Stacked Hourglass Networks for Human Pose Estimation
This work introduces a novel convolutional network architecture for the task of human pose estimation. Features are processed across all scales and consolidated to best capture the various spatial relationships associated with the body. We show how repeate
arxiv.org
GitHub - princeton-vl/pytorch_stacked_hourglass: Pytorch implementation of the ECCV 2016 paper "Stacked Hourglass Networks for H
Pytorch implementation of the ECCV 2016 paper "Stacked Hourglass Networks for Human Pose Estimation" - princeton-vl/pytorch_stacked_hourglass
github.com
Abstract
Novel Convolutional Network architecture for Human Pose Estimation

Features are processed across all scales and consolidated to best capture the various spatial relationships associated with the body
이 논문을 통해 intermediate supervision의 중요성, 반복되는 bottom-up, top-down processing이 네트워크의 성능을 향상시킴에 있어서 왜 중요한지를 보여줄 예정이다.
Introduction
Image와 Video에서 사람을 이해하는 것에 있어서 가장 중요한 것은 정확한 pose estimation이다.
주어진 하나의 RGB 이미지에서 사람의 몸에 있는 중요한 keypoint가 어느 픽셀에 위치하고 있는지를 결정하는 것이 핵심이다. 사람의 자세와 관절의 움직임 등을 이해해야 action recognitoin 같은 더 높은 레벨의 task를 수행할 서있고 HCI나 animation의 기본적인 tool로써 역할할 수 있다.
A good pose estimation system must be robust to occlusion and severe deformation, successful on rare and novel poses, and invariant to changes in appearance due to factors like clothing and lighting
⇒ 즉, 좋은 pose estimation system을 구축하기 위해서는 가려진 부분, 역동적인 신체 움직임, 흔하지 않거나 새로운 pose에 robust하고 clothing이나 lighting 등에 상관 없이 invariant 해야 한다.
기존의 방식들은 ConvNet을 사용했지만, 지금부터는 이 논문에서 제시하는 SHG를 사용.
- The network captures and consolidates information across all scales of the image
- Hourglass design == Steps of pooling and subsequent upsampling used to get final output
- Hourglass network pools down to a very low resolution, then upsamples and combines features across multiple resolutions
- ≒ pixel-wise output from convolutional approaches
- ≠ prior designs in its more symmetric topology
- Expand single hourglass by consecutively placing multiple hourglass modules end-to-end
: Repeated bidirectional inference
Related Work
Related Work | Notion
DeepPose: Human Pose Estimation via Deep Neural Networks (CVPR 2014)
hjcertification.notion.site
Related work는 노션에 정리를 해두었습니다
Network Architecture
Hourglass Design

Hourglass의 디자인은 모든 scale에서 information을 가져와야하는 필요성에 의해 영감을 받았다고 한다. Local evidence는 얼굴이나 손 같은 feature를 확인하는데 필수적이고, Final pose estimation은 전체 몸의 일관성 있은 이해를 요구한다.
Image의 다양한 scale에서 최선으로 확인할 수 있는 다양한 실마리에는 사람의 방향, 관절의 위치, 인접한 관절들의 관계 등이 있다.
The hourglass is a simple, minimal design that has the capacity to capture all of these features and bring them together to output pixel-wise predictions
이를 위해 네트워크는 다양한 scale에서 뽑아낸 feature들을 효율적으로 처리하고 병합할 메커니즘이 필요하다. 몇몇 접근 방식은 별도의 pipeline을 추가해서 이러한 feature들을 처리하지만 이 논문에서는 각각의 resolution에서 spatial information을 보존할 수 있도록 skip layer를 추가해서 하나의 pipeline으로 진행할 수 있도록 했다고 한다.
Hourglass Setting
- Convolutional layer and max pooling layer들은 feature들을 매우 낮은 차원으로 보내는 역할을 함
- 각각의 max pooling step에서 network는 분기해서 원래의 pre-pooled resolution에 더 많은 convolution이 적용될 수 있도록 함
- 가장 낮은 차원에 도달한 뒤에 네트워크는 upsampling하는 top-down 과정을 진행하고 scale 마다 feature들을 합침
- 2개의 인접한 resolution의 정보를 함께 가져오기 위해 2개의 feature들을 element-wise addition을 한 뒤 graphical model의 과정을 따라서 nearest neighbor upsampling을 진행함
The topology of the hourglass is symmetric, so for every layer present on the way down there is a corresponding layer going up
: Stacked Hourglass Network는 대칭성을 갖고 있기 때문에 올라가는 layer도 같은 형태임
- 네트워크의 output resolution에 도달하면 2개의 연속적인 1x1 convolution에 통과되어 최종적인 예측 결과를 생성함. 이 예측 결과는 heatmap의 형태이고 모든 pixel에서의 각각의 joint의 예상되는 위치에 대한 정보를 갖고 있음
Layer Implementation
전체 hourglass 형태는 유지하면서 특정 상황에서의 융통성을 보일 필요성이 있음
예를 들어,
- Value of reduction steps with 1x1 convolutions
- Benefits of using consecutive smaller filters to capture a larger spatial context : replace 5x5 filter with 2 separate 3x3 filters
여러 design을 실험해보고 서로 다른 module들을 swapping도 해보았다고 함
결론적으로 더 큰 filter로 바꾸고 ResNet에서 보여준 residual learning module이나 Inception-based design 같은 reduction step들을 추가하지 않았을 때 성능이 가장 좋게 나왔다고 함

256x256 해상도의 전체 input을 그대로 사용하는 것은 GPU memory 소비량이 많아지기 때문에 hourglass의 가장 높은 해상도는 64x64로 설정했다고 한다. 이렇게 줄여도 network가 정확하게 joint의 위치를 예측하는 것에는 아무 문제가 없다고 한다.
전체 network는 stride 크기가 2인 7x7 convolutional layer로 시작을 해서 residual module, max pooling layer를 거쳐 해상도가 256x256에서 64x64로 바뀌게 된다.
2개의 연속적인 residual module들이 hourglass를 계속 진행시키는데 이 residual module이 전체 module에서 256개의 feature들을 만들어낸다고 한다.
Stacked Hourglass with Intermediate Supervision
We take or network architecture further by stacking multiple hourglasses end-to-end, feeding the output of one as input into the next
Repeated bottom-up, top-down inference가 초기 예측값과 전체 이미지에서의 feature들을 다시 측정할 수 있게 해준다. 이 과정에서 가장 중요한 접근 방식은 loss 함수를 적용할 수 있는 intermediate heatmap을 예측하는 것이다.
예측 결과들은 network가 local, global context 모두에 대해 feature들을 다룰 수 있도록 각각의 hourglass 마다 생성된다. 연속적인 hourglass module들이 이를 가능하게 해준다.
만약 network가 가장 최선의 수정된 예측값을 만들도록 하기 위해서는 예측값들이 배타적으로 local scale에서 evaluate되면 안된다. Joint prediction 뿐만 아니라 general context와 전체 image 자체를 이해하는 것이 중요하다.
Pooling을 하기 전에 pipeline에서 이른 시점에 supervision을 적용하는 것은 가능은 하지만, 주어진 pixel에서의 feature들은 상대적으로 local receptive field에서 다뤄진 결과이기 때문에 중요한 global cue에 대해서는 무지하다.
이러한 걱정을 줄여주는 것이 “Repeated bottom-up, top-down inference with stacked hourglasses”이다.
Local and global cues are integrated within each hourglass module, and asking the network to produce early predictions requires it to have high-level understanding of the image while only partway through the full network
이 접근 방식은 final localization step을 위해 feature들의 spatial information을 유지해야 하기 때문에 scale 전반에 걸쳐 특히나 중요하다. 정확한 관절의 위치가 network에 의해 만들어진 서로 다른 decision에서 필수불가결인 cue이다.
Pose estimation 같이 구조적인 문제가 있는 경우 output은 서로 다른 많은 feature들의 interplay에 의해 결정되기 때문에 scene에 대한 일관성 있는 이해 방식을 형성하는 것이 중요하다.
그래서 중간 시점의 예측 결과를 더 큰 수의 channel들에 mapping 시킴으로써 $1\times 1$ convolution이 있는 feature space로 다시 가져온다.
- Weights are not shared across hourglass modules
- Loss is applied to the predictions of all hourglasses using the same ground truth
Training Details
Dataset
1. FLIC
FLIC dataset
Frames Labeled In Cinema (FLIC) Brought to you as part of our paper on MODEC. Download Released April 7, 2013. FLIC.zip287MB5003 examples used in our CVPR13 MODEC paper. FLIC-full.zip1.2GB20928 examples, a superset of FLIC consisting of more difficult exam
bensapp.github.io

2. MPII Human
MPII Human Pose Dataset - Max Planck Institute for Informatics
www.mpi-inf.mpg.de

Loss
Mean-Squared Error [MSE] Loss is applied comparing the predicted heatmap to a ground-truth heatmap consisting of 2D Gaussians
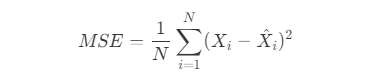
Results

Evaluation
standard Percentage of Correct Keypoints [PCK]로 측정

Joint의 추정 좌표와 정답 좌표의 거리가 특정 임계값 보다 작으면 해당 추정 좌표가 옳다고 판단.
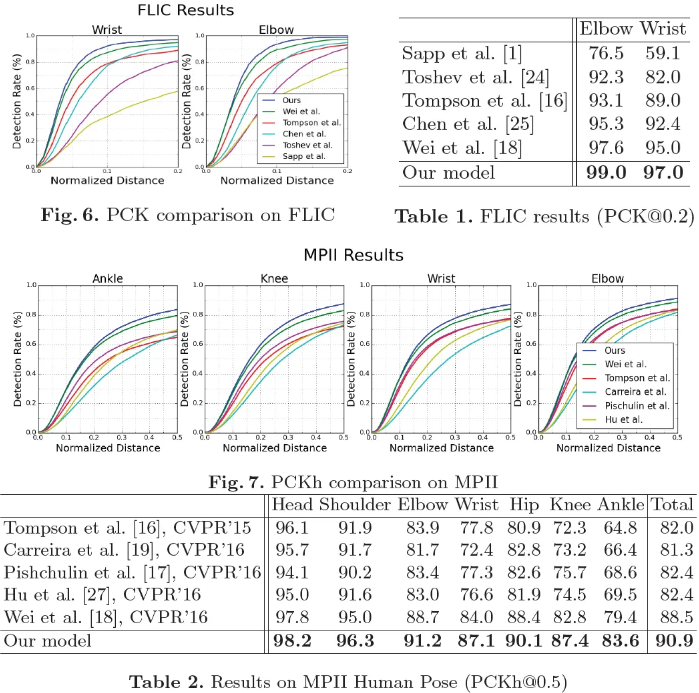
FLIC
: Figure6과 Table1을 통해 elbow에서 99% PCK@0.2 accuracy를 보였고, wrist에서는 97%의 PCK를 보였다고 한다.
주목할 점은 이 결과들이 observer-centric이기 때문에 어떻게 다른 사람들이 FLIC에서 output을 평가하는지에 달려있다고한다.
MPII
: MPII에서 모든 joint에 대해 SOTA 성능을 달성했다고 한다. Wrist [손목], elbow [팔꿈치], knees [무릎], ankles [발목] 같은 서로 다른 joint들에서 기존의 SOTA 성능보다 3.5% 성능을 향상시켰고, error는 16.3%에서 12.8%로 줄었다고 한다.
최종적인 elbow accuracy는 91.2%, wrist accuracy는 87.1%가 측정되었다고 한다.
Ablation Experiments
이 논문에서 저자들은 2개의 main design 선택을 탐색했다고 한다.
- The effect of stacking hourglass modules together
- The impact of intermediate supervision
이것들은 전체 architecture design에 따라 어떻게 intermediate supervision을 적용하는지에 따라 제한되기 때문에 상호 독립적이 아니다.
별개로 적용을 하면 각각은 성능에 긍정적인 영향을 주지만, 이를 다같이 적용하면 훨씬 더 향상된 training speed를 보였고 최종적인 pose estimation 성능도 향상되었다고 한다.
The effect of stacking hourglass modules together
1번에서 stacked hourglass design이 어떤 영향을 주는지 확인하기 위해 architecture shape의 성능 변화와 더 크고 깊어지는 network의 용량의 증가에 달려있지 않다는 것을 설명해야 한다.
이를 위해 8개의 stacked hourglass가 같이 있는 baseline network를 갖고 실험을 했다고 한다. 각각의 hourglass는 각각의 resolution에 대해 하나의 residual module을 갖고 있으며, 실험은 hourglass의 위치를 섞는 과정으로 진행되었다고 한다.

결과적으로 hourglass 개수의 감소는 각각의 hourglass의 capacity를 증가시켜 주었다. 예를 들어,
- 4개의 hourglass와 2개의 연속적인 residual module == HG-Stacked
- 각각의 stage마다 hourglass에 2개의 stacked network, 4개의 연속적인 residual module이 있는 1개의 hourglass와 8개의 residual module == HG
이 둘을 비교하면, Figure8에서 확인할 수 있듯이 같은 숫자의 layer와 parameter를 갖고 있다고 하더라도 stacked 구조가 더 향상된 training을 보였다
The impact of intermediate supervision

Figure9에서 validation accuracy를 2-,4-,8-stack model에 대해 확인을 했다고 한다. 결과는 87.4% → 87.8% → 88.1%로 약간의 상승이 있었다는 것을 알 수 있다. 이러한 상승은 intermediate stage에서 두드러지는데 84.6% → 86.5% → 87.1%로 더 큰 폭으로 상승하는 것을 확인할 수 있다.
Figure9를 보면 좌우의 heatmap이 살짝은 애매모호하다는 것을 확인할 수 있다. 하지만, 이미지를 보면 confusion이 정당화된다.
가운데 예시를 보면 image에서 보이는 부분의 손목에만 network가 적용된 것을 확인할 수 있다. 그렇기 때문에 heatmap을 더 처리하는 것은 원래의 위치에 대해 전혀 적용되지 않고 가려진 부분이 있을 법한 가장 합리적인 위치를 선택하게 된다.
Further Analysis
Multiple People
Network는 누구를 annotate 할지를 결정해야 한다. 하지만, 누가 annotation을 받아야하는지에 대한 communication option이 제한적이다. 전체 ㅔ과정에서 signal을 주고 받는 과정은 target person을 parsing 하기 충분하도록 scaling 하고 중심에 놓는 과정이 있다. 하지만, 이 방식은 때때로 사람들이 엄청 가까이 붙어 있거나 겹쳐져 있는 경우 애매한 상황에 놓여지게 된다.

Figure 10에서 한 사람에 대해 pose prediction을 만들도록 training을 했기 때문에 한 사람에만 prediction 결과가 보이는데 겹치는 부분으로 인해 애매한 상황이 보여지게 된다.
Occlusion
Occlusion은 2개의 category로 구분될 수 있기 때문에 평가하기가 어렵다.
- Joint는 보이지 않지만 이 위치가 image의 context 상 분명한 경우
- 특정한 joint가 어디에 있는지 어떠한 정보도 없는 경우
Stacked Hourglass Network는 어떠한 추가적인 visibility annotation들을 사용하지 않는다.

Occlusion is clearly a significant challenge, but the network still makes strong estimates in mose cases
이 논문에서는 더 극단적으로 joint가 완전히 가려져 있거나 잘려있어서 annotation을 전혀 할 수 없는 경우도 고려했다고 한다.
PCK metric은 이러한 상황이 network에 의해 확인되는 것에 영향을 받지 않는다. 그렇기 때문에 모든 joint에 대해 예측을 하는 것에 아무 문제가 없다는 것을 확인했다.
We observe that our network gives consistent and accurate predictions of whether or not a ground truth annotation is available for a joint
Conclusion
The network handles a diverse and challenging set of poses with a simple mechanism for reevaluation and assessment of initial predicitions
- Intermediate supervision is critical for training the network, working best in the ciontext of stacked hourglass modules.
- Overall system shows robust performance to a variety of challenges including heavy occlusion and multiple people in close proximity