코너
코너의 특징
- 평탄한 영역 & Edge 영역은 고유한 위치를 찾기 어려움
- 따라서 변별력이 높고 영상의 이동, 회전 변환에 강인한 코너를 검출함

다양한 코너 검출 방법
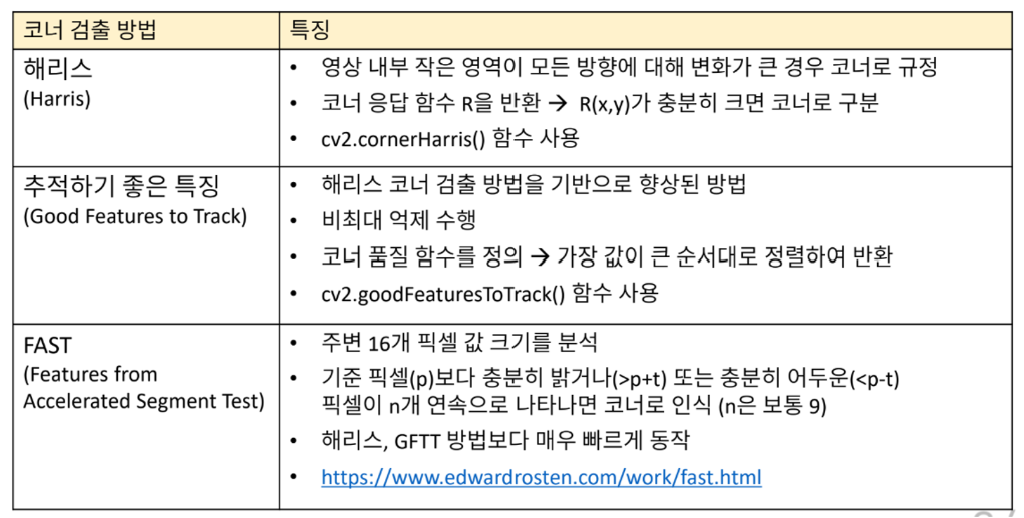
해리스 코너 응답 함수 계산
cv2.cornerHarris(src, blockSize, ksize, k, dst=None, borderType=None) -> dst- src : 입력 단일 채널 8비트 또는 실수형 영상
- blockSize : 코너 응답 함수 계산에서 고려할 이웃 픽셀 크기. 보통 2~5 [3 정도면 무난하게 사용 가능]
- ksize : [미분을 위한] 소벨 연산자를 위한 커널 크기. 보통 3
- k : 해리스 코너 검출 상수 [보통 0.04~0.06]
- dst : 해리스 코너 응답 계수. src와 같은 크기의 행렬
- borderType : 가장자리 픽셀 확장 방식. 기본값은 cv2.BORDER_DEFAULT
추적하기 좋은 특징 코너 검출
: goodFeaturesToTrack 함수의 경우 parameter가 9개나 된다. 이걸 외우기엔 정말 빡셀 것 같지만, 그 중 5개가 default 값이기 때문에 사실상 4개의 parameter만 정해주면 된다.
cv2.goodFeaturesToTrack(image, maxCorners, qualityLevel, minDistance, corners=None, mask=None,
blockSize=None, useHarrisDetector=None, k=None)-> corners- image : 8비트 또는 32비트 실수, 단일 채널 영상
- maxCorners : 최대 코너 개수. maxCorners ≤ 0이면 무제한
- qualityLevel : 코너점 결정을 위한 값. 보통 0.01 ~ 0.1
- minDistance : 코너점 사이의 최소 거리
- corners : 검출된 코너점 좌표 → 출력하려면 int type으로 전환한 뒤 출력해야 함 [기본형이 float32이기 때문]
- mask : 마스크 영상
- blockSize : 코너 검출을 위한 블록 크기. 기본값은 3
- useHarrisDetector : 해리스 코너 방법 사용 여부. 기본값은 False
- k : 해리스 코너 검출 시 사용할 k 값
FAST 코너 검출
cv2.FastFeatureDetector_create(, threshold=None, nonmaxSuppression=None, type=None) -> retval
cv2.FastFeatureDetector.detect(image) -> keypoints- threshold : 중심 픽셀 값과 주변 픽셀 값과의 차이 임계값. 기본 값은 10
[ex 16개 중 10개 이상의 픽셀이 기준점 P보다 밝으면 이 점 P를 Corner로 판단] … 30~60이 가장 이상적 - nonmaxSuppression : 비최대 억제 수행 여부. 기본 값은 True
- type : 코너 검출 방법. 기본값은 cv2.FAST_FEATURE_DETECTOR_TYPE_9_16
→ type은 변경하지 않는게 좋음 - retval : FastFeatureDetector 객체
- image : [입력] 그레이스케일 영상
- keypoints : [출력] 검출된 코너점 정보. cv2.KeyPoint 객체를 담은 리스트. cv2.KeyPoint의 pt 멤버를 이용하여 코너 좌표를 추출. pt[0]은 x좌표, pt[1]은 y좌표
예시 코드
GTFF와 FAST 코너 검출 예제
import sys
import numpy as np
import cv2
src = cv2.imread('building.jpg', cv2.IMREAD_GRAYSCALE)
if src is None:
print('Image load failed!')
sys.exit()
tm = cv2.TickMeter()
# GFTT
tm.start()
corners = cv2.goodFeaturesToTrack(src, 400, 0.01, 10)
tm.stop()
print('GFTT: {}ms.'.format(tm.getTimeMilli()))
dst1 = cv2.cvtColor(src, cv2.COLOR_GRAY2BGR)
# 코너 부분을 빨간색 원으로 표시
if corners is not None:
for i in range(corners.shape[0]):
pt = (int(corners[i, 0, 0]), int(corners[i, 0, 1]))
cv2.circle(dst1, pt, 5, (0, 0, 255), 2)
# FAST
tm.reset() # reset을 하지 않으면 위에서 측정한 시간이 추가됨
tm.start()
fast = cv2.FastFeatureDetector_create(60)
keypoints = fast.detect(src)
tm.stop()
print('FAST: {}ms.'.format(tm.getTimeMilli()))
dst2 = cv2.cvtColor(src, cv2.COLOR_GRAY2BGR)
for kp in keypoints:
pt = (int(kp.pt[0]), int(kp.pt[1])) # pt[0], pt[1]은 각각 x좌표, y좌표
cv2.circle(dst2, pt, 5, (0, 0, 255), 2)
cv2.imshow('src', src)
cv2.imshow('dst1', dst1)
cv2.imshow('dst2', dst2)
cv2.waitKey()
cv2.destroyAllWindows()
>>>
GFTT: 21.5232ms.
FAST: 0.5976ms
코너 검출 방법 성능 비교
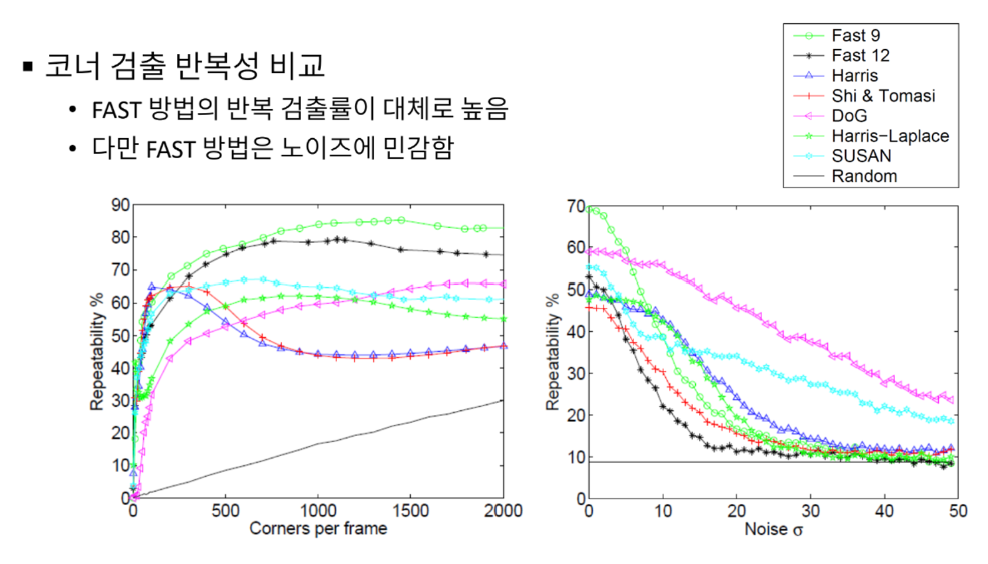
특징점 검출
Harris, GFTT, FAST 코너의 문제점
- 이동, 회전 변환에 강인
- 크기 변환에 취약
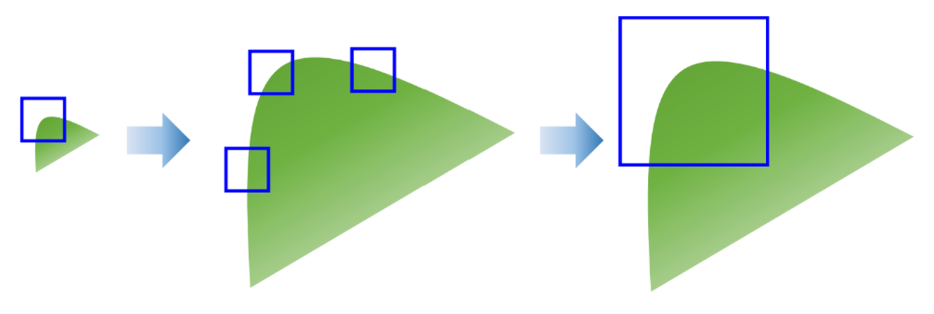
→ 다양한 크기 관점에서 특징을 검출할 필요가 있다.
- 특징점 [Feature Point] ~ 키포인트 ~ 관심점
- 기술자 [Descriptor] ~ feature vector
크기 불변 특징점 검출 방법
- SIFT, KAZE, AKAZE, ORB 등 다양한 특징점 검출 방법에서 스케일 스페이스, 이미지 피라미드를 구성하여 크기 불변 특징점을 검출

- OpenCV 특징점 검출 클래스 : Feature2D 클래스와 파생 클래스
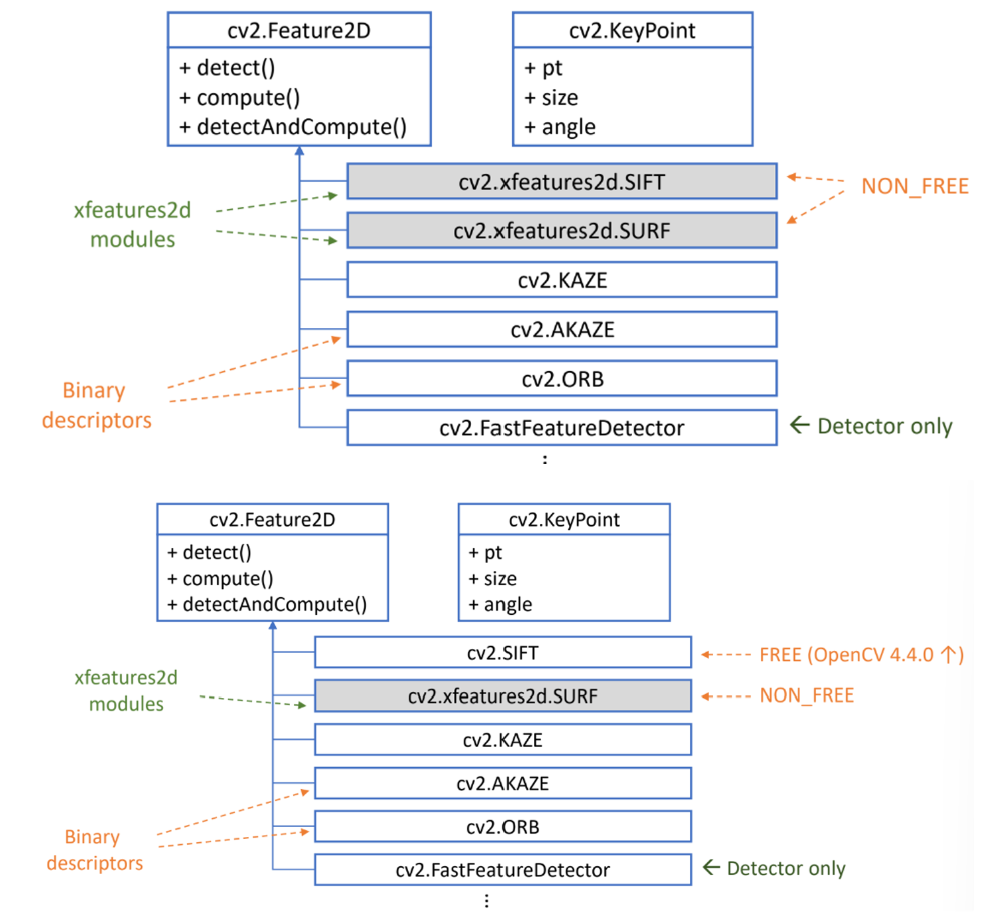
특징점 검출 알고리즘 객체 생성
cv2.SIFT_create(,...) -> retval
cv2.KAZE_create(,...) -> retval
cv2.AKAZE_create(,...) -> retval
cv2.ORB_create(,...) -> retval- retval : 각 특징점 검출 알고리즘 객체
- 참고사항
- 각각의 알고리즘은 고유한 파라미터를 인자로 받을 수 있음
- 대부분의 인자는 기본값을 가지고 있으므로 함수 인자 없이 호출 가능
특징점 검출 함수
cv2.Feature2D.detect(image, mask=None) -> keypoints- image : 입력 영상
- mask : 마스크 영상
- keypoints : 검출된 특징점 정보. cv2.KeyPoints 객체의 리스트
→ pt [x좌표, y좌표 float type], size, angle 정보 포함
검출된 특징점 그리기 함수
cv2.drawKeypoints(image, keypoints, outImage, color=None, flags=None) -> outImage- image : 입력 영상
- keypoints : 검출된 특징점 정보. cv2.KeyPoint 객체의 리스트
- outImage : 출력 영상
- color : 특징점 표현 색상. 기본값은 [-1,-1,-1,-1]이며 이 경우 임의의 색상으로 표현
- flags : 특징점 표현 방법

예시 코드
# keypoints.py
import sys
import numpy as np
import cv2
# 영상 불러오기
src1 = cv2.imread('graf1.png', cv2.IMREAD_GRAYSCALE)
src2 = cv2.imread('graf3.png', cv2.IMREAD_GRAYSCALE)
if src1 is None or src2 is None:
print('Image load failed!')
sys.exit()
# 특징점 알고리즘 객체 생성 (KAZE, AKAZE, ORB 등)
feature = cv2.KAZE_create()
# feature = cv2.AKAZE_create()
# feature = cv2.ORB_create()
# 특징점 검출
kp1 = feature.detect(src1)
kp2 = feature.detect(src2)
print('# of kp1:', len(kp1))
print('# of kp2:', len(kp2))
# 검출된 특징점 출력 영상 생성
dst1 = cv2.drawKeypoints(src1, kp1, None,
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
dst2 = cv2.drawKeypoints(src2, kp2, None,
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow('dst1', dst1)
cv2.imshow('dst2', dst2)
cv2.waitKey()
cv2.destroyAllWindows()
>>>
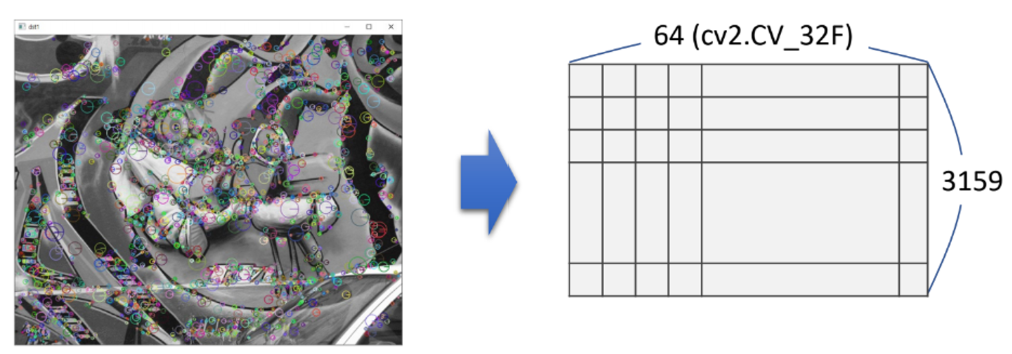
# of kp1: 3159
# of kp2: 3625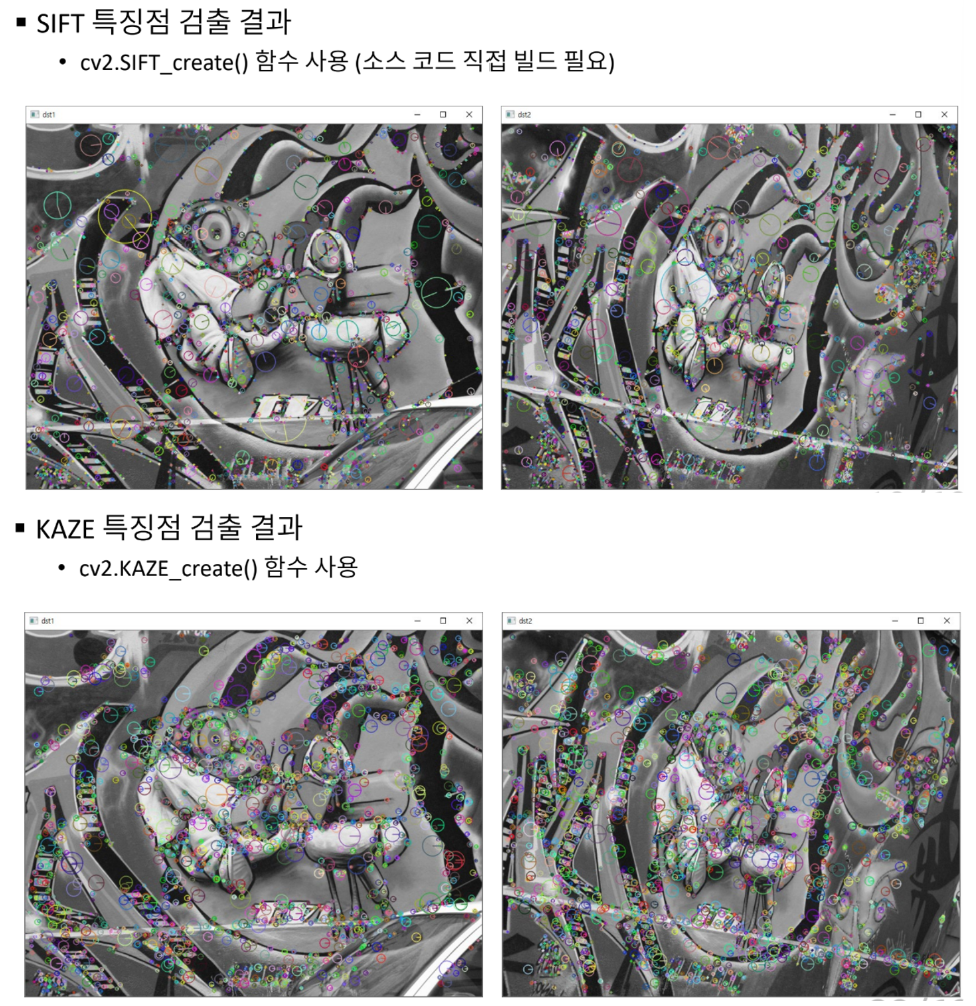
특징점 기술
기술자 [Descriptor, feature vector]
: 특징점 근방의 부분 영상을 표현하는 실수 또는 이진 벡터
- OpenCV에서는 2차원 행렬로 표현
실수 기술자
- 주로 특징점 부근 부분 영상의 방향 히스토그램을 사용
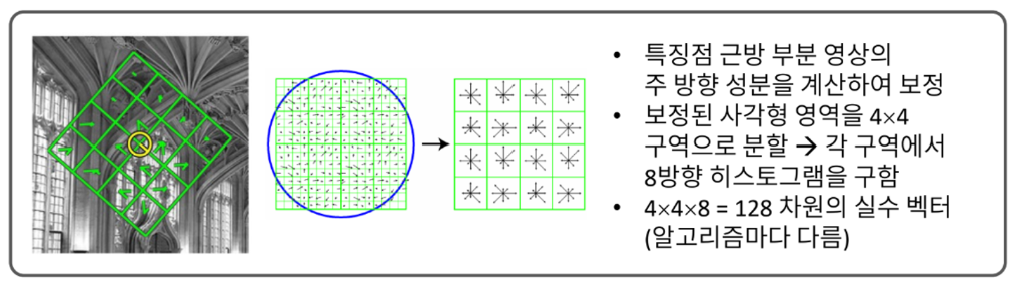
- 보통 numpy.float32 자료형을 사용하여 실수 정보를 저장하는 방식
- 실수 기술자를 사용하는 알고리즘 : SIFT, SURF, KAZE 등
- 실수 기술자는 보통 L2-Norm을 사용하여 유사도 판단
이진 기술자
- 이진 테스트를 이용하여 부분 영상의 특징을 기술

ex) 1과 2 비교 : 1이 더 밝기 때문에 1
2와 3 비교 : 2가 더 어둡기 때문에 0
1과 3 비교 : 1이 더 밝기 때문에 1
→ 따라서, 1,2,3이 겹치는 point P의 이진 정보는 101
- 보통 numpy.uint8 자료형을 사용하여 비트 단위로 영상 특징 정보를 저장하는 방식
- 이진 기술자를 사용하는 알고리즘 : AKAZE, ORB, BRIEF
- 이진 기술자는 해밍 거리를 사용하여 유사도를 판단
e.g.) d1=1011101, d2=1001001인 경우 해밍 거리는 2
함수
특징점 기술자 계산 함수
cv2.Feature2D.compute(image, keypoints, descriptors=None) ->keypoints, descriptors- image : 입력 영상
- mask : 마스크 영상
- keypoints : 검출된 특징점 정보. cv2.KeyPoint 객체의 리스트
- descriptors : 특징점 기술자 행렬
특징점 검출 및 기술자 계산 함수
cv2.Feature2D.detectAndCompute(image, mask=None, descriptors=None) -> keyPoints, descriptors- image : 입력 영상
- mask : 마스크 영상
- keypoints : 검출된 특징점 정보. cv2.KeyPoint 객체의 리스트
- descriptors : 특징점 기술자 행렬
예시 코드
import sys
import numpy as np
import cv2
# 영상 불러오기
src1 = cv2.imread('graf1.png', cv2.IMREAD_GRAYSCALE)
src2 = cv2.imread('graf3.png', cv2.IMREAD_GRAYSCALE)
if src1 is None or src2 is None:
print('Image load failed!')
sys.exit()
# 특징점 알고리즘 객체 생성 (KAZE, AKAZE, ORB 등)
# feature = cv2.SIFT_create()
feature = cv2.KAZE_create()
# feature = cv2.AKAZE_create()
# feature = cv2.ORB_create()
# 특징점 검출 및 기술자 계산
kp1 = feature.detect(src1)
_, desc1 = feature.compute(src1, kp1)
kp2, desc2 = feature.detectAndCompute(src2, None) # 위의 두 줄을 한꺼번에 연산
print('desc1.shape:', desc1.shape)
print('desc1.dtype:', desc1.dtype)
print('desc2.shape:', desc2.shape)
print('desc2.dtype:', desc2.dtype)
# 검출된 특징점 출력 영상 생성
dst1 = cv2.drawKeypoints(src1, kp1, None,
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
dst2 = cv2.drawKeypoints(src2, kp2, None,
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow('dst1', dst1)
cv2.imshow('dst2', dst2)
cv2.waitKey()
cv2.destroyAllWindows()
>>>
[KAZE]
desc1.shape: (3159, 64)
desc1.dtype: float32
desc2.shape: (3625, 64)
desc2.dtype: float32
[AKAZE]
desc1.shape: (2418, 61)
desc1.dtype: uint8
desc2.shape: (2884, 61)
desc2.dtype: uint8
# AKAZE의 column은 무조건 61개
[ORB]
desc1.shape: (500, 32)
desc1.dtype: uint8
desc2.shape: (500, 32)
desc2.dtype: uint8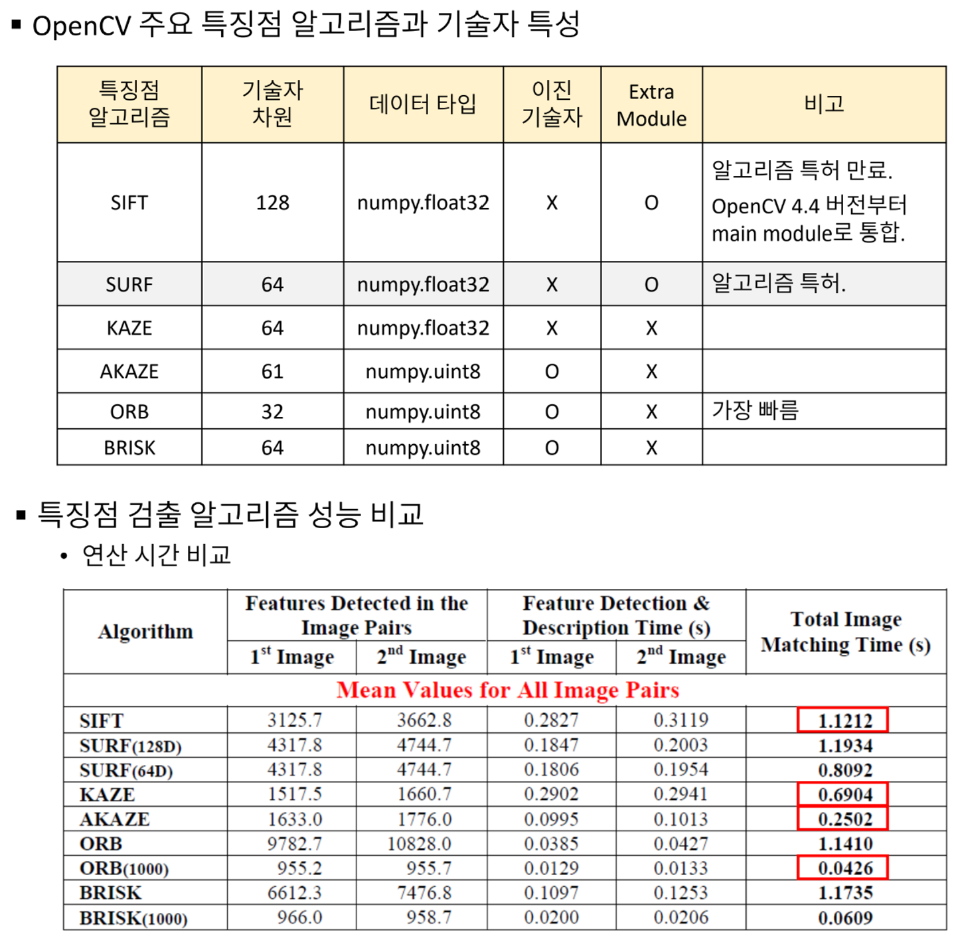
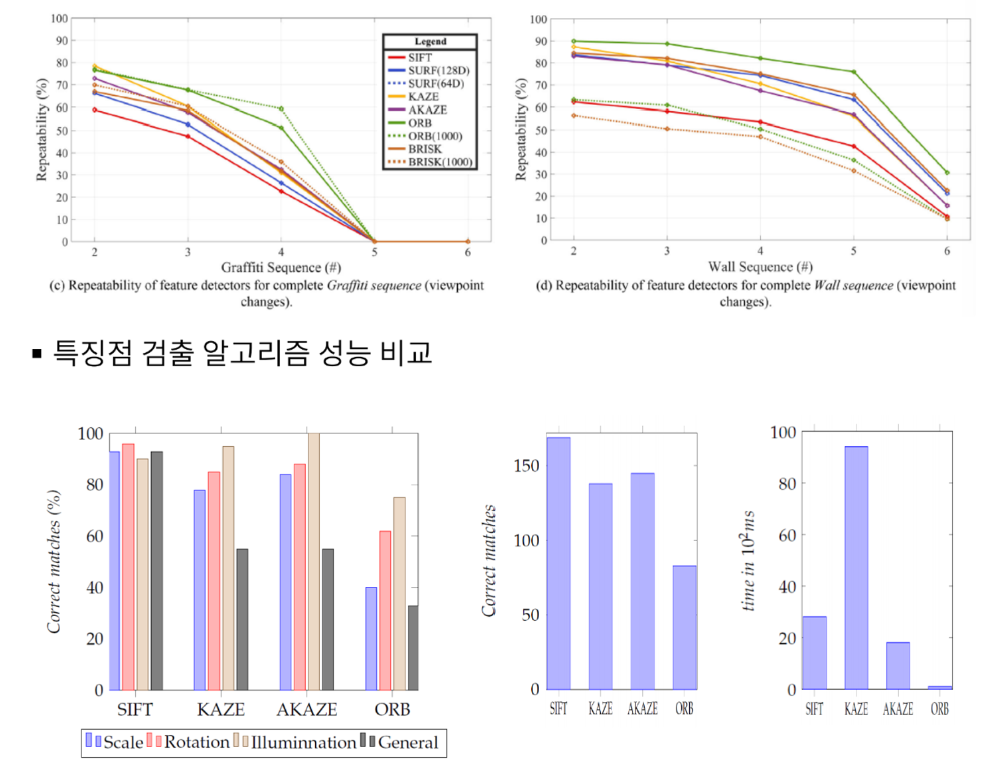
오른쪽 2개의 푸른색 막대 그래프를 보면, 왼쪽은 정확도에 관한 그래프이고, 오른쪽은 시간에 대한 그래프이다. 분석을 해보면 SIFT와 AKAZE의 정확도가 높고, 시간도 적게 걸린다는 것을 알 수 있다. 그에 반해 KAZE는 정확도는 높은 편이지만 시간이 오래걸리고, ORB는 시간은 거의 소모되지 않지만 정확도가 낮기 때문에 ORB, KAZE 보다는 SIFT나 AKAZE 알고리즘을 AKAZE보다는 SIFT 알고리즘을 사용하는 것이 조금 더 효율적인 성능을 보일 것으로 예상된다.
특징점 매칭
: 두 영상에서 추출한 특징점 기술자를 비교하여 서로 유사한 기술자 [descriptor]를 찾는 작업
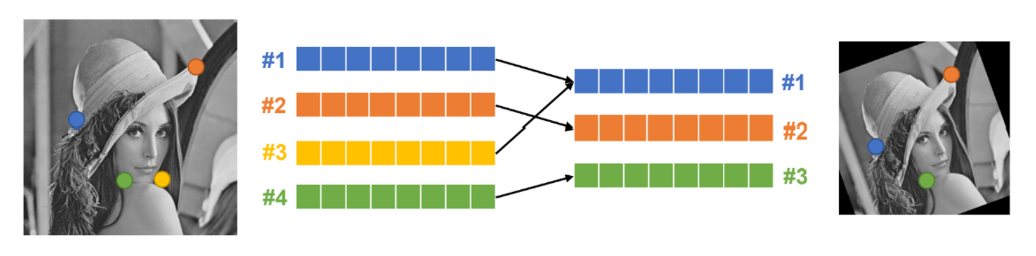
특징 벡터 유사도 측정 방법
- 이진 특징 벡터 : 해밍 거리 사용
- 실수 특징 벡터 : L2-Norm 사용
OpenCV 특징점 매칭 클래스
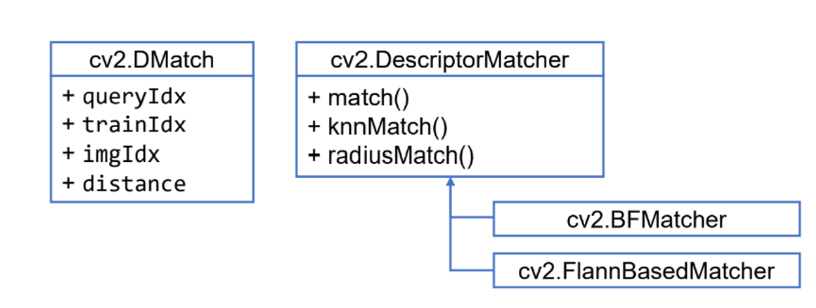
- BF : Brute-Force [전수 조사]
- Flann : Fast Library for Approximate Nearest Neighbor [K-D Tree 사용]
→ 근사화를 하였기 때문에 완전 정확한 값은 아니지만, 연산 속도가 빠르다.
특징점 매칭 알고리즘 객체 생성
cv2.BFMatcher_create(, normType=None, crossCheck=None) -> retval- normType : 특징점 기술자 거리 계산 방식 지정. 기본값은 cv2.NORM_L2
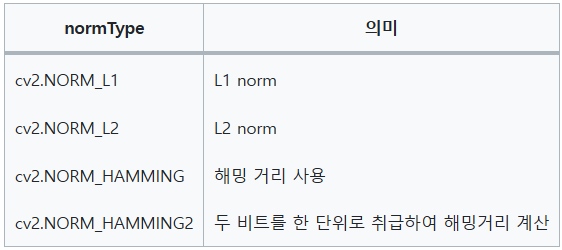
- crossCheck : 이 값이 True이면 양방향 매칭 결과가 같은 경우만 반환. 기본값은 False
특징점 검출 알고리즘 객체 생성
cv2.DescriptorMatcher.match(queryDescriptors, trainDescriptors, mask=None) -> matches- queryDescriptors : [기준 영상 특징점] 질의 기술자 행렬
- trainDescriptors : [대칭 영상 특징점] 학습 기술자 행렬
- mask : 매칭 진행 여부를 지정하는 행렬 마스크
- matches : 매칭 결과. cv2.DMatch 객체의 리스트
cv2.DescriptorMatcher.match(queryDescriptors, trainDescriptors, k, mask=None, compactResult=None)
-> matches- queryDescriptors : [기준 영상 특징점] 질의 기술자 행렬
- trainDescriptors : [대칭 영상 특징점] 학습 기술자 행렬
- k : 질의 기술자에 대해 검출할 매칭 개수
- mask : 매칭 진행 여부를 지정하는 행렬 마스크
- compactResult : mask가 None이 아닐 때 사용되는 파라미터. 기본값은 False이며, 이 경우 결과 matches는 기준 영상 특징점과 같은 크기를 가짐
- matches : 매칭 결과. cv2.DMatch 객체의 리스트
특징점 매칭 결과 영상 생성
cv2.drawMatches(img1, keypoints1, img2, keypoints2, matches1to2, outImg, matchColor=None, singlePointColor=None,
matchesMask=None, flags=None) -> outImg- img1, keypoints1 : 기준 영상과 기준 영상에서 추출한 특징점 정보
- img2, keypoints2 : 대상 영상과 대상 영상에서 추출한 특징점 정보
- matches1to2 : 매칭 정보. cv2.DMatch의 리스트
- outImg : 출력 영상 → None 지정
- matchColor : 매칭된 특징점과 직선 색상 → None 지정하면 Random 색상으로 출력
- singlePointColor : 매칭되지 않은 특징점 색상
- matchesMask : 매칭 정보를 선택하여 그릴 때 사용할 마스크
- flags : 매칭 정보 그리기 방법. 기본값은 cv2.DRAW_MATCHES_FLAGS_DEFAULT
예시 코드
# matching.py
import sys
import numpy as np
import cv2
# 영상 불러오기
src1 = cv2.imread('graf1.png', cv2.IMREAD_GRAYSCALE)
src2 = cv2.imread('graf3.png', cv2.IMREAD_GRAYSCALE)
if src1 is None or src2 is None:
print('Image load failed!')
sys.exit()
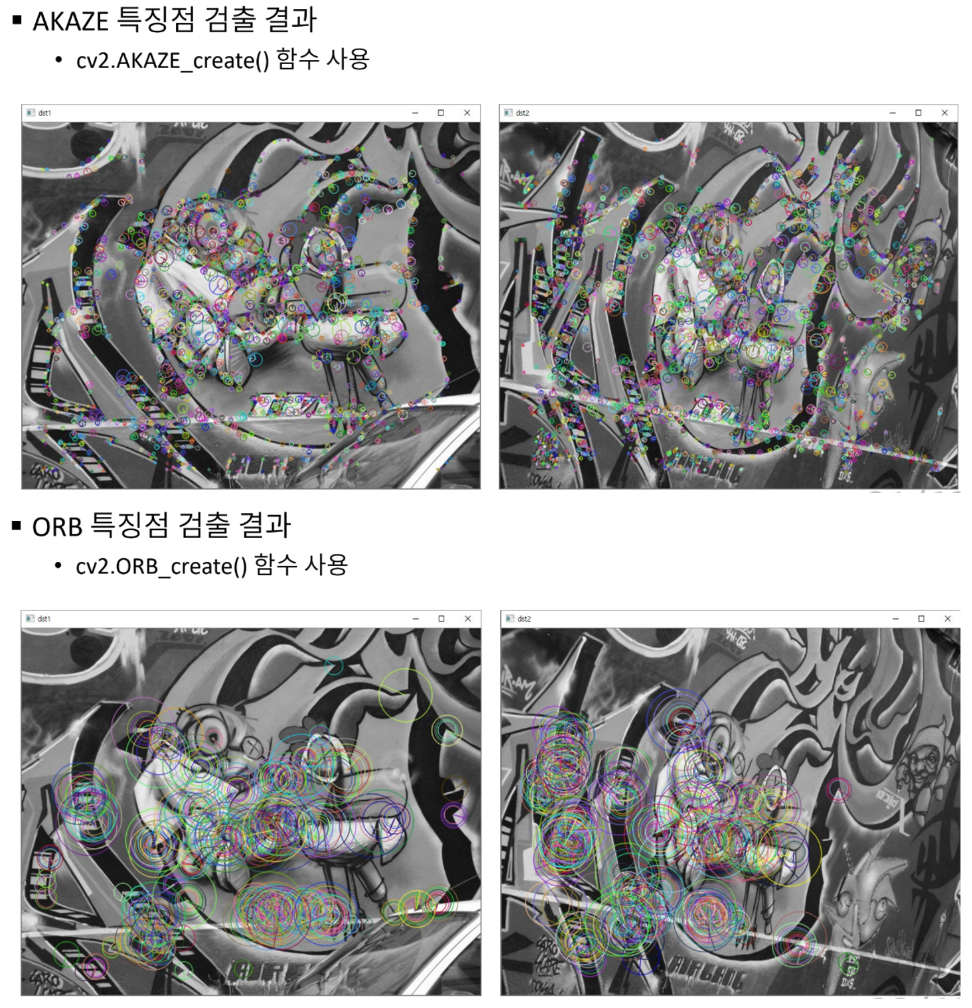
# 특징점 알고리즘 객체 생성 (KAZE, AKAZE, ORB 등)
feature = cv2.KAZE_create()
# feature = cv2.AKAZE_create()
# feature = cv2.ORB_create()
# 특징점 검출 및 기술자 계산
kp1, desc1 = feature.detectAndCompute(src1, None)
kp2, desc2 = feature.detectAndCompute(src2, None)
# 특징점 매칭
matcher = cv2.BFMatcher_create()
#matcher = cv2.BFMatcher_create(cv2.NORM_HAMMING)
matches = matcher.match(desc1, desc2)
print('# of kp1:', len(kp1))
print('# of kp2:', len(kp2))
print('# of matches:', len(matches))
# 특징점 매칭 결과 영상 생성
dst = cv2.drawMatches(src1, kp1, src2, kp2, matches, None)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
>>>
# of kp1: 3159
# of kp2: 3625
# of matches: 3159
좋은 매칭 선별
좋은 매칭 선별 방법 #1
: 위에서 특징점 매칭 결과를 보면 알겠지만, 모든 점들을 이었기 때문에 원본 영상이 안보일 뿐더러 어떤점이 매칭이 되었는지 확인하기가 매우 힘들다. 따라서 좋은 매칭 선별 방법을 사용해서 매칭들 중 일부만 매칭해서 특징점을 선별한다.
- 가장 좋은 매칭 결과에서 distance 값이 작은 것 N개를 사용
- cv2.DMatch.distance 값을 기준으로 정렬 후 상위 N개 선택
import sys
import numpy as np
import cv2
# 영상 불러오기
src1 = cv2.imread('graf1.png', cv2.IMREAD_GRAYSCALE)
src2 = cv2.imread('graf3.png', cv2.IMREAD_GRAYSCALE)
if src1 is None or src2 is None:
print('Image load failed!')
sys.exit()
# 특징점 알고리즘 객체 생성 (KAZE, AKAZE, ORB 등)
feature = cv2.KAZE_create()
# feature = cv2.AKAZE_create()
# feature = cv2.ORB_create()
# 특징점 검출 및 기술자 계산
kp1, desc1 = feature.detectAndCompute(src1, None)
kp2, desc2 = feature.detectAndCompute(src2, None)
# 특징점 매칭
matcher = cv2.BFMatcher_create()
#matcher = cv2.BFMatcher_create(cv2.NORM_HAMMING)
matches = matcher.match(desc1, desc2)
# 좋은 매칭 결과 선별
matches = sorted(matches, key=lambda x: x.distance)
good_matches = matches[:80]
print('# of kp1:', len(kp1))
print('# of kp2:', len(kp2))
print('# of matches:', len(matches))
print('# of good_matches:', len(good_matches))
# 특징점 매칭 결과 영상 생성
dst = cv2.drawMatches(src1, kp1, src2, kp2, good_matches, None)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
>>>
# of kp1: 3159
# of kp2: 3625
# of matches: 3159
# of good_matches: 80
좋은 매칭 선별 방법 #2
- 가장 좋은 매칭 결과의 distance 값과 두 번째로 좋은 매칭 결과의 distance 값의 비율을 계산
- 이 비율이 임계값보다 작으면 선택

import sys
import numpy as np
import cv2
# 영상 불러오기
src1 = cv2.imread('graf1.png', cv2.IMREAD_GRAYSCALE)
src2 = cv2.imread('graf3.png', cv2.IMREAD_GRAYSCALE)
if src1 is None or src2 is None:
print('Image load failed!')
sys.exit()
# 특징점 알고리즘 객체 생성 (KAZE, AKAZE, ORB 등)
feature = cv2.KAZE_create()
#feature = cv2.AKAZE_create()
#feature = cv2.ORB_create()
# 특징점 검출 및 기술자 계산
kp1, desc1 = feature.detectAndCompute(src1, None)
kp2, desc2 = feature.detectAndCompute(src2, None)
# 특징점 매칭
matcher = cv2.BFMatcher_create()
#matcher = cv2.BFMatcher_create(cv2.NORM_HAMMING)
matches = matcher.knnMatch(desc1, desc2, 2)
# 좋은 매칭 결과 선별
good_matches = []
for m in matches:
if m[0].distance / m[1].distance < 0.7:
good_matches.append(m[0])
print('# of kp1:', len(kp1))
print('# of kp2:', len(kp2))
print('# of matches:', len(matches))
print('# of good_matches:', len(good_matches))
# 특징점 매칭 결과 영상 생성
dst = cv2.drawMatches(src1, kp1, src2, kp2, good_matches, None)
cv2.namedWindow('dst', cv2.WINDOW_NORMAL)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
호모그래피와 영상 매칭
: 두 평면 사이의 투시 변환 [Perspective transform]
- 8DOF ... 최소 4개의 대응점 좌표가 필요하다
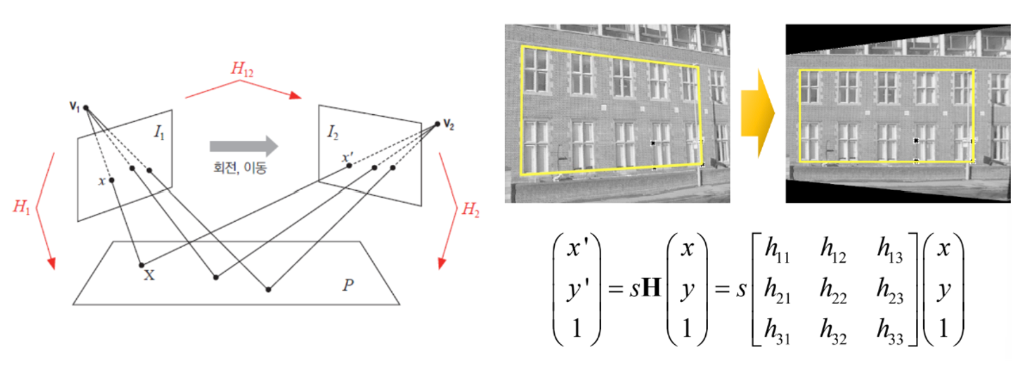
호모그래피 계산 함수
cv2.findHomography(srcPoints, dstPoints, method=None, ransacReprojThreshold=None, mask=None, maxIters=None,
confidence=NOne) -> retval, mask- srcPoints : 입력 점 좌표
- dstPoints : 결과 점 좌표
- method : 호모그래피 행렬 계산 방법. 0, LMEDS, RANSAC, RHO 중 선택. 기본값은 0이며, 이상치가 있을 경우 RANSAC, RHO 방법 권장 [cv2.RANSAC]
- ransacReprojThreshold : RANSAC 재투영 에러 허용치. 기본값은 3
RANSAC : RANdom SAmple Consensus
= 이상치 [Outlier]가 많은 원본 데이터로부터 모델 파라미터를 예측하는 방법
- maxIters : RANSAC 최대 반복 횟수. 기본값은 2000
- retval : 호모그래피 행렬
- mask : 출력 마스크 행렬. RANSAC, RHO 방법 사용시 Inlier로 사용된 점들을 1로 표시한 행렬
예시 코드
# homography.py
import sys
import numpy as np
import cv2
# Load two images to be used for homography
src1 = cv2.imread('box.png', cv2.IMREAD_GRAYSCALE)
src2 = cv2.imread('box_in_scene.png', cv2.IMREAD_GRAYSCALE)
# Check if images are loaded successfully
if src1 is None or src2 is None:
print('Image load failed!')
sys.exit()
# Create a feature point algorithm object (KAZE, AKAZE, ORB, etc.)
feature = cv2.KAZE_create()
# Alternatively, you can use AKAZE or ORB instead of KAZE
# feature = cv2.AKAZE_create()
# feature = cv2.ORB_create()
# Detect feature points and calculate descriptors for each image
kp1, desc1 = feature.detectAndCompute(src1, None)
kp2, desc2 = feature.detectAndCompute(src2, None)
# Use a feature point matcher (Brute-Force Matcher) to find matches between descriptors
matcher = cv2.BFMatcher_create()
matches = matcher.match(desc1, desc2)
# Sort matches based on their distances and select the top 80 matches
matches = sorted(matches, key=lambda x: x.distance)
good_matches = matches[:80]
# Print information about the number of feature points and matches
print('# of kp1:', len(kp1))
print('# of kp2:', len(kp2))
print('# of matches:', len(matches))
print('# of good_matches:', len(good_matches))
# Extract coordinates of feature points from the good matches
pts1 = np.array([kp1[m.queryIdx].pt for m in good_matches]).reshape(-1, 1, 2).astype(np.float32)
pts2 = np.array([kp2[m.trainIdx].pt for m in good_matches]).reshape(-1, 1, 2).astype(np.float32)
# Calculate homography matrix using RANSAC
H, _ = cv2.findHomography(pts1, pts2, cv2.RANSAC)
# Display matching results and draw the reference image area using homography
dst = cv2.drawMatches(src1, kp1, src2, kp2, good_matches, None,
flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
# Get the dimensions of the reference image
(h, w) = src1.shape[:2]
# Define the four corners of the reference image
corners1 = np.array([[0, 0], [0, h-1], [w-1, h-1], [w-1, 0]]).reshape(-1, 1, 2).astype(np.float32)
# Transform the corners using the calculated homography matrix
corners2 = cv2.perspectiveTransform(corners1, H)
# Shift the transformed corners to match the second image
corners2 = corners2 + np.float32([w, 0])
# Draw the polygon representing the reference image area in the second image
cv2.polylines(dst, [np.int32(corners2)], True, (0, 255, 0), 2, cv2.LINE_AA)
# Display the result
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()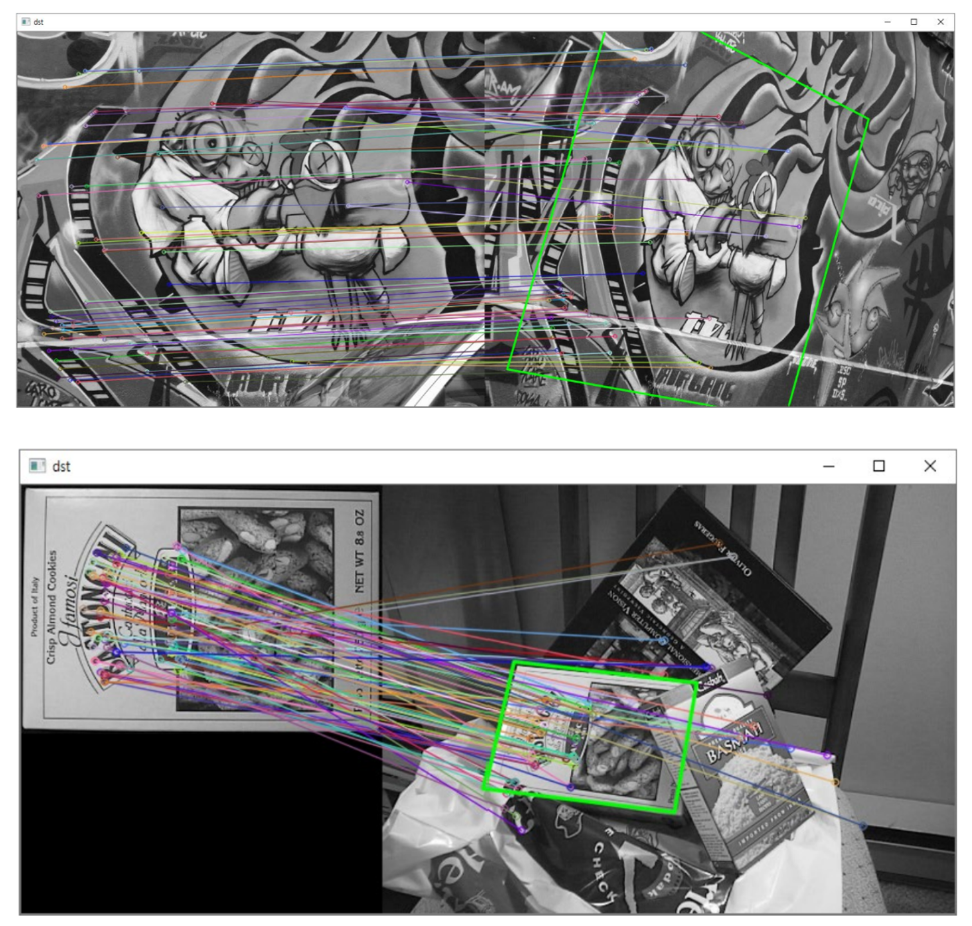
이미지 스티칭
: 동일 장면의 사진을 자연스럽게 붙여서 한 장의 사진으로 만드는 기술

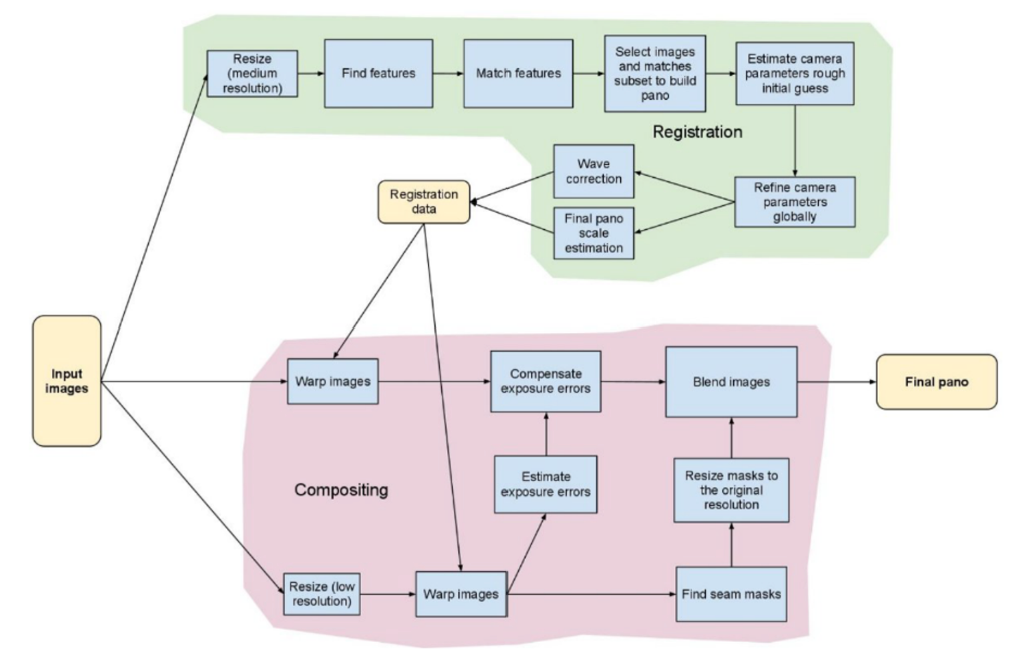
이미지 스티칭 객체 생성
cv2.Stitcher_create(, mode=None) -> retval- mode : 스티칭 모드. cv2.PANORAMA 또는 cv2.SCANS 중 하나 선택. 기본값은 cv2.PANORAMA
- retval : cv2.Stitcher 클래스 객체
이미지 스티칭 함수
cv2.Stitcher.stitch(images, pano=None) -? retval, pano- images : 입력 영상 리스트
- retval : 성공하면 cv2.Stitcher_OK
- pano : 파노라마 영상
예시 코드
# stitching.py
import sys
import numpy as np
import cv2
img_names = ['img1.jpg', 'img2.jpg', 'img3.jpg']
imgs = []
for name in img_names:
img = cv2.imread(name)
if img is None:
print('Image load failed!')
sys.exit()
imgs.append(img)
stitcher = cv2.Stitcher_create()
status, dst = stitcher.stitch(imgs)
if status != cv2.Stitcher_OK:
print('Stitch failed!')
sys.exit()
cv2.imwrite('output.jpg', dst)
cv2.namedWindow('dst', cv2.WINDOW_NORMAL) # 창 크기 조절
for i in range(3):
cv2.imshow('img{}'.format(i+1),imgs[i])
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
OpenCV 끝!!


'OpenCV' 카테고리의 다른 글
| [OpenCV] 영상 분할과 객체 검출 (0) | 2025.04.04 |
|---|---|
| [OpenCV] 이진 영상 처리 (0) | 2025.04.04 |
| [OpenCV] 영상의 특징 추출 (0) | 2025.04.04 |
| [OpenCV] 기하학적 변환 (0) | 2025.04.04 |
| [OpenCV] 필터링 (1) | 2025.04.04 |