[논문] Masked Autoencoders Are Scalable Vision Learners
·
Paper Review/Baseline
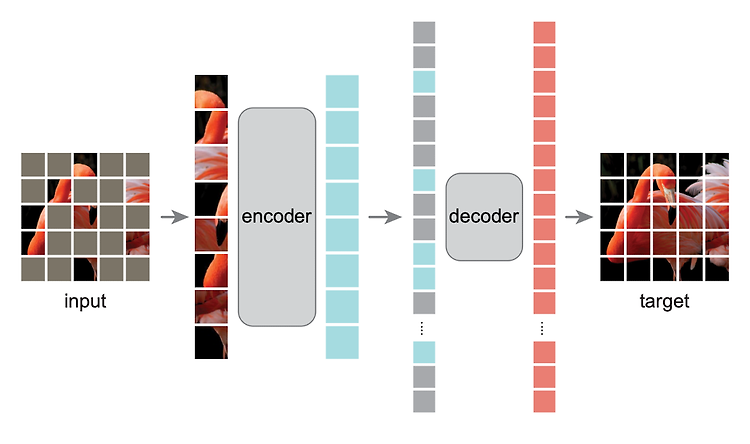
논문 출처https://arxiv.org/abs/2111.06377 Masked Autoencoders Are Scalable Vision LearnersThis paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision. Our MAE approach is simple: we mask random patches of the input image and reconstruct the missing pixels. It is based on two core designs. First, wearxiv.orgAbstract이 논문에서는 MAE [Masked Autoencoder]가 comput..