[논문] Stacked Hourglass Networks for Human Pose Estimation
·
Paper Review
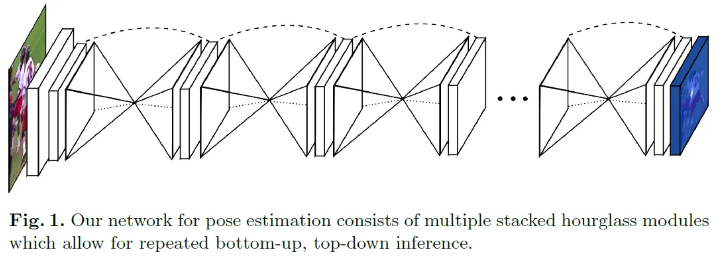
Stacked Hourglass Networks for Human Pose EstimationThis work introduces a novel convolutional network architecture for the task of human pose estimation. Features are processed across all scales and consolidated to best capture the various spatial relationships associated with the body. We show how repeatearxiv.org GitHub - princeton-vl/pytorch_stacked_hourglass: Pytorch implementation of the E..




