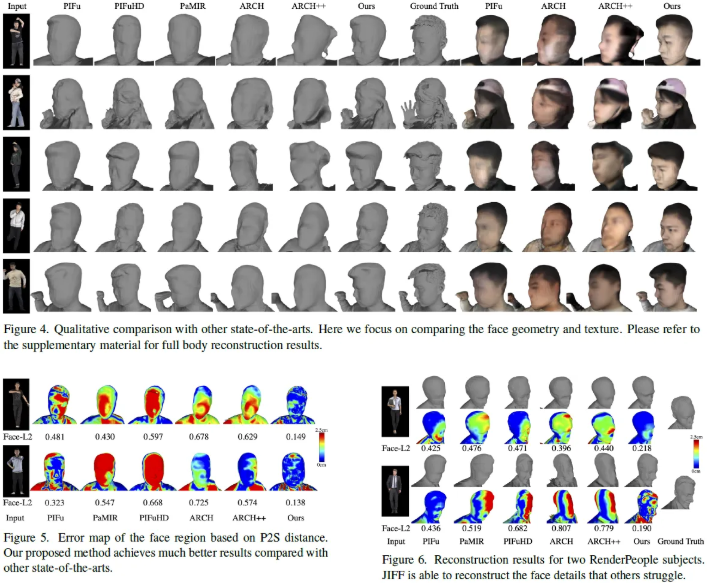
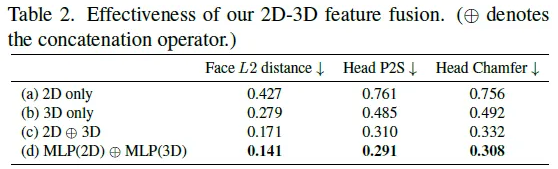

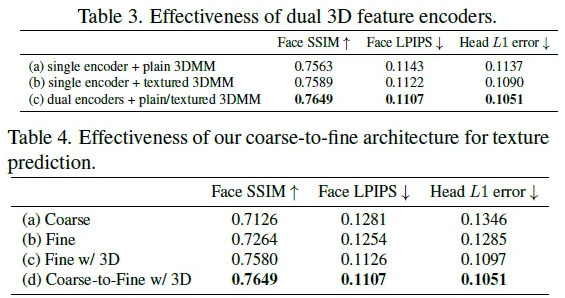
Conclusion
We have presented JIFF, a novel Jointly-aligned Implicit Face Function for high quality single view 3D human reconstruction, by incorporating the 3D face prior, in the form of 3DMM, into the implicit representation
We further introduced a coarse-to-fine architecture for high quality face texture reconstruction. By simply appending two MLPs, one for shape and the other for texture, to JIFF, we successfully extended it to produce full body human reconstruction