
Abstract
복잡한 pose를 취하고 있는 사람이나 옷이나 헤어스타일 등을 리얼하게 복구하는 것은 보이지 않는 영역을 예측하는 것 뿐만 아니라 중요한 task들 중 하나로 여겨져 왔다. 하지만 이전의 모델들은 2D image를 3D로 변환하고 texture를 예측하는 것에 있어서 prior guidance가 충분하지 않다는 점이 문제가 되어왔다. 따라서 본 논문에서는 SIFU [Side-view Conditioned Implicit Function for Real-world Usable Clothed Human Reconstruction]이라는 모델을 제안해서 이를 해결하고자 했다.
SIFU는 transformer의 cross-mechanism을 사용하였고, SMPL-X를 이용해서 2D feature들을 3D로 mapping 시키는 과정에서의 side-view feature들을 효과적으로 decoupling 시켰다.
이 방법의 경우 3D model의 정확도를 향상시킬 뿐만 아니라 robustness도 향상시켰다. 이를 통해 geometry, texture reconstruction 분야에서 SOTA를 달성할 수 있었다고 한다.

Introduction
AR/VR, 3D Printing 등의 분야가 점점 진화함에 따라 고퀄리티의 clothed human 3D model의 필요성과 중요성이 증가하고 있다. 하지만, 지금까지의 방식들은 시간도 오래걸릴 뿐더러 다양한 view에서 사진을 찍는 장비, 그리고 전문가의 손길이 없으면 퀄리티를 보장하지 못했다.
그렇기 때문에 휴대폰 카메라나 웹 상에서 쉽게 구할 수 있는 image들로 monocular image에 접근을 할 수 있어야하므로 이 논문에서는 하나의 image에서 정확하게 3D human model을 reconstruct하는 방식을 고안하게 되는데 단순히 방식을 만들어내는 것 뿐만 아니라 시간과 연산량으로 인한 cost를 상당히 줄이고 각각의 생성 과정을 단순화시켰다.
딥러닝 방식들의 경우 이 분야에 효과가 있음이 밝혀졌지만, 머리카락이나 옷의 texture들을 완전히 복구하는 것에는 한계점을 보였고, 잘 안보이는 영역은 더 안되는 것을 확인할 수 있었다.
Therefore, there's a significant need for models that can generalize across various scenarios and efficiently produce realistic, real-world applicable 3D clothed humans
이 논문에서 저자들은 2가지 문제점에 초점을 두었다.
Insufficient Prior Guidance in Translating 2D Features to 3D
2D image들로부터 3D object를 복원하는 것은 크게 3가지 step에 걸쳐 일어난다.
- 2D image에서 feature들 뽑아내기
- 2D feature들을 3D로 translating
- 3D features for reconstruction

2D image feature들을 3D로 transition 하는 성능을 향상시키기 위해 prior를 사용하는 것은 여전히 연구해야 할 내용이 많기 때문에 transition의 경우 3D point들에 feature들을 projection하는 과정으로 진행이 된다. 하지만, 이 방법 역시 3D reconstruction의 정확도를 높이기 위해 prior를 완전히 사용하지는 않는다는 문제점이 있다.
Lack of Texture Prior
현재 진행중인 연구들의 경우 vertex color들을 예측하려고 하지만, 보이지 않는 view에 대해서는 제한적인 training data로 인해 정확한 예측이 잘 되지 않는다.
이 2가지 challenge들을 해결하기 위해 연구자들은 3D human reconstruction의 성능을 높이기 위해 2가지 전략들을 사용한다.
- 추가적인 guidance를 사용해서 2D feature들을 3D로 translate하는 과정은 3D reconstruction의 정확도와 효율성을 향상시킬 수 있다.
- pretrained diffusion model들의 생성하는 능력과 풍부한 3D prior 표현력을 보았을 때, 보이지 않는 영역에 대해 diffusion model을 사용해서 texture prediction을 하면 더 높은 정확도를 보일 것이다.
먼저 첫번째의 경우를 보면, SMPL-X와 image feature들의 prior guidance를 결합하기 위해 이 논문에서는 transformer의 cross-attention mechanism을 사용했다고 한다.
SMPL-X
smpl-x.is.tue.mpg.de
SIFU의 경우는 SMPL-X를 cross attention에서 image feature들과 함께 query로 사용해서 normal의 역할로 사용했다고 한다. 이 방식을 사용하게 되면 2D를 3D로 mapping하는 과정에서 side-view feature들을 효과적으로 decoupling할 수 있고 결과적으로 accuracy와 robustness가 증가하게 된다고 한다.
SIFU의 경우 복잡한 동작이나 헐거운 옷 같이 detail을 요구하는 feature에 대해서도 잘 다루고, color와 pattern을 유지하면서 realistic한 texture를 만들어낼 수 있다고 한다.
Method

Preliminary
Implicit Function
Implicit Function은 복잡한 geometry와 color를 neural network를 이용해서 modeling하기에 강력한 도구 중 하나이고, implicit function의 효과는 PIFu와 PIFuHD에서 증명이 되었다.

SMPL and SMPL-X
SMPL [Skinned Multi-Person Linear model]은 human body를 표현하기 위한 parametric model이다. 여기서는 shape parameter beta와 pose parameter theta를 사용해서 표현한다.

SMPL-X는 SMPL과 비슷한데, SMPL의 경우 전체적인 몸의 형태를 위주로 parameter화 했다면, SMPL-X는 손과 얼굴에 대한 feature도 추가해서 얼굴 표정, 손가락 움직임 같은 detail한 사람의 움직임에 대한 표현력을 강화시켰다.
Diffusion model
DPM [Diffusion Probabilistic Model]은 image와 human/avatar 생성하는데 있어서 핵심적인 모델이다. 이 모델은 data distribution q를 denoising 과정을 통해 근사하는 것을 목표로 하고있고, 더 나아가 text conditioning 같은 추가적인 guiding signal들로 conditional distribution을 학습하기도 한다.
Side-view Conditioned Implicit Function
이 논문에서의 Side-view Conditioned Implicit Function은 2가지 핵심 요소로 구성되어 있다.
- Side-view Decoupling Transformer
- Hybrid Prior Fusion Strategy
Side-view Decoupling Transformer
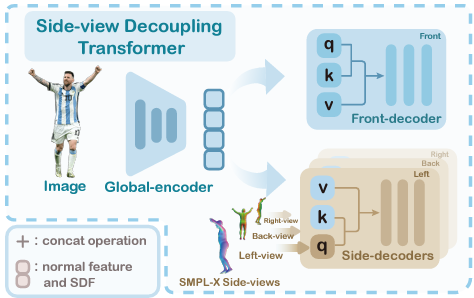
이 과정은 input image를 latent feature로 encoding해서 correlated feature를 찾아내는 ViT-based global encoder에서 시작하고, 2가지의 decoder [front-view decoder / side-view decoder]로 넘어가게 된다.
먼저 front-view decoder에서는 multi-head self-attention을 사용해서 front-view feature들을 만들어낸다.
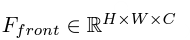
그 다음으로, side-view decoder에서는 SMPL-X를 guidance를 사용해서 side-view normal image [left / back / right]들을 rendering한다.
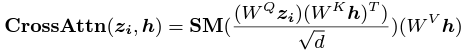
이 둘을 구분한 이유는 front-view는 2D image에서도 쉽게 보이는 영역이지만, 옆이나 뒤의 경우 안보이거나 가려지기 쉬운 부분이기 때문에 구분을 한 것이다.
Hybrid Prior Fusion Strategy
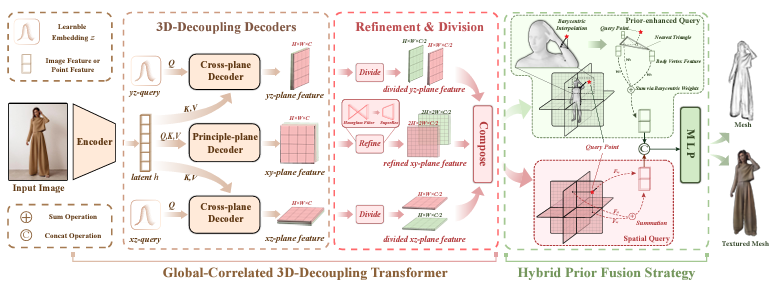
위 그림은 [Global-correlated 3D-decoupling Transformer for Clothed Avatar Reconstruction] 이라는 논문에서 등장한 Hybrid Prior Fusion Strategy에 대한 내용이고, 이 논문에서 등장한 방식은 아래 그림과 같다.
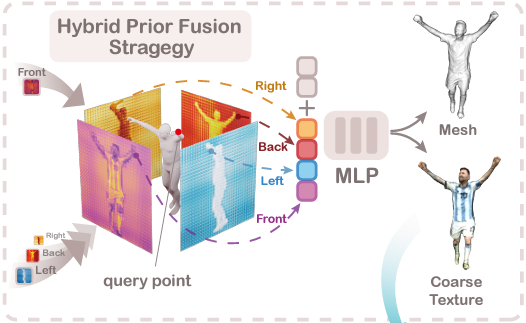
Hybrid Prior Fusion Strategy를 사용해서 query-point에서 쉽게 feature들을 합쳐서 spatial localizaiton과 human body prior knowledge에서 사용했다고 한다. 이 논문에서는 feature map F를 [front, left, back, right]에서 2개의 그룹으로 쪼갠 뒤 pixel-aligned feature를 얻기 위해 query point를 feature map에 project해서 이 feature들을 결합했다고 한다.
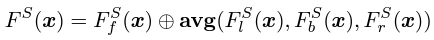
그 뒤 SMPL-X Mesh를 feature map에 project해서 feature를 얻고 각각의 query point x에 대해서 가장 가까운 triangular face t_x를 찾은 뒤 barycentric interpolation으로 feature들을 합쳤다고 한다.
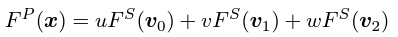
이들을 모두 합쳐서 MLP를 통과시키면 다음의 값을 얻게 된다.
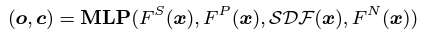
Traning Objectives
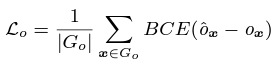
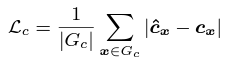
Mesh Extraction
Dense하게 point들을 sampling 했다면 이제부터는 Side-view conditioned implicit function을 이용해서 occupancy value를 예측하는 task를 하게 된다.
이 과정에서 Marching cube algorithm이 mesh를 추출하는데 사용되고 SMPL-X로 visual을 향상시키게 된다. 마지막으로, 이 mesh point들이 다시 implicit function에 처리가 되어 color prediction이 수행되게 된다.
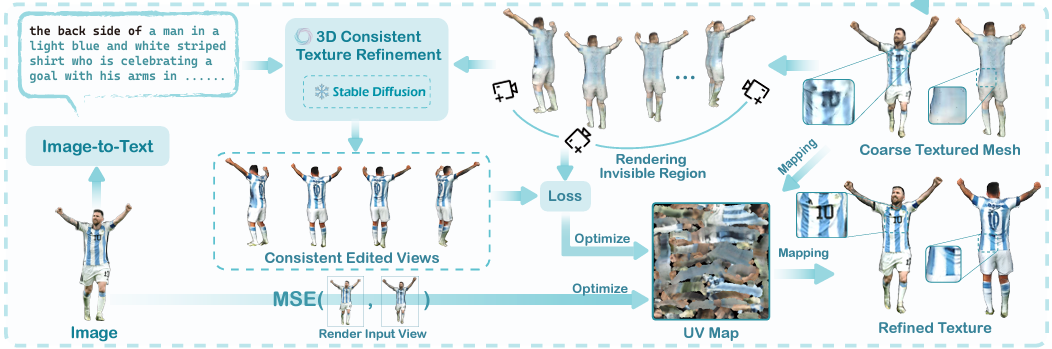
3D Consistent Texture Refinement
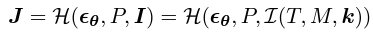
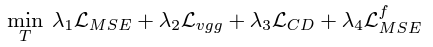
Experiment
Dataset
이 논문에서는 THuman2.0 dataset을 사용하였고, SMPL-X가 training, PIXIE가 inference 동안 사용되었다.
Evaluation의 경우 CAPE와 THuman2.0이 사용되었다고 한다.
Metric
Chamfer distance
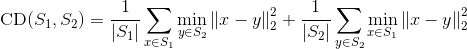
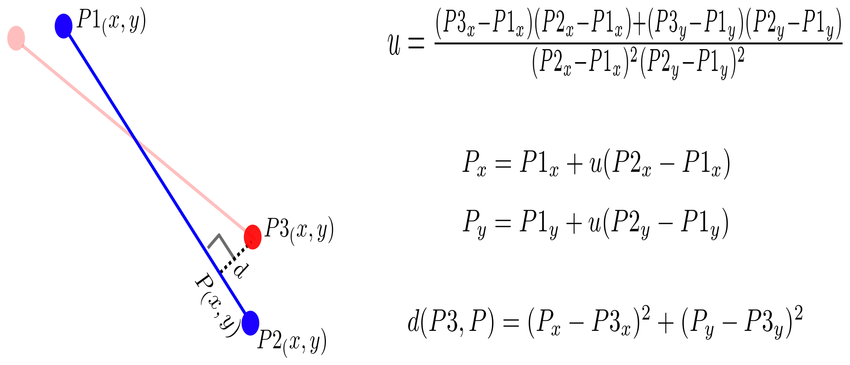
P2S distance [Point to Segment]
Result
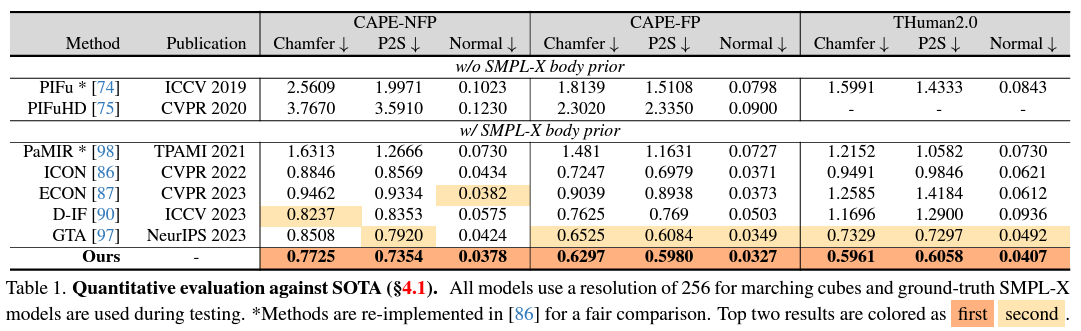
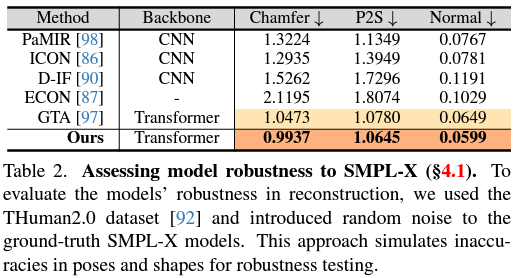
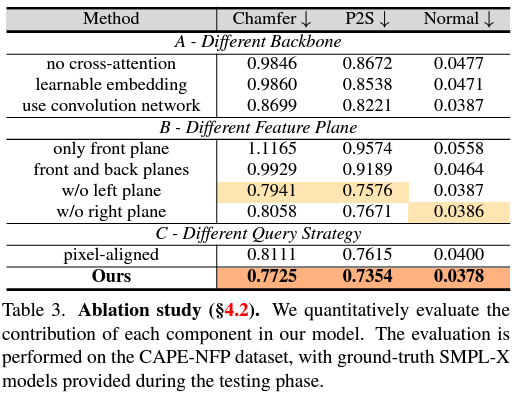
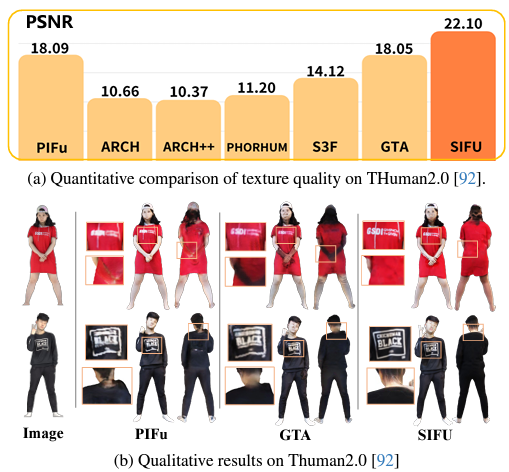
SOTA Model들과 비교했을 때 quality 측면에서 향상이 많이 이뤄졌다고 한다.

윗쪽이 loose cloth를 입은 사람이고, 아래쪽이 다양한 pose를 취하고 있는 사람들을 reconstruct한 결과이다.

Texture-editing도 되고

impressive scene도 표현이 가능하다고 한다.
Conclusion
결론적으로 SIFU는 detail한 texture를 가진 고퀄리티의 3D clothed human을 복원하는 새로운 방식을 제시했다고 할 수 있다. 이 논문에서는 SMPL-X normal을 image feature와 함께 cross-attention mechanism의 query로 이용하여 2D image를 3D로 변환하는 과정에서 효과적으로 side-view feature들을 분리할 수 있었다. 이를 통해 accuracy와 robustness가 상당히 향상되었다.
게다가 이 논문은 3D Consistent Texture Refinement process라는 것을 설계해서 latent space에서 diffusion feature의 consistency를 유지하면서 text-to-image diffusion prior를 사용할 수 있었다.
SIFU는 결과적으로 PIFU나 PIFUHD같은 기존의 SOTA model들을 뛰어 넘었고, geometric, texture fidelity의 관점에서 복잡한 pose와 loose clothing 같은 것들을 잘 다룰 수 있었다. 고로 real-world에 적합하다고 한다.