DoubleField Project Page
We introduce DoubleField, a novel framework combining the merits of both surface field and radiance field for high-fidelity human reconstruction and rendering. Within DoubleField, the surface field and radiance field are associated together by a shared fea
www.liuyebin.com
DoubleField: Bridging the Neural Surface and Radiance Fields for High-fidelity Human Reconstruction and Rendering
We introduce DoubleField, a novel framework combining the merits of both surface field and radiance field for high-fidelity human reconstruction and rendering. Within DoubleField, the surface field and radiance field are associated together by a shared fea
arxiv.org
Abstract
DoubleField를 한 문장으로 요약하면 아래와 같다.
A novel framework combining the merits of both surface field and radiance field for high-fidelity human reconstruction and rendering.
- Surface field and radiance field are associated together by a shared feature embedding and a surface-guided sampling technology.
- view-to-view transformer is introduced to fuse multi-view features and learn view-dependent features directly from high-resolution inputs
Our method significantly improves the reconstruction quality of both geometry and appearance, while supporting direct inference, scene-specific high-resolution finetuning, and fast rendering.
Introduction

Surface field와 radiance field는 최근에 geometry modeling과 implicit하고 continuous한 방식으로 3D human의 texture rendering을 하는 기법으로 등장했다. 하지만, 이 방식들에 단점들이 존재한다고 한다.
- Surface field는 geometry learning과 appearance learning을 분리시켜서 더 detail한 geometry를 finetuning하지 못하게 하고 rendering 결과도 좋지 못하게 나오게 된다.
- Radiance field는 효과적인 constraint 없이 implicit한 방식으로 geometry와 appearance를 학습하는 것을 복잡하게 만들어서 inconsistent한 geometry reconstruction과 상대적으로 training 효율이 낮아지게 된다는 단점이 있다.
- 또한 제한적인 feature의 representation과 calibration, geometry inference error는 아무리 높은 해상도의 input을 사용한다한들 현재의 implicit field based method의 multi-view inconsistency 때문에 reconstruction 성능이 안좋아지게 된다.
이러한 단점을 극복하기 위해 DoubleField framework를 제한해서 surface field와 radiance field를 효과적으로 연결시켜서 geometry와 radiance reconstruction을 위한 공유 학습 공간을 만들었고, view-to-view transformer를 제안해서 multi-view input들 사이의 self-attention, input view와 query viewpoint 사이의 cross-attention을 통해 multi-view feature fusion을 하였다고 한다.
특히나 surface field와 radiance field의 association을 네트워크 구조와 surface-guided sampling strategy상의 이 두 field에 의해 공유 된 feature embedding을 사용해서 구축했다고 한다.
이러한 공유 학습 공간이 surface field와 radiance field에게 서로 이익이 될 수 있다.
- Surface field가 radiance field에게 geometry constraint를 부여해서 neural rendering을 위한 더 consistent한 density distribution을 장려한다.
- Radiance field가 differentiable rendering을 통해 surface field에서 더 많은 geometry detail들을 뽑아낼 수 있도록 해준다.
결과적으로 Surface-guided sampling 전략이 appearance modeling으로부터 geometry 요소를 분리시켜서 DoubleFiled가 reconstruction 성능과 rendering 성능을 높이면서 더 빠른 학습 속도를 얻을 수 있게 되었다고 한다.
Multi-view input에 대해 DoubleField를 deploy하면서 view-to-view transformer를 제안해서 multi-view input간에는 self-attention을 적용하고 input view와 query viewpoint 사이에는 cross-attention을 적용했다.
이 방법의 경우 view-to-view transformer에 encoder-decoder 구조를 적용해서 이를 실현했다고 한다. Encoder의 목표는 multi-view feature들을 fusing하는 것이고 Decoder의 목표는 query view와 input view들 사이의 cross-attention에 의해 학습된 view-dependent한 feature들을 만들어내는 것이다.
Transformer의 attention mechanism에서의 attention이 input과 query view 사이의 관계를 다루고 real-world multi-view setup에서의 geometry inference와 calibration error에 더욱 robust한 덕분에 DoubleField에서는 multi-view inconsistency가 줄어들었다고 한다.
또한 view-to-view transformer는 raw RGB value를 이용해서 view-to-view transformer가 직접적으로 고해상도 이미지들로 부터 view-dependent feature들을 학습하고 이를 통해 high-fidelity rendering 성능에도 기여할 수 있도록 함으로써 원본 고해상도 이미지들을 활용할 수 있게 해주었다고 한다.
Contribution
- A DoubleField framework [a shared double embedding and a surface-guided sampling technology] to combine the merits of both surface and radiance fields for sparse multiview human reconstruction and rendering
- View-to-view transformer to fully utilize ultra-high-resolution image inputs in an efficient manner
- Achieve SOTA performance on both geometry reconstruction and texture rendering of human performances using sparse-view inputs
Related Work
Neural implicit field
최근 geometry reconstruction과 graphic rendering 분야에서 neural implicit field가 주목을 받고 있다. 기존의 mesh, volume, point cloud 같은 explicit representation 기법들과는 달리 neural implicit field는 3D model을 직접적으로 3D location이나 occupancy에 해당하는 viewpoint들을 mapping시키는 neural network를 이용해서 encoding한다.
Discrete한 voxel이나 vertice 대신 spatial coordinate에 conditioning해서 neural implicit field는 continuous하고 resolution에 independent하며 더욱 flexible하다는 장점이 있어서 고퀄리티의 surface recovery와 photorealistic한 rendering이 가능하다.
- Geometry reconstriction
: surface field에 기반한 방식들이 하나 이상의 이미지들로부터 detail한 model들을 만들어낼 수 있고 local implicit field를 이용해서 high-fidelity geometry를 만들어낼 수 있다. - Graphics rendering
: implicit field에 기반한 방식들이 differentiable rendering에 적합하다.
이들 중에 최근에 등장한 NeRF의 경우 novel-view synthesis 뿐만 아니라 photorealistic한 rendering에서도 두각을 나타내고 있다. 하지만, 이 방식을 일반적인 inference를 위한 large scale human scan dataset training으로 확장시키는 것은 적합하지 않다. 또한 2개의 field 사이의 numerical한 관계를 만드는 것은 solid하고 non-transparent한 surface를 표현하는 것에만 한정적이다.
DoubleField frameworks는 이 2개의 field들을 implicit한 방식으로 feature level에서 결합해서 자연스럽게 pixel-aligned feature들을 합칠 수 있고 training 동안 large scale dataset으로부터 geometry prior를 학습할 수 있게 되었다.
Human reconstruction
최근 다양한 연구들이 monocular 또는 multi-view camera setting으로 부터 shape, pose, cloth surface 등 다양한 레벨의 template-based human body를 캡쳐하려는 연구들이 진행되고 있다.
하지만, 이러한 방식들은 representation ability에 의해 제한되어 geometry와 appearance에서 낮은 해상도의 결과를 보이고 template-based algorithm으로 topology의 변화를 다루는 것이 어렵다. 또 다른 연구들의 경우 dense한 viewpoint나 controlled lighting 같은 매우 비싼 요구사항들 때문에 고퀄리티의 human reconstruction을 수행하기가 어렵다.
최근, implicit field가 sparse view로부터 detail한 geometry reconstruction을 가능하게 했다.
본 연구로 인해 high-quality geometry reconstruction을 위한 새로운 방식을 사용했고 body template가 필요 없는 high-fidelity human rendering이 가능해졌다.
Transformer
Transformer의 핵심 아이디어인 attention mechanism이 본 연구에서 중요한 역할을 한다. Attention mechanism의 correlation을 얻는 능력이 visual answer-questioning, texture transferring, multi-view stereo, hand pose estimation 같은 다양한 연구들에 적용이 되었다.
DoubleField에서는 view-to-view transformer를 적용해서 multi-view input들 사이의 correspondence를 포착하고 있다.
Preliminary

Neural Surface Field
Occupancy field로 표현된 neural surface field는 3D surface를 modeling하는데 있어서 reolution-independent한 방식이다. Surface field는 3D point x를 surface field value s에 mapping 시키는 implicit function f_s에 의해 정의 된다.

Generalization과 detailed geometry를 향상시키기 위해 PIFu에서는 이것들을 다음의 수식을 이용해서 pixel-aligned image feature로 conditioning 시켰다.
GitHub - shunsukesaito/PIFu: This repository contains the code for the paper "PIFu: Pixel-Aligned Implicit Function for High-Res
This repository contains the code for the paper "PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization" - shunsukesaito/PIFu
github.com

PIFu는 위 수식에서 더 나아가 아래의 수식을 만족시키는 point x_c에서의 RGB 값 c를 예측함으로써 surface에서의 texture까지도 복원을 하였다.

그러나 PIFu는 geometry와 appearance를 함께 modeling하는 straightforward한 해결방식을 제공하기 때문에 geometry와 texture를 고립시켜서 texture learning space가 불연속이 되고 texture supervision 하에서의 geometry optimization process를 방해한다.
Neural Radiance Field
NeRF: Neural Radiance Fields
A method for synthesizing novel views of complex scenes by optimizing an underlying continuous volumetric scene function using a sparse set of input views.
www.matthewtancik.com
NeRF는 scene을 geometry와 appearance를 entangled form으로 표현하는 연속적인 volumetric radiance field로 표현한다.
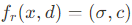
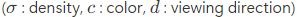
위 수식에서 volumetric rendering이 projection ray를 따라서 novel view image를 합성할 수 있다.

이 뒤에 나온 PixelNeRF는 sparse multi-view에서만 novel view synthesis를 달성하기 위해 NeRF를 확장시켜서 PIFu에서와 유사한 방식으로 pixel-aligned image feature들을 leverage하는 방식을 사용했다.
pixelNeRF: Neural Radiance Fields from One or Few Images
Alex Yu Vickie Ye Matthew Tancik Angjoo Kanazawa UC Berkeley
alexyu.net
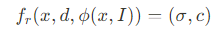
Density와 color의 entangled modeling이 NeRF를 training 시킴에 있어 높은 flexibility를 가져다 주지만, PixelNeRF에서 학습시킨 surface는 주어진 sparse-view input에만 inconsistent하기 때문에 novel view rendering에서 ghost-like나 blurry result 같은 artifact들이 생길 수 있다.
Method
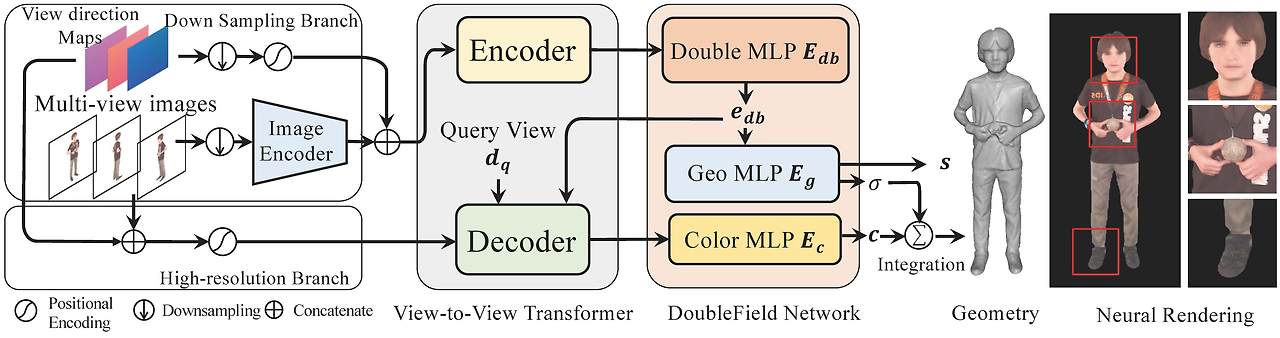
DoubleField Network
To overcome the limitations of existing neural field representations, we introduce the DoubleField network. The core of DoubleField consists of a shared embedding and a surface-guided sampling strategy, which connects the surface field and the radiance field so that they can be benefited from each other
기본적으로 DoubleField는 surface field와 radiance field에 맞추기 위해 MLP에 의해 표현된 joint implicit function에 의해 구성될 수 있다.
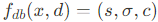
게다가 DoubleField는 pixel-aligned image feature Φ[x,I]에 의해 conditioning 될 수도 있다.
주어진 query point x에 대해 viewing direction d와 image feature Φ[x,I]에 대해 DoubleField network f_{db}는 shared double embedding을 학습하고 surface field s, density field σ, texture field c를 동시에 예측한다.
DoubleField network는 shard MLP로 구성되어 있고 이는 double embeding e_{db}와 surface field와 radiance field를 위한 2개의 개별 MLP로 구성되어 있다.
전체를 종합하면 DoubleField network는 다음과 같이 구성된다고 한다.

⇒ Implicitly builds a strong association between the two fields and enables their cooperation at the feature level
Surface-guided Sampling Strategy
2개의 field 사이의 학습된 relation 더 잘 활용하고 rendering process를 가속화하기 위해 surface field를 완전히 사용하는 surface-guided sampling strategy를 제안했다.
Surface-guided sampling strategy는 처음에는 surface field에서의 intersection point를 결정하고 그 뒤 intersection surface의 주변에서 fine-grained sampling을 진행한다. 특히 rendering view에서 주어진 camera parameter와 ray r=o+td에서 N_s개의 sampling point에 대해 depth bound [t_n,t_f]의 범위에서 ray를 따라 uniform sampling을 적용하면 각각의 point가 다음과 같이 바뀌게 된다.
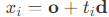
그 뒤 surface에서 처음으로 겹치는 position을 결정하기 위해 각각의 point의 surface field value를 query한다.
이 과정을 통해 결정된 intersection들은 N_r개의 sampling point에서 interval δ를 갖는 real surface 주위의 radiance field에 의한 더 fine-grained level의 sampling을 guid하는데 사용된다.
Our surface-guided sampling strategy can emphasize the relation between two fields around the mesh surface which facilitates the training and the finetuning process
NeRF와 비교했을 때 DoubleField가 integration에 필요한 sampling point들을 더 적게 sampling하면서 더 빠른 속도를 보였다고 한다.
View-to-view Transformer
Multi-view input을 DoubleField에 적용을 할 때, multi-view image로부터 feature들을 fuse할 필요가 있다.
Straightforward한 해결책은 PIFu나 PixelNeRF와 비슷한 fusing strategy를 사용하는 것인데, pixel-aligned feature들이 multi-view image들로부터 뽑아지고 그 뒤 DoubleField inference를 위해 fuse된다는 것이다. 특히 주어진 n개의 viewpoint에서의 image input 상응하는 camera parameter에서 image feature들은 image encoder에 의해 추출된다. Query point x에 대해 i번째 image I에서의 pixel-aligned feature는 x의 projection에 기반하여 얻어진다. 이런 multi-view image들로 부터 뽑아내진 pixel-aligned feature들은 Φ[x]로 다같이 fuse된다.

Multi-view feature fusion 방식이 robust하고 plausible한 결과물을 만들어내기는 하지만, 이 방식의 경우 단지 상대적으로 낮은 해상도의 image feature map만 leverage한다. 게다가 real-world data에서의 geometry inference error나 calibration에서의 noise는 최종 rendering 결과물의 퀄리티를 떨어뜨린다.
이러한 점을 극복하기 위해 view-to-view transformer를 제안해서 직접적으로 raw RGB value를 이용해서 self-attention과 cross-attention으로 처리를 했다고 한다.
특히 view-to-view transformer는 encoder-decoder 구조를 채택해서 모든 input view로부터 point x의 observation과 query view의 direction d_q를 leverage해서 view-dependent한 rendering을 위해 color feature e_c를 예측하고자 했다. 이를 통해 view-to-view transformer는 효율적으로 encoder에서 multi-view feature들을 fuse할 뿐만 아니라 query view와 decoder에서의 모든 input view 들간의 cross-attention을 가능하게 했다고 한다.
Encoder
Encoder의 목표는 multi-view input들로부터 geometry feature들을 fuse하는 것이다. Encoder에서는 self-attention과 feed-forward operation ψ를 이용해서 fused feature Φ를 얻는다.

Decoder
Decoder의 목표는 모든 input view로부터의 observation과 query view direction d_q에 따라 view dependent한 color embedding e_c를 생산하는 것이다.
고해상도 정보를 leverage하기 위해 decoder는 raw RGB, double embedding을 포함한 low, high level의 observation 둘 모두를 받는다.

Training and Finetuning
DoubleField의 network가 input으로 쓰이는 고해상도의 image들을 leverage할 수 있지만, 고해상도이기 때문에 training time cost가 매우 높은 것은 받아들여지지 않는다. 따라서 더 현실적인 해결책을 위해 2가지 단계로 구현을 했다고 한다.
- Low-resolution large-scale-dataset pre-training
- Efficient person-specific high-resolution finetuning
Large-Scale Dataset Pre-training
DoubleField에서의 pre-training 단계는 PIFu와 PixelNeRF와 비슷하다. Twindom dataset에서 human model들을 모든 뒤에 $512\times 512$ size로 image들을 rendering한다.
PIFu에서의 spatial sampling strategy를 사용해서 geometry를 학습시키고 appearance 학습을 위해 아까 언급된 surface-guided sampling strategy를 사용한다고 한다.
Geometry training에서의 loss는 PIFu에서의 spatial sampling loss function과 implicit geometric regularization loss를 사용한다고 한다.

Regularization loss는 input으로 normal map이 없어도 geometry reconstruction의 quality를 높일 수 있다고 한다.
Appearance loss로는 rendered color와 ground truth color 사이의 L1 loss를 사용해서 구한다고 한다.

Finetuning Phase
Finetuning 단계에서 network는 특정 사람의 sparse multi-view로 부터 ultra-high-resolution image를 input으로 받아서 differentiable rendering loss를 이용해서 self-supervised 방식으로 network의 parameter들을 finetuning 시킨다.
특히나, 먼저 transformer와 color MLP를 고정시키고 geometry를 2000 iteration 동안 finetuning 시킨다. 그 뒤 double MLP와 geometry를 고정시켜서 2000 iteration 동안 color MLP를 finetuning 시킨다.
각각의 iteration 동안 ground truth로 임의의 view를 선택하고 다른 view들을 input으로 고려를 하게 된다.
Experiment
Experiments on Synthetic Data
Twindom dataset과 THuman 2.0 dataset을 이용해서 multi-view image의 synthetic rendering으로 method를 평가했다고 한다.
Full Body 3D Scanners for 3D Printed Figurines, 3D Portraits, 3D Selfies, and Avatar Products by Twindom
The Twindom Mobile Full Body 3D Scanner is a portable, high quality 3D body scanner that generates avatars for 3D printed figurines, 3D portraits, 3D selfies and avatar products. Learn how Twindom's 3D scanning technology and avatar business solution can h
web.twindom.com
GitHub - ytrock/THuman2.0-Dataset
Contribute to ytrock/THuman2.0-Dataset development by creating an account on GitHub.
github.com
연구원들은 DoubleField를 surface field와 radiance field를 기반으로 만들어진 PIFu, PixelNeRF, NeuralBody, PIFuHD와 같은 SOTA 방식들과 비교를 했다고 한다.
Result
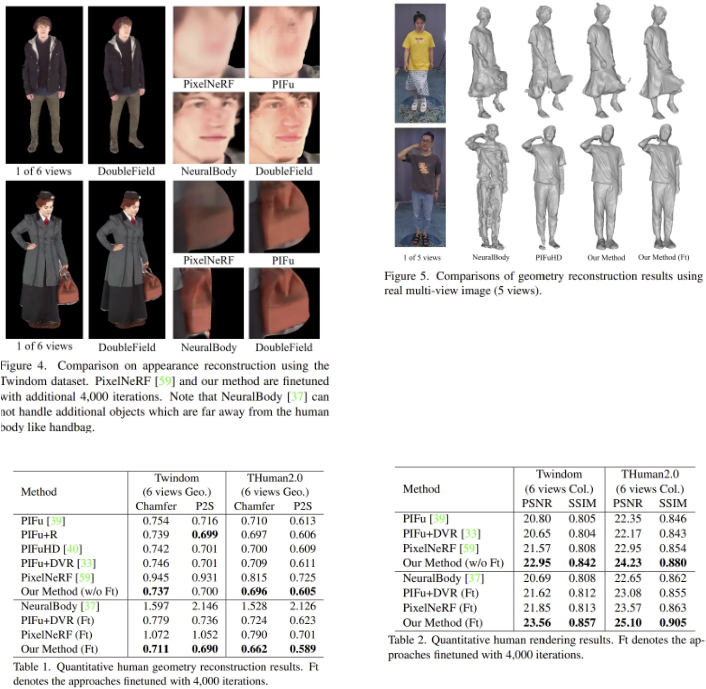


Rendering을 하면 위와 같이 결과가 출력된다고 한다.
Discussion
Conclusion
We propose DoubleField to combine the merits of both geometry and appearance fields for human surface reconstruction and rendering under sparse view inputs
DoubleField network와 view-to-view transformer를 제안해서 geometry reconstruction과 texture rendering 성능을 높였다.
Limitations
제안된 pipeline의 경우 DoubleField inference에 사용되는 pixel-aligned image feature extraction의 요구사항 때문에 여전히 정확한 background image subtraction에 의존한다.
또한 DoubleField는 여러 character scenario의 reconstruction과 rendering을 지원하지 않는다.