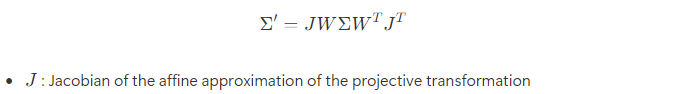Radiance Field method : 여러 장의 이미지나 비디오로 novel-view synthesis를 가능하게 하는 방법
하지만, 이 방식의 경우 고퀄리티로 복원을 하기 위해서는 training과 rendering cost가 커질 수 밖에 없다.
While recent faster methods inevitably trade off speed for quality
그래서 이 논문에서는 경쟁력있는 training time을 유지하면서 high-quality real-time novel view synthesis를 가능하게 하는 SOTA 방식을 위한 3가지 주요 요소들을 제안함
Camera calibration동안 생성된 sparse point로부터 시작해서 scene 최적화에 필요한 continuous volumetric radiance field들의 특징을 보존하는 3D Gaussian을 표현
3D Gaussian의 interleaved optimization/density control → anisotropic covariance를 optimize해서 정확한 scene을 표현하고자함
Anisotropic splatting을 지원하고 training과 real-time rendering을 가능하게 하는 빠른 Rendering algorithm
Introduction
Mesh와 point는 GPU/CUDA based rasterization에 최적이고 explicit하기 때문에 3D Scene representation에서는 매우 흔한 방식이였다.
하지만, NeRF는 continuous scene representation이고 포착한 장면에 대해 novel-view synthesis를 하기 위해 volumetric ray-marching을 사용해서 MLP [MultiLayer Perceptron]으로 최적화를 진행한다. 이 방식과 비슷하게 가장 효율적인 radiance field solution은 연속적인 표현을 voxel이나 hash grid, point등에 저장되어 있는 값들을 interpolating함으로써 얻어질 수 있지만, 이 방식들의 continuous한 특성은 최적화에는 도움이 되지만, rendering에 필요한 stochastic sampling은 cost가 많이 들고 noise가 생길 수 있다.
따라서 이 논문에서는 두 방식에서 좋은점만 가져왔다고 한다. 이 논문의 목표는 여러 장의 사진들로 포착한 scene들을 real-time으로 rendering해서 특정 real scene을 할 때 처럼 빠른 속도로 최적화해서 representation을 만드는 것이다.
Mip-NeRF360 : training time이 48시간이나 걸림. 빠르지만 quality가 낮은 radiance field 방식은 scene에 interactive한 rendering time을 얻을 수 있지만, 고해상도로 real-time rendering을 하는 것은 아직 한계가 보인다고 한다.
이 논문에서 제시하는 3DGS의 solution은 3가지 주요 요소를 기반으로 제시되었다고 한다.
1. Introduction of anisotropic 3D Gaussians as a high-quality, unstructured representation of radiance fields. : 이전의 NeRF와 같은 input으로 시작함 SfM [Structure-from-Motion] camera calibration으로 시작해서 이 과정에서 얻은 sparse point cloud를 3D Gaussian에 맞게 초기화함)
이전의 MVS [Multi-View Stereo] 방식과 달리 SfM point를 input으로 사용함으로써 고퀄리티의 결과를 얻을 수 있었다고 한다.
2. Optimization method of 3D Gaussian properties, interleaved with adaptive density control that creates high-quality representations for captured scenes : 3D position, opacity a, anisotropic covariance, spherical harmonic [SH] coefficients
이러한 optimization 과정은 scene에 대한 resonably compact, unstructured, precise representation을 생성한다.
3. Real-time rendering solution that uses fast GPU sorting algorithm : Visibility-aware, allows anisotropic splatting and fast back propagation to achieve high- quality novel view synthesis
💡We can optimize our 3D Gaussians from multi-view captures and achieve equal or better quality than the best quality prevoius implicit radiance field approach
Related Work
SfM [Structure-from-Motion]
: Camera calibration 동안 sparse point cloud를 추정해서 novel view synthesis를 가능하게 함
Deep learning 기법이 초창기에 novel-view synthesis를 위해 채택되었고 그 중에서 CNN이 blending weight를 추정하거나 texture-space solution을 위해 사용됨.
하지만, MVS-based geometry를 사용하는 것이 이런 방식들의 주요한 결점이고 CNN의 사용은 마지막 결과에서 temporal flickering의 결과를 보임
Novel view synthesis를 하기 위한 Volumetric representation은 Soft3D 부터 시작이됨. Deep Learning과 volumetric ray-marching의 결합은 geometry를 표현하기 위한 continuous differentiable density field를 형성하기 위해 점차 제안됨
하지만, volumetric ray-marching을 rendering하는 것은 volume을 query하기 위해 많은 수의 sample들이 필요하기 때문에 cost 측면에서 안좋음
그래서 Neural Radiance Fields [NeRF]가 quality를 높이기 위해서는 sampling과 positional encoding이 중요하다는 것을 알림. 하지만, NeRF의 경우 많은 MLP를 사용하기 때문에 속도 측면에서 부정적인 영향을 받음
따라서 NeRF의 후속 연구에서는 NeRF의 속도를 개선 시킬 방안을 찾게됨
현재의 SOTA 연구는 Mip-NeRF360인데 이 방식의 경우 rendering quality는 엄청 좋지만 training과 rendering 속도는 여전히 오래 걸림.
Point-Based Rendering and Radiance Fields
Point-based 방식은 disconnected, unstructured geometry sample들을 효과적으로 rendering 할 수 있게 해주었다. [e.g., point cloud]
하지만, point sample rendering 방식은 “hole” 때문에 골머리를 앓았는데, 이는 aliasing을 야기하고 strictly discontinuous하게 된다는 문제점이 있다.
따라서 이를 해결하고자 point를 splatting하는 방식으로 해결하고자 했다.
최근에 differentiable point-based rendering 기법에 관심이 많아졌고, 이러한 point들은 neural feature들과 CNN을 이용한 rendering으로 인해 augment되어 빠르고 심지어는 real-time으로 view synthesis를 가능하게 했다. 하지만, 이 방식은 여전히 초기 geometry는 MVS 방식에 의존하기 때문에 featureless하고 shiny area가 생성되기도 한다.
Point-based a-blending과 NeRF-style volumetric rendering은 같은 image formation model을 공유한다. 특히 color C가 ray를 따라서 volumetric rendering에 의해 주어진다.
위 2개의 식으로 통해 image formation model의 식은 같다는 것을 알 수 있음. 하지만, rendering algorithm은 매우 다름. 그 이유는 NeRF는 continuous representation으로 implicit하게 empty/occupied space를 표현하기 때문에 sample들을 찾기 위해 cost가 큰 random sampling이 필요하게 됨
반면에 point는 unstructured, discrete 표현 방식이기 때문에 [≠continuous] creation, destruction, displacement에 flexible함
Pulsar가 tile-based, sorting renderer에서 영감을 받아서 fast sphere rasterization을 성공함. 하지만, 우리의 목표는 sorted splat에서 conventional a-blending을 유지하면서 volumetric representation의 장점을 갖고 있는 것이기 때문에 우리의 rasterization은 order-independent한 방식들과 달리 visibility order를 중요시 여기고, pixel의 모든 splat들에서 gradient backpropagation을 수행하고 anisotropic splat을 rasterize함. 이로 인해 high visual quality를 얻을 수 있음
💡이 논문에서는 결과적으로 3D Gaussian을 더 효율적인 scene representation 방식이라고 생각해서 MVS geometry의 의존을 없애고 real-time rendering을 tile-based algorithm으로 가능하게 했다.
Overview
3DGS의 input은 static scene에서의 image 집합들이다. SfM으로 calibrate된 camera와 결합해서 sparse한 point cloud를 만들어 낸다.
생성된 point cloud로 부터 position[mean], covariance matrix, opacity a에 의해 정의된 3D Gaussian의 집합을 만들어서 매우 flexible한 optimization이 가능하다. 이를 통해 compact한 3D scene representation이 가능해진다. [매우 anisotropic한 volumetric splat이 fine structure들을 compact하게 표현할 수 있기 때문]
Radiance field의 색깔은 spherical harmonics [SH]에 의해 표현이된다.
결과적으로 이 방식은 3D Gaussian parameter들 [position, covariance, a, SH coefficients]을 연속적으로 최적화 하는 과정을 통해 Gaussian density의 adaptive control 연산과 interleave 되어 진행이 된다.
Differentiable 3D Gaussian Splatting
💡Our goal is to optimize a scene representation that allows high-quality novel view synthesis, starting from a sparse set of SfM points without normals
이를 위해 unstructured를 유지하면서 fast rendering이 가능한 동안 differentiable volumetric representation의 특성을 받는 primitive가 필요하다. 그래서 이 논문에서는 differentiable하고 쉽게 2D splat으로 projection이 되서 빠른 $\alpha$-blending이 가능한 3D Gaussian을 사용하게 되었다고 한다.
이 Gaussian이 blending 과정에서 a에 의해 곱해질건데, 그 전에 rendering을 위해 3D Gaussian을 2D로 project하는 과정이 필요하다
이 방식으로 직접적으로 covariance matrix Sigma를 최적화해서 radiance field를 표현하는 3D Gaussian을 얻을 수 있음
Independent optimization을 위해 이 둘을 각각 저장함 : 3D vector s [scaling], quarternion q [rotation]
또한 training 동안의 automatic differentiation으로 인한 overhead를 피하기 위해 explicit하게 모든 parameter들에 대해 gradient를 유도함.
Details of Gradient Computation
위의 식을 다시 정리하면,
결과적으로 quarternion normalization을 위한 gradient가 위와 같이 유도됨
Optimization with Adaptive Density Control of 3D Gaussians
Optimization
SGD [Stochastic Gradient Descent] : GPU framework와 몇몇 연산에 custom CUDA kernel을 추가할 수 있다는 장점을 최대한 활용
Sigmoid activation function : [0~1] 범위에 넣어서 smooth gradient를 얻고 exponential activation function을 사용해서 covariance를 scaling up함
Adaptive Control of Gaussians
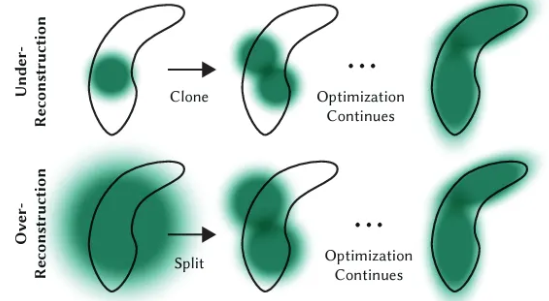
💡Our adaptive control of the Gaussians needs to populate empty areas
작은 gaussian들 [under-reconstructured region]에 대해 새로운 geometry를 만들어서 cover를 해야함. 이를 단순히 같은 크기의 gaussian을 clone해서 positional gradient 방향으로 이동시키는 방법을 채택. 반대로 너무 큰 gaussian들 [over-reconstructured region]의 경우는 기존의 gaussian을 split해서 작은 gaussian들로 만들어주는 방법을 사용 [scale factor phi=1.6]
Fast Differentiable Rasterizer for Gaussians
💡Our goals are to have fast overall rendering and fast sorting to allow approximate a-blending
이를 위해 Gaussian splat을 위한 tile-based rasterizer를 설계함
Fast rasaterizer는 낮은 memory 용량만 추가해서 임의의 blended Gaussian들에 대해 효율적인 backpropagation을 가능하게 했다.
Our rasterization pipeline is fully differentiable, and given the projection to 2D can rasterize anisotropic splats similar to previous 2D splatting methods
이 논문에서의 방식은 16x16 tile로 screen을 split해서 각각의 tile과 view frustum에 대해 3D Gaussian을 culling [원하지 않는 특성을 분리]함.
그 다음 Gaussian들을 tile의 개수에 따라 instance화 해서 각각의 instance에 key 값을 부여해서 view space의 depth와 tile ID를 결합할 수 있게 함. 이 key 값을 이용해 Gaussian들을 GPU Radix sort를 이용해서 정렬함
결과적으로 이 방식이 수렴된 scnee들에서 artifact들을 생성하지 않고 training과 rendering 성능을 향상시킬 수 있다고 한다.
Implementation, Results and Evaluation
Metrics
PSNR 영상 화질 손실량을 측정
SSIM 두 이미지x,y간의 상관계수를 Luminance, Contrast, Structure 측면에서 측정
LPIPS Classification Task를 Supervised, Self-supervised, Unsupervised 딥러닝 모델로 학습하고, 비교할 이미지 2개를 각각 학습된 Network를 사용해 deep feature[Activation 결과값]를 추출하고, 이를 비교하여 유사도를 평가