
Champ: Controllable and Consistent Human Image Animation with 3D Parametric Guidance
In this study, we introduce a methodology for human image animation by leveraging a 3D human parametric model within a latent diffusion framework to enhance shape alignment and motion guidance in curernt human generative techniques. The methodology utilize
arxiv.org
Champ
fudan-generative-vision.github.io
Abstract
We introduce a methodology for human image animation by leveraging a 3D human parametric model within a latent diffusion framework to enchance shape alignment and motion guidance in current human generative techniques.
이 논문에서는 SMPL [Skinned Multi-Person Linear Model]을 3D human parametric model로 사용해서 body shape와 pose의 unified representation을 만들고자 하였고, 결과적으로 source video에서 복잡한 human geometry, motion characteristic들을 정확하게 포착할 수 있게 되었다.
구체적으로, SMPL sequence로 부터 얻은 rendered depth image, normal map, semantic map과 skeleton-based motion guidance를 합쳐서 3D shape와 detail한 pose의 특성에 대한 condition을 latent diffusion에 부여하려고 하였다고 한다. Multi-layer motion fusion module과 self-attention mechanism이 합쳐져서 spatial domain에서 shape와 motion latent representation을 fuse 할 수 있었다.
3D human parametric model을 motion guidance로 보여줌으로써 reference image와 source video motion 사이의 human body alignment를 수행할 수 있었다고 한다.
Our approach exhibits superior generalization capabilities on the proposed in-the-wild dataset
Introduction

최근의 latent diffusion model의 발전은 image animation forward 분야를 상당히 촉진시켰다.
Human image animation 분야에서의 기법들은 주로 reference image와 skeleton, semantic map, dense motion flow 같은 human에 특정된 motion guidance에 의존을 해서 controllable한 human animation video를 생성한다.
이 분야에서는 우세한 접근법들이 존재하는데, GAN을 사용하는 방법과 diffusion을 사용하는 방법 2가지로 나뉜다.
- GAN-based method는 주로 warping function을 사용해서 sequential video frame들을 생성하기 위해 input motion에 따라 reference image를 공간적으로 변환한다. 내제적인 GAN의 generative visual capability를 leveraging 함으로써 이 분야는 놓친 영역을 채우고 생성된 결과물의 그럴듯하지 못한 영역을 시각적으로 향상시키는 것을 목표로 한다.
하지만, 훌륭한 결과물을 만들어냄에도 불구하고 GAN-based 접근법은 reference image와 source video motion 사이의 scene dynamic과 human identity의 잠재적인 variation 같은 시나리오에서 motion으로의 효과적인 변환에 어려움을 겪는다. 이렇게 되면 unrealistic visual artifact와 temporal inconsistency 같은 결과물이 생기게 된다는 단점이 존재한다. - 동시에, diffusion-based method는 appearance와 motion level에서 reference image와 다양한 dynamic들을 결합한다. Condition guidance와 latent diffusion model을 결합하여 이용함으로써 이러한 기법들은 직접적으로 human animation video를 생성할 수 있게 촉진해준다. 최근의 diffusion model들은 data-driven 전략에 기반을 두고 있는데, reference image에서 뽑아낸 CLIP-encoded visual feature와 diffusion model, temporal alignment module의 결합으로 GAN-based approach의 generalization challenge를 해결했다.
- 그래서 Animate Anyone, MagieAnimate 같은 이전 연구들에 이어서 이 논문에서는 shape alignment와 pose guidance mechanism을 더욱 더 최적화하는 것을 목표로 했다고 한다.
Sequential skeleton이나 dense pose data를 통해 reference image와 pose guidance를 연동하여 사용하는 것은 pose alignment와 motion guidance에 대해 limitation을 제공할 수도 있다고 한다. 후속 단계에서 SMPL 같은 3D parametric human model을 사용하여 reference image의 3D geometry를 encoding하고 source video에서 human motion을 뽑아낸다.
- body shape와 pose를 분리해서 표현하는 기존 방식들에서 벗어나서 SMPL model은 저차원 parameter space를 사용해서 shape와 pose variation을 포괄하는 통합된 representation을 제공한다. 결과적으로 pose information과 더불어서 SMPL model은 human-geometry-related surface deformation, spatial relationship, contour, 그리고 기타 shape-related feature들에 대해 guidance를 제공한다.
- SMPL model의 parametric한 특성으로 인해 reference image에서 복원한 SMPL과 source video에서 뽑아낸 SMPL-based motion sequence 사이에서 geometric correspondence를 형성할 수 있게 되었다. 이를 통해 parametric SMPL-based motion sequence를 조정할 수 있게 해주어서 latent diffusion model에서의 motion, geometric shape condition을 향상할 수 있게 되었다.
SMPL이 서로 다른 body shape에 대해서도 일반화 능력이 높기 때문에 효과적으로 reference image와 source video 사이에서 body shape의 잠재적인 variation을 효율적으로 다룰 수 있다.
Incorporating the SMPL model as a guiding framework for both shape and pose within a latent diffusion model, our methodology is structured around three fundamental components.
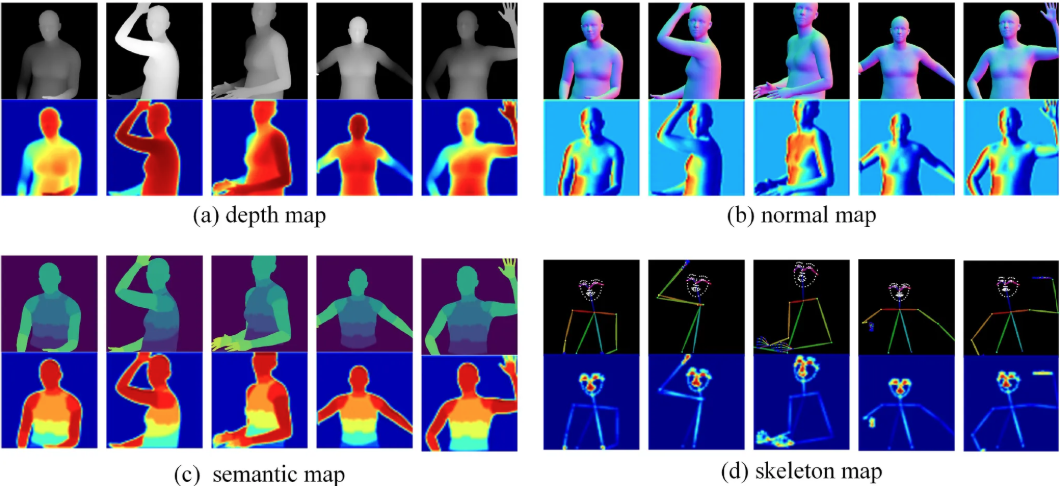
1. The sequence derived from the SMPL model corresponding to the source video are projected onto the image space, resulting in the generation of depth images, normal maps, and semantic maps that encapsulate essential 3D information.
2. Our analysis demonstrates that incorporating skeleton-based motion guidance enhances the precision of guidance information, particularly for intricate movements such as facial expressions and finger movements
→ Skeleton is maintained as an auxiliary input to complement the aforementioned maps
3. In the process of incorporating depth, normal, semantic and skeleton maps through feature encoding, the employment of self-attention mechanisms facilitates the feature maps, processed via self-attention, in learning the representative saliency regions within their respective layers.
Such multi-layer semantic fusion enhances the model’s capability to comprehend and generate human postures and shapes
4. The inclusion of these multi-layer feature embeddings conditioned on a latent video diffusion model leads to precise image animation both in pose and shape
- Depth map : 인간의 3D structure를 포착
- Normal map : 인간 신체의 orientation
- Semantic map : Animation 생성 동안 서로 다른 신체 부위의 interaction을 정확하게 다루도록함
Method
Input human image와 motion sequence를 묘사하는 reference video가 있을 때, 목표는 image에 있는 사람이 driving video에 있는 모션을 보고 따라하는 video를 합성해서 controllable하고 temporally coherent한 visual output을 생성하는 것이다.
Preliminary
Latent Diffusion Models
SMPL model
This model is structured around a paraametric shape space that effectively captures the nuanced variations in body shape exhibited among individuals, alongside a pose space that intricately encodes the articulation of the human body

Multi-Layer Motion Condition
SMPL to Guidance Condition

Parametric Shape Alignment

Multi-Layer Motion Guidance
Parametric shape alignment를 이용해서 reference image에 기반해서 복원된 SMPL model과 source video의 SMPL model sequence 사이의 shape-level alignment가 끝났다면 그 뒤에 이어 depth map, normal map, semantic map들이 aligned SMPL model sequence로 부터 rendering 된다.
추가적으로, skeleton이 얼굴 표정이나 손가락 움직임 등 복잡한 movement의 표현력을 향상시키기 위해 제안되었다.
Guidance Self-Attention
ControlNet이 주로 guidance를 고려해서 생성된 action을 제어하는데 사용된다. 하지만, 여러개의 guidance를 ControlNet에 제공하는 것은 computational burden으로 작용할 수 있다.
그래서 multilevel guidance를 encoding 하기위해 설계된 guidance encoder를 제안했다. 이 접근법을 통해 pre-trained denoising U-Net을 fine-tuning 하면서 guidance로 부터 동시에 information을 뽑아낼 수 있게 되었다. Encoder는 lightweight network의 series로 구성이 되어있다. 그리고 guidance network를 feature를 encoding 하기 위해 guidance condition으로 할다을 하였다고 한다. 각각의 guidance network에 대해 먼저 convolution layer들의 집합을 통해 guidance condition의 feature를 뽑아낸다. 사람 신체의 서로 다른 특성들을 포함하는 Multilevel guidance condition의 존재를 고려할 때, self-attention module은 convolutional layer 이후에 적용이 된다. 이 모듈의 경우 각각의 multi-layer guidance condition에서 대응하는 semantic information을 정확하게 포착하도록 해준다.
- The depth condition predominantly focuses on the geometric contours of the human figure
- The normal condition emphasizes the orientation of the human body
- The semantic condition prioritizes the semantic information of different body parts
- The skeleton attention provides detailed constraints of the face and hands
Multi-Layer Motion Fusion
Pre-trained denoising U-Net model의 integrity를 보존하기 위해 zero-initializtion을 갖는 convolutional layer를 output layer로 사용해서 사용해서 각각의 guidance condition의 feature들을 뽑아냈다고 한다.
Guidance encoder는 summation으로 feature embedding들을 모아서 모든 guidance condition으로 부터 병합을 하여 y로 표현되는 ultimate guidance feature를 얻는다.

뒤이어서 guidance feature는 denoising fusion module로 들어가기 전에 noisy latent representation과 결합되게 된다.
Network
Network Structure
Our approach introduces a video diffusion model that incorporates motion guidance derived from 3D human parametric models
구체적으로 SMPL model을 사용해서 motion data로 부터 SMPL pose sequence를 뽑아냈다. 이 전환 결과는 2D와 3D characteristics를 encapsulate하는 결과를 낳는다. 그럼으로써 model의 human shape, pose에 대한 이해도가 향상되게 된다. 이 guidance를 효율적으로 결합하기 위해 motion-embedding module을 제안해서 multilayer guidance를 model과 결합했다. 여러 개의 motion guidance의 latent embedding들은 self-attention mechansm을 통해 개별적으로 refine되고 multi-layer fusion module에 의해 한꺼번에 fuse된다.
더하여 reference image를 VAE encoder와 CLIP image encoder를 이용해서 encoding을 했다고 한다. Video consistency를 보장하기 위해 2가지 모듈을 사용했다고 한다.
- ReferenceNet
: VAE embedding은 ReferenceNet으로 들어가서 생성된 video와 reference image에서의 character와 background 사이의 consistency를 유지시켜준다. - Temporal alignment module
: Motion module의 series를 사용해서 frame들끼리의 temporal attention을 적용한다. 이 과정을 통해 reference image와 motion guidance 사이의 어떠한 차이도 존재하지 않게 최소화하고 생성된 video 내용의 전체적인 coherence를 향상시킨다.
Training
Training 과정은 2개의 stage로 구성이 된다. Initial stage 동안, training은 image에 대해서만 진행이 되고 model에서의 motion module은 배제시킨다. VAE encoder와 decoder의 weight는 freeze 시키고 CLIP의 image encoder도 똑같이 적용을 했다고 한다. Frozen state에서 Guidance Encoder, Denoising U-Net, Reference encoder가 training 동안 update 되는 것은 허용했다고 한다.
이 단계를 시작하기 위해 human video에서 무작위로 frame을 reference로 주기 위해 선택하고 같은 video에서 또 다른 image를 선택해서 target image로 적용한다. Target image로 부터 뽑아낸 multi-level guidance는 Guidance Network로 들어가게 된다.
이 단계의 최종 목적은 고퀄리티의 animated image를 특정 target image로 부터 유도된 multilevel guidance를 활용해서 생성하는 것이다.
두번째 training phase에서 motion module을 결합하는 것은 model의 temporal coherence와 fluidity를 보강해준다. 이 모듈은 AnimateDiff에서 얻은 기존의 weight로 초기화 된다. 24개의 frame으로 구성된 video segment는 input data로 사용되며 motion module을 학습시키는 동안 이전에 학습되었던 Guidance Encoder, Denoising U-Net, reference encoder는 constant 상태로 유지한다고 한다.
Inference
Inference process 동안 animation은 in-the-wild video에 합성된 video에서 뽑아낸 motion sequence들에 aligning 시킴으로써 특정 reference image에 대해 수행된다.
Parametric shape alignment는 pixel level로 reference image에서 유도된 복원된 SMPL model과 motion sequence를 align 시키기 위해 사용되며 animation의 기저를 제공한다.
24 frame으로 구성된 video clip input을 모으기 위해 temporal aggregation technique은 여러 clip들을 병합하기 위해 사용된다. 이 aggregation method는 긴 video output을 생성하게 된다.
Experiments
Implementations
Dataset
Dataset은 다음과 같이 구성되어 있다고 한다.
- Bilibili [2540 videos]
- Kuaishou [920 videos]
- Tiktok & Youtude [1438 videos]
- Xiaohongshu [430 videos]
이 비디오는 다양한 인종, 나이, 성별과 함께 전신, 반신, 클로즈업, 실내/실외 등 다양한 variation들이 존재한다.
In order to enhance our model’s capacity to analyze a wide range of human movements and attire, we have included footage of dancers showcasing various dance forms in divers clothing styles
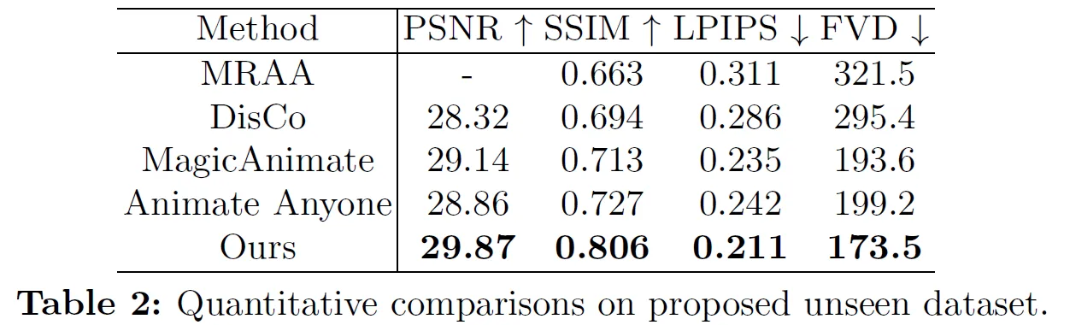
Comparison
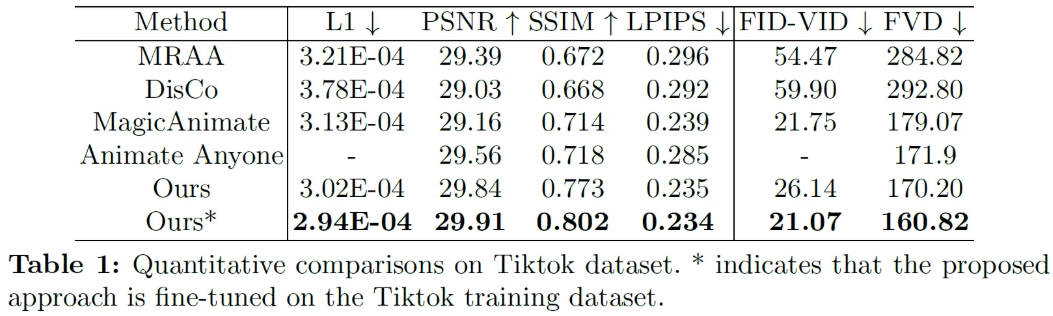


Unseen dataset


Cross ID animation

Multi-view Animation

Shape Variance Data

Evaluation Metrics
- L1 error
- SSIM [Structural Similarity Index]
- LPIPS [Learned Perceptual Image Patch Similarity]
- PSNR [Peak Signal-to-Noise Ratio]
- FID-FVD [Frechet Inception Distance with Frechet Video Distance]
- FVD [Frechet Video Distance]
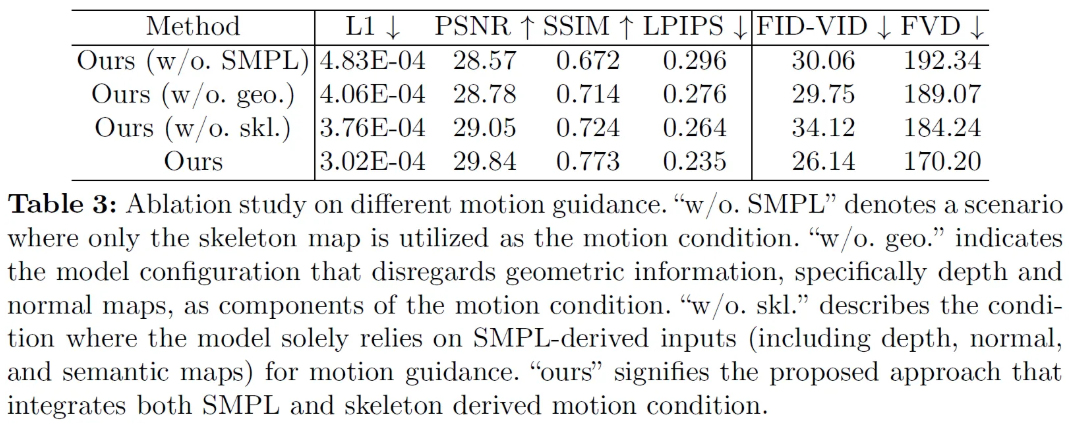
Ablation Study




Conclusion
This paper introduces a novel approach to human image animation that integrates the SMPL 3D parametric human model with latent diffusion models, aiming to enhance pose alignment and motion guidance
GitHub - fudan-generative-vision/champ: Champ: Controllable and Consistent Human Image Animation with 3D Parametric Guidance
Champ: Controllable and Consistent Human Image Animation with 3D Parametric Guidance - fudan-generative-vision/champ
github.com
실제 코드를 통해 Reference Image를 input으로 넣고 돌려보면 아래와 같은 결과물을 얻을 수 있다.
