https://www.matthewtancik.com/nerf
NeRF: Neural Radiance Fields
A method for synthesizing novel views of complex scenes by optimizing an underlying continuous volumetric scene function using a sparse set of input views.
www.matthewtancik.com
Abstract

We present a method that achieves SOTA results for synthesizing novel views of complex scenes by optimizing an underlying continuous volumetric scene function using a sparse set of input views
- Input : spatial location x,y,z and viewing direction θ , ϕ
- output : volume density and view-dependent emitted radiance at that spatial location
이 논문에서는 camera ray에 따라 5D 좌표들을 query하고 classic volume rendering 기법을 사용해 output color와 density를 image에 투영함으로써 view를 합성함
Introduction

Rendering된 captured image의 set의 error를 최소화하기 위해 직접적으로 연속적인 5D Scene representation의 parameter들을 최적화함으로써 오랫동안 문제로 여겨진 새로운 방식의 view synthesis를 해결하고자함
NeRF의 경우deep fully-connected neural network를 어떠한 convolutional layer 없이 최적화함 [여기서 convolutional layer는 MLP를 의미]
→ 하나의 5차원 좌표 [x,y,z,θ,ϕ]를 하나의 volume density와 view-dependent RGB color에 regressing 함으로써 최적화
특정 viewpoint에서 NeRF를 rendering 하기 위해서는 다음과 같은 것이 필요함
- 광선을 따라 이동하여 샘플링된 3D 포인트 집합을 생성
- 해당 점들과 각 점에 대한 2D 시점 방향을 신경망에 대한 입력을 사용하여 색상과 밀도의 집합을 생성
- 고전적인 volume rendering 기술을 사용하여 해당 색상과 밀도를 2D 이미지에 집계
이 과정이 완전히 미분가능하기 때문에 모델을 최적화하는 과정에 gradient descent 사용 가능
다양한 view에서의 이 error를 최소화하게되면 network가 high volume density와 해당 위치의 정확한 color 값을 매핑시켜서 일관성 있는 model of the scene을 예측하도록 할 수 있음
Complex scene에서 NeRF representation을 최적화하는 기본적인 구현은 충분히 높은 해상도로 수렴하지 않고 camera ray당 필요한 sample들의 개수도 충분하지 않다는 문제를 발견했다.
그래서 연구원들은 input 5D coordinate를 positional encoding으로 전환시켜서 MLP가 더 높은 frequency function을 표현하도록 하고 hierarchical sampling 과정을 제안해서 적절한 고해상도 scene representation을 sampling 하도록 query의 개수를 줄였다고 한다.
Related Work
기존의 연구들은 signed distance 같이 object와 scene들을 MLP weight에 encoding 해서 직접적으로 3D 위치 정보를 shape의 inplicit representation에 mapping 시켰다.
하지만, 이 방식들은 지금까지 삼각형 메시나 복셀 그리드와 같은 이산 표현을 사용하여 장면을 표현하는 기술과 동일한 충실도로 복잡한 기하학적 구조를 가진 현실적인 장면을 재현할 수 없었다고 한다.
Neural 3D shape representations
최근 연구는 signed distance function이나 occupancy field에 조정된 xyz를 매핑하는 deep network를 최적화하여 연속적인 3D 형상을 레벨 세트로 암시적으로 표현하는 방법을 조사했다. 하지만, 이 방식들의 경우 특히 synthetic 3D shape dataset에서 ground truth 3D geometry 접근의 요구사항이 제약받는다.
그 이후의 연구들은 neural implicit shape representation들이 단지 2D image들만을 사용해서 최적화하는 것을 가능하게 해주는 미분가능한 렌더링 함수를 통해 이러한 점을 완화시켰다.
Each ray intersection location is provided as the input to a neural 3D texture field that predicts a diffuse color for that point
View Synthesis and image-based rendering
주어진 dense sampling view에서 photorealistic한 novel view들은 간단한 light field sample interpolation 기법으로 재구성될 수 있다.
Sparse view에서의 novel view synthesis의 경우 meth-based scene representation을 diffuse나 view-dependent appearance를 사용한 방식을 사용한다. Differentiable rasterizers나 pathtracer들은 gradient descent를 이용해서 input image들의 set을 재생산하기 위해 직접적으로 mesh representation을 최적화한다.
하지만, image reprojection에 기반하고 있는 gradient-based mesh optimization의 경우 local minima나 loss landscape의 열악한 조건들로 인해 어렵고, 이 전략은 최적화 전에 고정된 topology를 갖고 있는 template mesh를 필요로 한다.
또 다른 방식은 input RGB image들로부터 고퀄리티의 photorealistic view synthesis를 다루는 volumetric representation을 사용한 방식이다.
Volumetric approch들은 realistic하게 복잡한 shape과 material을 표현할 수 있고, gradient-based optimization에 최적화 되어 있으며, mesh-based 방식보다 artifact로 흩어지는 것이 적은 경향을 보인다.
이러한 volumetric 기법이 novel-view synthesis에서 인상적인 결과를 보이지만 고해상도 image로 scale하는 능력은 근본적으로 discrete sampling 때문에 너무 오래걸리는 시간, 공간복잡도로 인해 제한된다. 또한 고해상도의 image들을 rendering 하기 위해서는 3차원 공간을 더 세밀하게 sampling하는 것이 요구된다.
따라서 이러한 문제를 해결하기 위해 연속적인 volume을 deep fully-connected neural network의 parameter들 안에서 encoding 하는 방법으로 해결하려고 했다고 한다. [이전의 volumetric 접근법 보다 더 높은 퀄리티의 rendering을 생성할 뿐만 아니라 sampled volumetric representation의 storage cost의 일부분만 요구된다.]
Neural Radiance Field Scene Representation

We represent a continuous scene as a 5D vector-valued function whose input is a 3D location x=[x,y,z] and 2D viewing direction [θ,ϕ] and whose output is an emitted color c=[r,g,b] and volume density σ .
이 방식에서 direction을 표현하기 위해 3D Cartesian unit vector d를 사용하고, 이 연속적인 5D scene representation을 MLP network F_ Θ :[x,d] → [c, σ]로 근사하고 weight Θ 를 각각의 input 5D 좌표가 상응하는 volume density와 directional emitted color에 mapping 되도록 최적화함
이 representation이 multiview consistent 하도록 network가 volume density σ 를 location x에만 예측을 하도록 제한을 걸고, RGB color c가 location과 viewing direction 둘 다에 예측이 되도록 하였다고 한다.
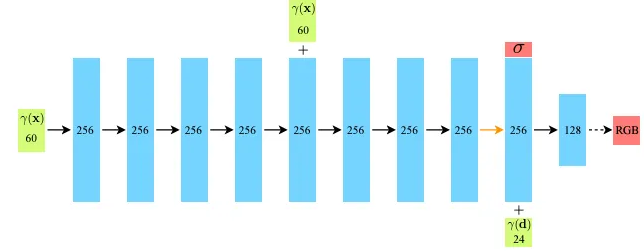
이를 위해 MLP F_ Θ 는 처음에 input 3D 좌표 x를 8개의 fully-connected layer [ReLU activation과 layer마다 256개의 channel들을 사용]로 처리를 하고 σ 와 256차원의 feature vector를 output으로 내보냄
이 feature vector는 camera ray viewing direction과 결합해서 1개의 추가적인 fully-connected layer [ReLU activation과 128개의 channel들 사용]를 통과해서 view-dependent한 RGB color를 output으로 내보냄
Volume Rendering with Radiance Fields
Our 5D neural radiance field represents a scene as the volume density and directional emitted radiance at any point in space

함수 T[t]는 t_n에서 t까지 광선을 따라 누적된 투과율, 즉 광선이 다른 입자에 부딪히지 않고 t_n에서 t로 이동할 확률을 나타낸다. 연속적인 NeRF에서 뷰를 렌더링하려면 원하는 가상 카메라의 각 픽셀을 통해 추적되는 카메라 광선에 대해 이 적분 C[r]을 추정해야 한다.

Quadrature [적분]를 이용해 continuous integral을 estimate함
이산적인 voxel grid들을 rendering 하는데 사용되는 Deterministic quadrature의 경우 MLP가 고정된 discrete set of location들에만 query될 수 있기 때문에 representation의 resolution에 제약을 걸 수도 있다.
따라서 이 방법 대신에 stratified sampling approch를 사용해서 [t_n,t_f]를 N등분해서 bin으로 분할한 다음 각 bin 내에서 하나의 샘플을 무작위로 추출하는 계층화된 샘플링 접근 방식을 사용

Integral을 구하기 위해 discrete set of sample을 사용하지만, stratified sampling은 MLP가 최적화 과정 전반에 걸쳐 continuous position에서 계산을 하기 때문에 continuous한 scene representation을 표현할 수 있게 해준다.


위 그림에서 볼 수 있듯이 view dependency 없이 학습된 모델 [입력으로 x만]은 반사를 표현하는 데 어려움이 있다.
Optimizing a Neural Radiance Field
Neural radiance field와 이 representation으로 부터 novel view를 rendering 하는 것은 SOTA 성능을 달성하기에 충분하지 않다고 봐서 연구원들은 고해상도 complex scene을 표현할 수 있도록 2가지 개선 사항을 제안했다.
- high-frequency function을 표현하는 과정에서 MLP를 assist하는 input 좌표의 positional encoding
- high-frequency representation을 효율적으로 sampling 할 수 있게 해주는 hierarchical sampling
Positional encoding
Network F_ Θ가 직접적으로 xyzθϕ 에 작용하는 것이 color와 geometry에서 high-frequency variation을 표현할 때 성능이 좋지 못하다는 것을 발견했다.
이는 deep network들이 low frequency function들을 학습하는데 편향되어 있기 때문인데, deep network들은 또한 input들을 network로 전달해주기 전에 high frequency function들을 사용해서 고차원 공간으로 mapping 시키는 것이 high frequency variation을 포함하는 data와 더 잘 맞는다는 것을 보였다.
따라서 F_ Θ를 reformulate해서 2개의 함수의 결합 형태로 쪼갰다
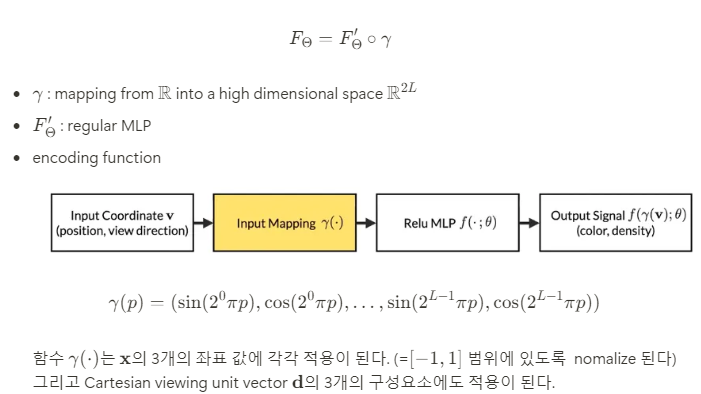
이러한 비슷한 mapping 방식이 Transformer의 positional encoding에서 확인할 수 있다. 하지만, Transformer에서는 sequence에서 token들의 discrete position을 제공하는 용도로 사용이 되기 때문에 순서에 대한 개념이 존재하지 않는다.
대조적으로, NeRF에서는 이 함수들을 연속적인 input 좌표를 더 높은 차원의 공간에 mapping 시켜서 MLP가 더 쉽게 higher frequency function에 근사할 수 있도록 사용한다.
Hierarchical volume sampling
카메라 ray를 따라서 N개의 query point들에서 neural radiance field network를 dense하게 evaluating 하는 rendering 전략은 비효율적이다. 왜냐하면 free space와 가려진 지역 같이 rendering 된 image에 영향을 주지 않는 영역도 반복적으로 sampling이 되기 때문에 연산량이 많아지기 때문이다.
그래서 이전 연구에서의 volume rendering과 sample들을 final rendering의 예상되는 효과에 비율에 맞게 할당함으로써 rendering 효율을 증가시키는 hierarchical representation을 제안했다.
Scene을 표현하기 위해 하나의 network만 사용하는 것이 아니라 동시에 2개의 network를 사용해서 하나는 coarse, 나머지 하나는 fine으로 최적화를 한다. 그 뒤, N_c location에 대해 stratified sampling을 사용해서 sampling 하고 coarse network에서 evaluate한다.

이러한 가중치를 전체 size로 나눠서 정규화하면 광선을 따라 부분적으로 일정한 확률밀도함수(PDF)가 생성된다. 역변환 샘플링[inverse transform sampling]을 사용하여 이 분포에서 N_f개의 위치들의 집합을 샘플링하고, 첫 번째와 두 번째 샘플 집합의 합집합에서 fine 네트워크를 평가하고, 모든 N_c+N_f개의 샘플을 사용하여 광선의 최종 렌더링된 색상을 계산한다.
Implementation details
각 장면에 대해 별도의 NeRF 표현 신경망을 최적화한다. 이를 위해서는 장면의 캡처된 RGB 이미지, 해당 카메라 포즈, intrinsic parameter, 장면 경계로 구성된 데이터셋만 필요하다. 각 최적화 iteration에서 데이터셋의 모든 픽셀 집합에서 카메라 광선 batch를 무작위로 샘플링한 다음 계층적 샘플링을 따라 coarse 네트워크의 N_c개의 샘플과 fine 네트워크의 N_c+N_f개의 샘플을 쿼리한다. 그런 다음 볼륨 렌더링 절차를 사용하여 두 샘플 집합 모두에서 각 광선의 색상을 렌더링한다. Loss는 단순히 coarse 렌더링과 fine 렌더링 모두에 대해 렌더링된 픽셀 색상과 실제 픽셀 색상 간의 총 제곱 오차이다.

Results
Datasets
Synthetic rendering of objects

Comparisons

- Synthesized dataset에서의 novel view synthesis

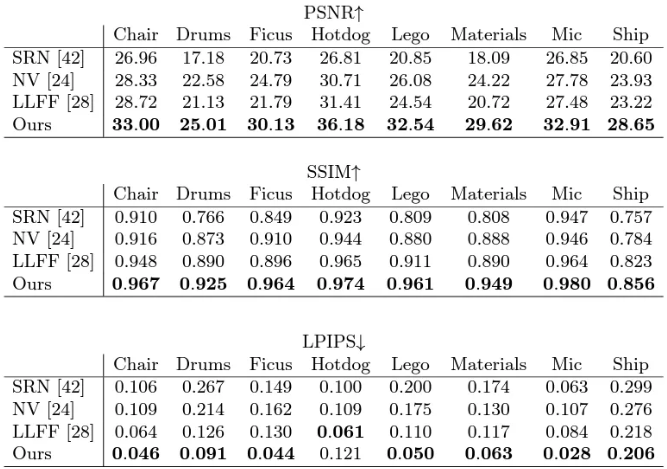
- Real-world image dataset에서의 novel-view synthesis


- DeepVoxels synthetic dataset으로부터 test-set view를 비교한 결과

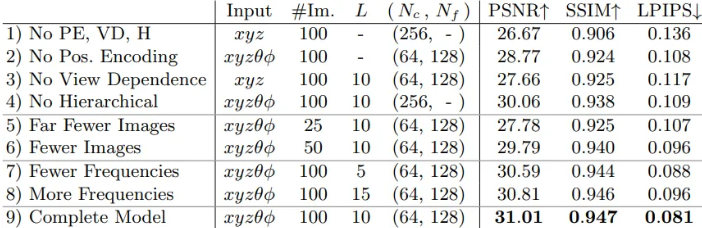
Ablation Study

Conclusion
Our work directly addresses deficiencies of prior work that uses MLPs to represent objects and scenes as continuous functions
Hierarchical sampling strategy를 사용해서 rendering이 더욱 sample-efficient하도록 했지만, 더 효율적으로 최적화하고 NeRF를 rendering 할 방법이 필요함
또 다른 연구로는 interpretability로, voxel grid나 mesh 같이 sampling된 representation들은 예상되는 rendering된 vievw의 quality가 있지만 deep neural network의 weight에서 scene들을 encoding 할때는 어떻게 분석해야 하는지가 불분명함