https://github.com/IDEA-Research/GroundingDINO
GitHub - IDEA-Research/GroundingDINO: [ECCV 2024] Official implementation of the paper "Grounding DINO: Marrying DINO with Groun
[ECCV 2024] Official implementation of the paper "Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection" - IDEA-Research/GroundingDINO
github.com
https://arxiv.org/abs/2303.05499
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
In this paper, we present an open-set object detector, called Grounding DINO, by marrying Transformer-based detector DINO with grounded pre-training, which can detect arbitrary objects with human inputs such as category names or referring expressions. The
arxiv.org
Abstract
Marrying Transformer-based detector DINO with grounded pre-training which can detect arbitrary objects with human inputs such as category names or referring expressions
Language Vision modality를 효과적으로 fuse하기 위해 closed-set detector를 3단계로 나눠서 tight fusion solution을 실시했다.
- Feature enhancer - language guided query selection
- Cross-modality decoder - modalities fusion
먼저 Grounding DINO 를 object detection data, grounding data, caption data 같은 large-scale dataset에 pre-training을 시킨 뒤open-set object detection과 referring object detection benchmark로 evaluate를 하는 형식으로 진행된다.

- 기존의 object detection : pre-trained model을 사용하여 annotated data에 대해서 detect
- Grounding DINO : 새로운 class에 대한 annotated data가 없어도 object detection 가능
Introduction

이 논문에서 저자들은 human language input에 의해 특정된 임의의 object들을 detect하는 강력한 시스템을 구축하는 것을 목표로 했다. 이를 “open-set object detection”이라고 부르기로 했다고 한다.
이를 위해 2가지 원칙을 따라서 목표를 추구했다고 한다.
1. DINO를 기반으로 한 tight modality fusion
2. Concept generalization을 위한 large-scale grounded pre-train
Tight modality fusion based on DINO
Open-set detection의 key는 language를 unseen object generalization으로 가져오는 것에 있다. 기존에 존재하는 대부분의 open-set detector들은 language 정보와 함께 closed-set detector들을 open-set으로 확장을 했다.
Closed-set detector의 경우 3가지 중요한 module들이 존재한다.
- backbone for feature extraction
- neck for ferature enhancement
- head for region refinement

Closed-set detector의 경우 새로운 object들을 language-aware region embedding들에 의해 detect하도록 generalize될 수 있다. 이로 인해 각각의 영역은 language-aware region embedding에 의해 새로운 category로 분류될 수 있다.
이 과정에서 region output과 language feature 사이의 contrastive loss가 사용된다.
Introducing more feature fusion into the pipeline can facilitate better alignment between different modality features
개념적으로는 단순해보이지만, 이전의 논문들은 feature fusion을 3단계로 진행을 하는 것이 쉽지는 않았다.
Faster RCNN같은 detector들은 대부분의 블럭에서 language information과 상호작용을 하는 것이 힘들었고, DINO 같은 transformer-based detector들은 language block들과 함께 consistent한 구조를 갖고 있따.
Layer-by-layer design이 language information과 쉽게 interact할 수 있도록 해준다. 이 원칙하에 3단계 feature fusion approach를 설계했다. [neck, query initialization, head]
Feature enhancer
Self-attention, text-to-image cross-attention, image-to-text cross-attention을 neck module로 stacking 해서 feature enhancer를 구성

Language-guided query selection
Detection head를 위해 query를 initialize
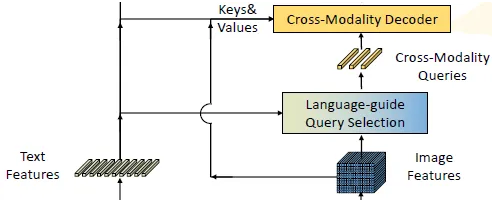

Cross-modality decoder
image-text cross-attention layer를 이용해서 query representation을 촉진

기존에 존재하는 대부분의 open-set model들은 pre-trained CLIP에 의존해서 concept generalization을 수행한다.
그럼에도, image-text pair pre-trained CLIP의 효용성은 region-text pair detection task를 수행할 때만 제한이 된다. 반대로 GLIP은 object detection을 grounding task로 재구성하고 large-scale data에 대한 object region과 language phrase간의 constrastive loss를 도입함으로써 다른 방식을 제안했다.
이 논문에서는 GLIP의 접근 방식인 grounded training을 약간의 refinement를 적용해서 이용을 했다. GLIP에서는 모든 category를 무작위 순서로 합치는 과정을 포함한다. 하지만, 직접적인 category명의 concatenation은 feature를 뽑아낼 때 서로 관련이 없는 category의 잠재적인 영향을 고려하지 않는다. 따라서 이를 완화하고자 이 논문에서는 sub-sentence level의 text feature들을 이용하는 기법을 도입해서 word feature를 뽑아낼 때 관련 없는 category 간의 attention을 제거한다.

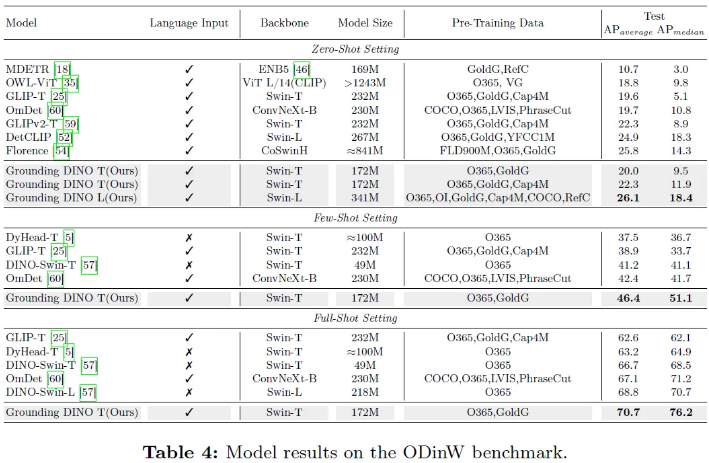
저자들은 이 3가지 setting들 [closed-set detection, open-set detection, referring object detection]에 대해 실험을 진행했고 COCO dataset에 대해 Grounding DINO가 높은 AP 값을 보인다는 것을 확인했다고 한다.

Related Work
Detection Transformers
DETR이라고도 불리는 end-to-end Transformer-based detector Detection Transformer는 Grounding DINO의 전신인 DINO의 base model이다.
DETR의 경우 DAB-DETR에는 DETR query로 anchor box를 줘서 더 정확한 box prediction을 도모했고, DN-DETR에서는 bipartite matching을 안정화시키기 위해 query-denoising 접근법을 제안했다. 이를 DINO에서는 더 나아가 contrastive denoising 방식을 사용해서 COCO dataset의 benchmark에 대해 SOTA를 달성했다고 한다.
하지만, 이러한 detector들의 경우 주로 closed-set detection에만 초점을 맞추고 제한된 pre-defined category로 인해 새로운 class들에 대해 일반화가 어렵다는 문제점이 있다.
Open-Set Object Detection
Open-Set object detection은 존재하는 bounding box annotation들을 이용해서 train되고 language generalization의 도움으로 임의의 class를 detect하는 것을 목적으로 하고 있다.
OV-DETR의 경우 CLIP으로 encoding된 image-text embedding을 query로 사용해서 category-specified box들을 DETR framework에서 decode한다.
ViLD는 CLIP의 teacher model에서 knowledge distillation을 R-CNN 계열 detector에 수행을 해서 학습된 region embedding들이 language의 semantic 정보를 갖고 있을 수 있도록 한다.
GLIP은 object detection을 grounding problem으로 형성하고 추가적인 grounding data를 leveraging해서 semantic을 phrase와 region level에서 align할 수 있도록 도와준다. 이를 이용했을 때 fully-supervised detection benchmark에서 상당히 좋은 성능을 낼 수 있었다고 한다.
DetCLIP은 large-scale image captioning dataset을 포함하고 있고 생성된 pseudo label들을 사용해서 knowledge db를 확장시킨다.
하지만, 이전의 작업들은 단순히 부분적인 단계에서 multi-modal 정보를 fuse하기만 하는데 이는 곧 sub-optimal language generalization ability로 유도하게 된다.
Grounding DINO

Grounding DINO는 주어진 [Image, text] pair에 대해 여러 object box, noun phrase pair를 output으로 내보낸다.
Grounding DINO는 dual-encoder-single-decoder 구조를 갖고 있는데, image feature extraction을 위한 image backbone, text feature extraction을 위한 text backbone, image와 text feature의 fusion을 위한 feature enhancer, quary initialization을 위한 language-guided query selection module 그리고 box refinement를 위한 cross-modality decoder를 포함한다..
각각의 [Image, text] pair에 대해 처음엔 vanilla image feature와 vanilla text feature들을 image backbone과 text backbone을 이용해서 뽑아낸다. 그 다음 두 개의 vanilla feature들은 cross-modality feature fusion을 위해 feature enhancer module로 들어가게 된다. Cross-modality text, image feature들을 얻은 뒤에는 language-guided query selection module을 이용해서 image feature들로 부터 cross-modality query들을 선택한다. 대부분의 DETR 계열의 object query들 처럼 이런 cross modality query들은 cross-modality decoder로 들어가서 2개의 modal feature [image, text]로부터 원하는 feature들을 탐구하고 스스로를 업데이트해나간다. 마지막 decoder layer의 output query들은 object box들을 예측하고 상응하는 phrase들을 뽑아내기 위해 사용된다.

1. Feature Extraction and Enhancer
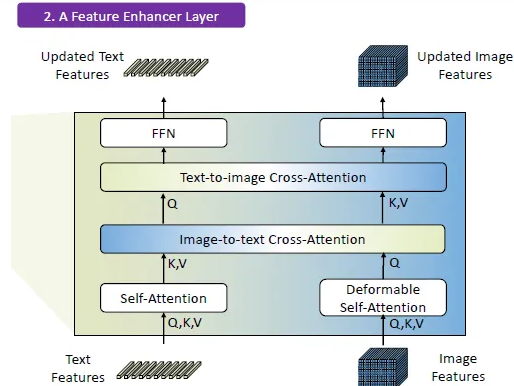
주어진 [Image, text] pair에 대해 이 논문에서는 Swin Transformer 처럼 image backbone에 대해 multi-scale image feature들을 뽑아내고 BERT처럼 text backbone에 대해 text feature들을 뽑아내었다.

이전의 DETR쪽 detector들에 따르면, multi-scale feature들은 서로 다른 block들로부터 뽑아내진다. Vanilla image, text feature들을 뽑아낸 뒤, 이것들을 cross-modality feature fusion을 위해 feature enhancer에 집어넣는다. Feature enhancer의 경우 multiple feature enhancer layer들을 갖고 있다. 그 뒤 image feature들을 향상시키고 text feature enhancer를 위한 vanilla self-attention을 하기 위해 deformable self-attention을 leverage했다고 한다.
GLIP에 영향을 받아서 image-to-text, text-to-image cross-attention module을 추가해서 feature fusion을 하려고 했다고하고 이 module이 서로 다른 modality의 feature들을 결합시키는데 큰 영향을 미쳤다고 한다.
2. Language-Guided Query Selection
Grounding DINO의 목표는 input text에 의해 특정된 image로 부터 object를 탐지하는 것이다. Input text를 object detection에 guide하기 위해 효과적으로 leverage하고자 language-guided query selection module을 설계해서 input text 중에서 decoder query로 가장 적합한 feature를 고르도록 하였다.

3. Cross-Modality Decoder

Cross-modality decoder를 이용해서 image와 text modality feature들을 결합하려고 했고 각각의 cross-modality query는 self-attention layer로 들어가서 image/text로 분화되서 feature들을 결합한 뒤 FFN layer로 들어가게 된다. 각각의 decoder layer는 추가적인 text cross-attention layer를 갖고 있고 더 나은 modality alignment를 위해 text information을 query들에 주입할 필요가있다.
4. Sub-Sentence Level Text Feature
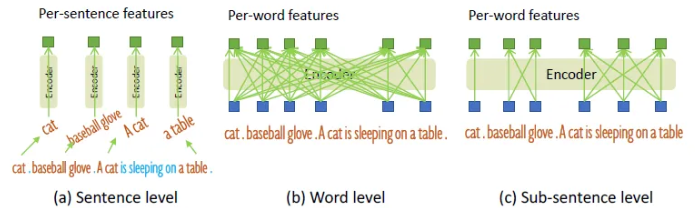
위의 그림에서 알 수 있듯이 2가지 종류의 text prompt들은 이전의 작업들에서 탐구되었고 “sentence level representation”, “word level representation”이라는 이름이 붙여졌다.
- Sentence level representation은 전체 sentence를 하나의 feature로 encoding한다.
- 만약 phrase grounding data에서 몇몇 문장들이 여러 phrase들을 갖고 있다면, 여기서는 이런 phrase들을 추출해서 다른 단어들을 버려버린다. 이 방식을 통해 문장에서 fine-grained information을 잃는 동안 단어들 사이의 영향을 없앨 수있다.
- Word level representation 은 여러 category 이름들을 한번의 forwarding에서 encoding 할 수 있지만, 특히 여러 category 이름들이 무작위적인 순서로 결합되어 있는 input text일 때 category들 간의 불필요한 dependency도 가져오게 된다.
- 원하지 않는 단어들의 interaction들을 피하기 위해 attention mask를 이용해서 unrelated category name들 사이의 attention을 막는 방법을 제안했다.
이를 “sub-sentence word representation”이라고 하기로 했다고 한다.
- 원하지 않는 단어들의 interaction들을 피하기 위해 attention mask를 이용해서 unrelated category name들 사이의 attention을 막는 방법을 제안했다.
5. Loss Function
- 이전의 DETR 계열 논문들을 참조해서 L1 loss와 GIOU loss를 사용해서 bounding box regression을 수행했다고 한다.
- GLIP을 따라서 예측된 object와 classification을 위한 language token들 사이의 contrastive loss를 사용했다고 한다.
- text feature들과 함께 각각의 query를 dot product를 통해 각각의 text token의 logit을 예측하고 그 logit에 대해 focal loss를 적용했다고 한다.
- Box regression과 classification cost는 prediction과 ground truth 사이의 bipartite matching에서 처음 쓰였다. 그 뒤 final loss를 계산하게 된다.
Experiment

Implementation Details
2개의 model 변수들을 이용해서 training을 시켰다고 한다.
- Swin-T + Grounding DINO T
- Swin-L + Grounding DINO L
이 둘을 이용해 image backbone으로 사용했다고한다.
BERT-base를 Hugging Face에서 leverage해서 text backbone으로 사용했다고한다. 이 논문의 목적 상 새로운 class들에 대해 model의 성능을 더 높이는 것에 초점이 맞춰져 있기 때문에 zero-shot transfer과 referring detection result들을 main text에서 list했다고 한다ㅓ.
- Default로 900개의 query들을 이용했고 최대 token의 개수를 256개로 설정했다고 한다.
- BERT를 text encoder로 사용
- Feature enhancer module에서 6개의 feature enhancer layer들을 사용
- Image cross-attention layer들에서 deformable attention을 leverage함
- Matching cost와 final loss 둘 다 classification loss [contrastive loss], box L1 loss, GIOU loss들을 포함한다.
- DINO를 따라서 classification cost의 weight, box L1 cost , GIOU cost를 각각 2.0, 5.0, 2.0으로 세팅했다고 한다.
- Hungarian matching 동안 상응하는 loss weight는 1.0, 5.0, 2.0으로 바꿔서 final loss를 계산했다고 한다.

Output




Conclusion
Grounding DINO는 DINO를 open-set object detection으로 확장해서 주어진 text에서 임의의 object들을 query로 detect하게 했다.
이 논문에서는 Open-set object detector의 design을 다시 확인해서 cross-modality 정보를 더 잘 fusing하도록 tight한 fusion 방식을 제안했다.
또한 sub-sentence level representation을 제시해서 더 합리적인 방식으로 text prompt를 위해 detection data를 사용할 수 있도록 했다.
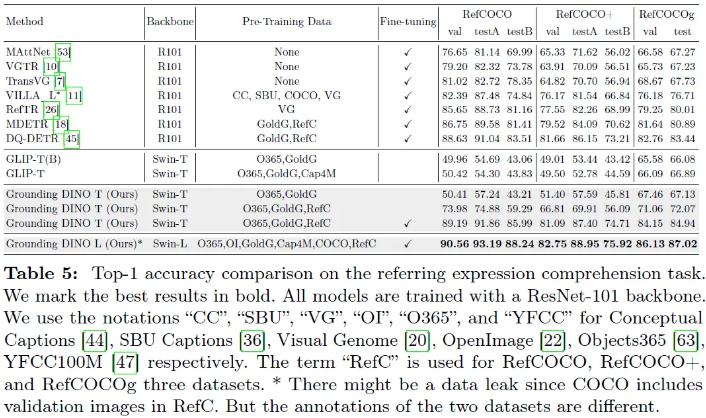
더 나아가 open-set object detection을 REC [Referring Expression Comprehension] task로 확장시켜서 evaluation을 수행했다. 기존의 REC data에서는 fine-tuning 없이는 opens-set detector가 동작하기 힘들었기 때문에 추가적인 attention을 호출해서 REC를 zero-shot performance로 적용시켜볼 예정이라고 한다.
Limitation
- Grounding DINO의 경우 segmentation task에 적용이 안된다.
- Grounding DINO가 몇몇 case에서 false positive [가짜를 진짜로 잘못 판단하는 경우] 결과를 도출한다는 문제점이 있다. 이 경우 hallucination을 줄이기 위해 더 많은 technique와 data가 필요하게 된다.